GAT-NeRF: Geometry-Aware-Transformer Enhanced Neural Radiance Fields for High-Fidelity 4D Facial Avatars
作者: Zhe Chang, Haodong Jin, Ying Sun, Yan Song, Hui Yu
分类: cs.CV, cs.AI
发布日期: 2026-01-21
💡 一句话要点
提出GAT-NeRF,通过几何感知Transformer增强NeRF,实现高保真4D面部Avatar重建。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经辐射场 NeRF Transformer 4D面部Avatar 人脸重建 几何感知 动态人脸 单目视频
📋 核心要点
- 单目视频重建高保真动态面部Avatar极具挑战,现有NeRF方法难以捕捉面部动态皱纹等高频细节。
- GAT-NeRF融合几何先验信息,利用Geometry-Aware Transformer学习精细几何特征,增强NeRF对局部面部模式的建模能力。
- 实验结果表明,GAT-NeRF在视觉保真度和高频细节恢复方面表现出色,为逼真动态数字人创建提供了新方法。
📝 摘要(中文)
本文提出了一种名为Geometry-Aware-Transformer Enhanced NeRF (GAT-NeRF) 的新型混合神经辐射场框架,用于高保真和可控的4D面部Avatar重建。该方法将Transformer机制集成到NeRF流程中,协同结合了坐标对齐的多层感知机(MLP)和一个轻量级的Transformer模块,即几何感知Transformer(GAT),GAT模块通过融合多模态输入特征(包括3D空间坐标、3D Morphable Model (3DMM) 表达式参数和可学习的潜在代码)来有效地学习和增强与精细几何相关的特征表示。Transformer的有效特征学习能力被用于显著增强复杂局部面部模式(如动态皱纹和痤疮疤痕)的建模。综合实验明确地证明了GAT-NeRF在视觉保真度和高频细节恢复方面的先进性能,为创建用于多媒体应用的逼真动态数字人开辟了新途径。
🔬 方法详解
问题定义:论文旨在解决从单目视频中重建高保真4D动态面部Avatar的问题。现有的NeRF方法在捕捉面部动态皱纹、细微纹理等高频细节方面存在不足,尤其是在信息受限的单目视频输入下,重建效果不佳。
核心思路:论文的核心思路是将Transformer机制引入NeRF框架,利用Transformer强大的特征学习能力来增强NeRF对局部面部细节的建模能力。通过融合几何先验信息(3D坐标、3DMM参数),引导Transformer关注与面部几何相关的特征,从而提高重建质量。
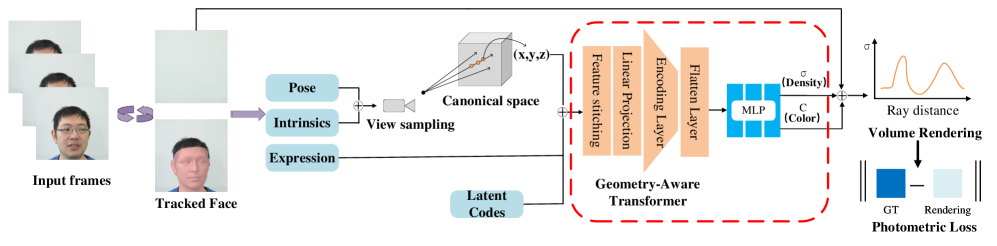
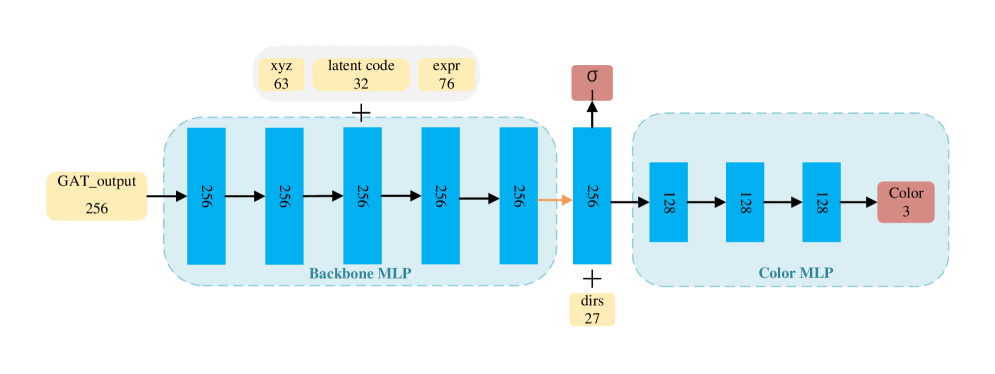
技术框架:GAT-NeRF的整体架构是一个混合神经辐射场框架,主要包含以下模块:1) 坐标对齐的MLP,用于初步的场景表示;2) Geometry-Aware Transformer (GAT) 模块,用于学习和增强与精细几何相关的特征表示;3) 体渲染模块,用于将特征表示渲染成最终的图像。GAT模块接收多模态输入特征,包括3D空间坐标、3DMM表达式参数和可学习的潜在代码。
关键创新:论文的关键创新在于提出了Geometry-Aware Transformer (GAT) 模块。GAT模块通过融合多模态输入特征,并利用Transformer的自注意力机制,有效地学习和增强与精细几何相关的特征表示。与传统的NeRF方法相比,GAT-NeRF能够更好地捕捉面部动态皱纹、细微纹理等高频细节。
关键设计:GAT模块的关键设计包括:1) 多模态输入特征融合,将3D坐标、3DMM参数和潜在代码拼接在一起作为Transformer的输入;2) 轻量级的Transformer结构,以减少计算量;3) 损失函数的设计,可能包括重建损失、正则化损失等,以保证重建质量和模型的泛化能力。(具体参数设置和损失函数细节未知)
🖼️ 关键图片

📊 实验亮点
论文通过综合实验证明了GAT-NeRF在视觉保真度和高频细节恢复方面的先进性能。虽然具体的性能数据和对比基线未知,但摘要中明确指出GAT-NeRF在重建面部动态皱纹和痤疮疤痕等细节方面表现出色,优于现有方法。实验结果为GAT-NeRF在实际应用中的潜力提供了有力支持。
🎯 应用场景
GAT-NeRF技术可广泛应用于虚拟现实、增强现实、数字人、游戏、电影等领域。它可以用于创建逼真的动态数字替身,用于虚拟会议、在线教育、娱乐互动等场景。该技术还有助于提升人机交互的沉浸感和真实感,为用户带来更优质的体验。未来,该技术有望应用于个性化医疗、远程诊断等领域。
📄 摘要(原文)
High-fidelity 4D dynamic facial avatar reconstruction from monocular video is a critical yet challenging task, driven by increasing demands for immersive virtual human applications. While Neural Radiance Fields (NeRF) have advanced scene representation, their capacity to capture high-frequency facial details, such as dynamic wrinkles and subtle textures from information-constrained monocular streams, requires significant enhancement. To tackle this challenge, we propose a novel hybrid neural radiance field framework, called Geometry-Aware-Transformer Enhanced NeRF (GAT-NeRF) for high-fidelity and controllable 4D facial avatar reconstruction, which integrates the Transformer mechanism into the NeRF pipeline. GAT-NeRF synergistically combines a coordinate-aligned Multilayer Perceptron (MLP) with a lightweight Transformer module, termed as Geometry-Aware-Transformer (GAT) due to its processing of multi-modal inputs containing explicit geometric priors. The GAT module is enabled by fusing multi-modal input features, including 3D spatial coordinates, 3D Morphable Model (3DMM) expression parameters, and learnable latent codes to effectively learn and enhance feature representations pertinent to fine-grained geometry. The Transformer's effective feature learning capabilities are leveraged to significantly augment the modeling of complex local facial patterns like dynamic wrinkles and acne scars. Comprehensive experiments unequivocally demonstrate GAT-NeRF's state-of-the-art performance in visual fidelity and high-frequency detail recovery, forging new pathways for creating realistic dynamic digital humans for multimedia applications.