UBATrack: Spatio-Temporal State Space Model for General Multi-Modal Tracking
作者: Qihua Liang, Liang Chen, Yaozong Zheng, Jian Nong, Zhiyi Mo, Bineng Zhong
分类: cs.CV
发布日期: 2026-01-21
💡 一句话要点
UBATrack:基于时空状态空间模型的通用多模态目标跟踪框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多模态跟踪 状态空间模型 Mamba模型 时空建模 适配器调优
📋 核心要点
- 现有通用多模态跟踪器忽略了对时空线索的有效捕捉,限制了跟踪性能。
- UBATrack利用Mamba模型建模时空依赖,并设计动态特征混合器增强多模态表示。
- 实验表明,UBATrack在多个多模态跟踪数据集上超越了现有SOTA方法。
📝 摘要(中文)
本文提出了一种基于Mamba风格状态空间模型的新型多模态跟踪框架UBATrack。该框架包含两个关键模块:时空Mamba适配器(STMA)和动态多模态特征混合器。STMA利用Mamba的长序列建模能力,以适配器调优的方式联合建模跨模态依赖关系和时空视觉线索。动态多模态特征混合器进一步增强了跨多个特征维度的多模态表示能力,从而提高跟踪的鲁棒性。UBATrack无需昂贵的全参数微调,从而提高了多模态跟踪算法的训练效率。实验结果表明,UBATrack在RGB-T、RGB-D和RGB-E跟踪基准上优于最先进的方法,在LasHeR、RGBT234、RGBT210、DepthTrack、VOT-RGBD22和VisEvent数据集上取得了出色的结果。
🔬 方法详解
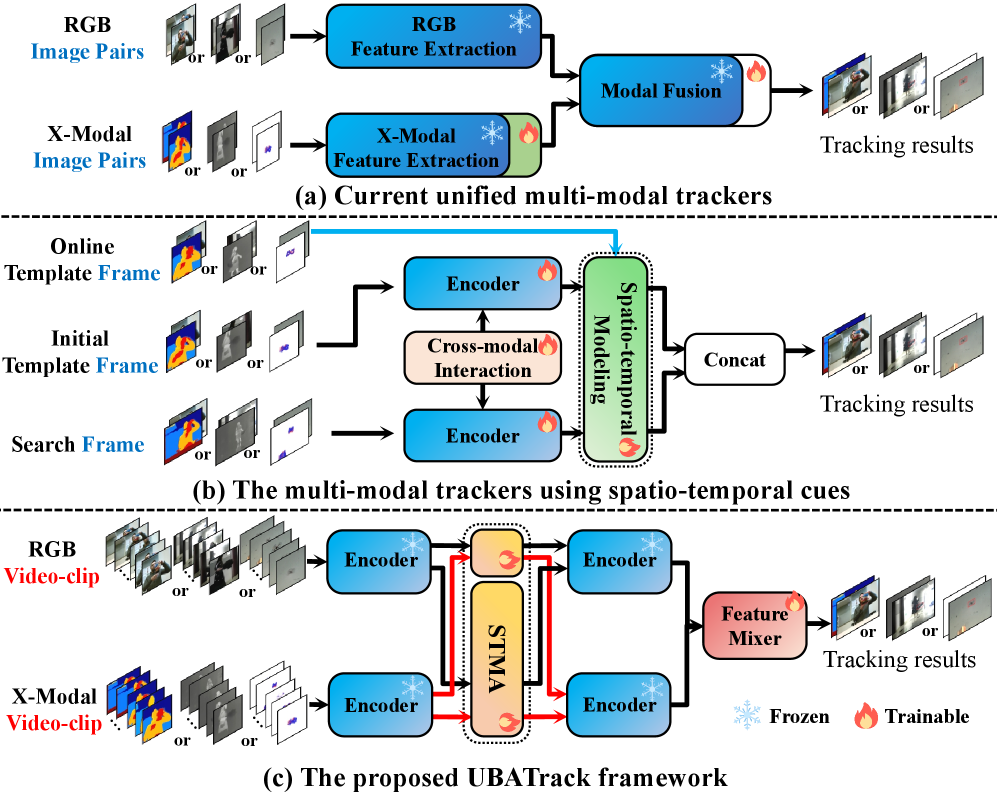
问题定义:现有的多模态目标跟踪方法,虽然通过prompt learning统一了多种模态的跟踪任务(例如RGB-热红外、RGB-深度或RGB-事件跟踪),但仍然忽略了对时空线索的有效捕捉。这导致模型无法充分利用视频序列中的时间信息,以及目标在空间上的连续性,从而影响跟踪的准确性和鲁棒性。
核心思路:UBATrack的核心思路是利用Mamba模型的长序列建模能力,同时捕捉跨模态依赖关系和时空视觉线索。通过引入时空Mamba适配器(STMA),模型可以在无需全参数微调的情况下,有效地学习到时空信息。此外,动态多模态特征混合器进一步增强了多模态特征的表达能力,提升了跟踪的鲁棒性。
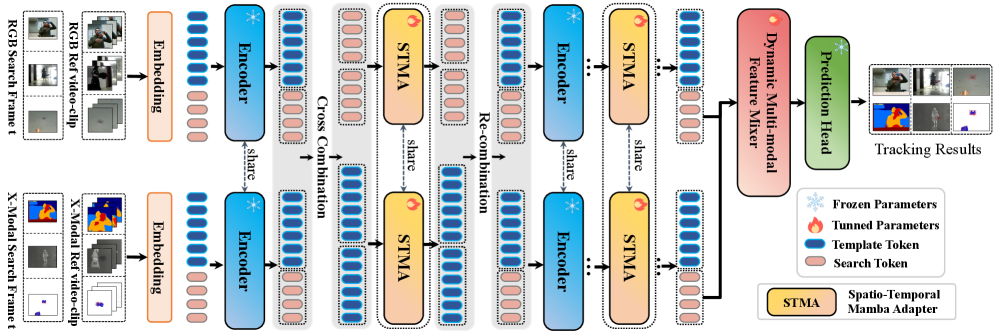
技术框架:UBATrack的整体框架包含两个主要模块:时空Mamba适配器(STMA)和动态多模态特征混合器。首先,输入的多模态特征通过STMA进行处理,该模块利用Mamba模型建模时空依赖关系,并以适配器调优的方式进行训练。然后,STMA的输出被送入动态多模态特征混合器,该模块通过学习不同模态特征之间的权重,增强多模态特征的表达能力。最后,混合后的特征被用于目标跟踪任务。
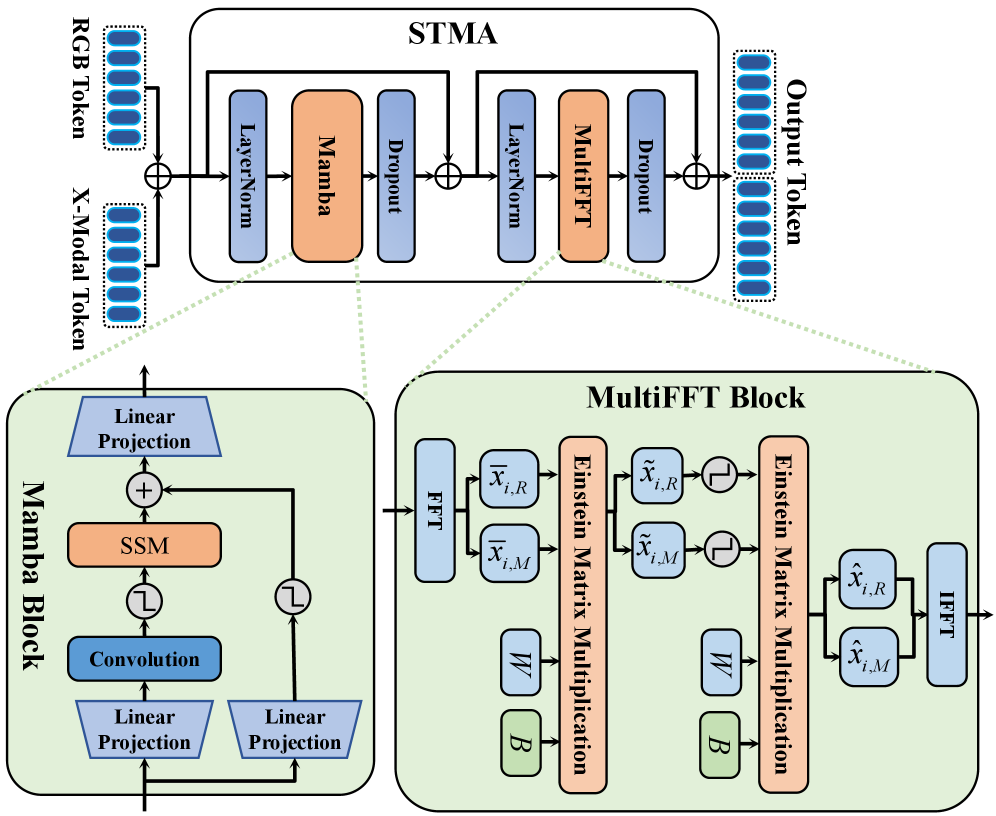
关键创新:UBATrack的关键创新在于将Mamba模型引入到多模态目标跟踪领域,并设计了时空Mamba适配器(STMA)。与传统的卷积神经网络或Transformer模型相比,Mamba模型具有更强的长序列建模能力,可以更好地捕捉视频序列中的时空信息。此外,STMA采用适配器调优的方式进行训练,避免了全参数微调的昂贵计算成本。
关键设计:STMA模块的关键设计在于利用Mamba模型的选择机制,动态地选择重要的时空信息。动态多模态特征混合器通过学习不同模态特征之间的权重,自适应地调整不同模态的贡献。具体的参数设置和损失函数等技术细节在论文中进行了详细描述,但摘要中未提供具体数值。
🖼️ 关键图片
📊 实验亮点
UBATrack在多个多模态跟踪数据集上取得了显著的性能提升。例如,在LasHeR数据集上,UBATrack的性能超越了现有SOTA方法。此外,UBATrack在RGBT234、RGBT210、DepthTrack、VOT-RGBD22和VisEvent等数据集上也取得了出色的结果,证明了其在不同模态组合下的通用性和有效性。
🎯 应用场景
UBATrack具有广泛的应用前景,例如智能安防、自动驾驶、机器人导航等领域。在这些场景中,多模态信息可以提供更全面、更鲁棒的目标感知能力。例如,在光照条件不佳的情况下,热红外图像可以提供额外的目标信息;在遮挡情况下,深度信息可以帮助模型更好地理解场景。
📄 摘要(原文)
Multi-modal object tracking has attracted considerable attention by integrating multiple complementary inputs (e.g., thermal, depth, and event data) to achieve outstanding performance. Although current general-purpose multi-modal trackers primarily unify various modal tracking tasks (i.e., RGB-Thermal infrared, RGB-Depth or RGB-Event tracking) through prompt learning, they still overlook the effective capture of spatio-temporal cues. In this work, we introduce a novel multi-modal tracking framework based on a mamba-style state space model, termed UBATrack. Our UBATrack comprises two simple yet effective modules: a Spatio-temporal Mamba Adapter (STMA) and a Dynamic Multi-modal Feature Mixer. The former leverages Mamba's long-sequence modeling capability to jointly model cross-modal dependencies and spatio-temporal visual cues in an adapter-tuning manner. The latter further enhances multi-modal representation capacity across multiple feature dimensions to improve tracking robustness. In this way, UBATrack eliminates the need for costly full-parameter fine-tuning, thereby improving the training efficiency of multi-modal tracking algorithms. Experiments show that UBATrack outperforms state-of-the-art methods on RGB-T, RGB-D, and RGB-E tracking benchmarks, achieving outstanding results on the LasHeR, RGBT234, RGBT210, DepthTrack, VOT-RGBD22, and VisEvent datasets.