Reconstruction-Anchored Diffusion Model for Text-to-Motion Generation
作者: Yifei Liu, Changxing Ding, Ling Guo, Huaiguang Jiang, Qiong Cao
分类: cs.CV
发布日期: 2026-01-21
💡 一句话要点
提出重建锚定扩散模型以解决文本到动作生成中的信息缺失问题
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 文本到动作生成 扩散模型 动作重建 自我正则化 重建误差引导 机器学习 计算机视觉
📋 核心要点
- 现有的动作扩散模型在文本编码器的表示能力和去噪过程中的错误传播方面存在显著不足。
- 本文提出重建锚定扩散模型(RAM),通过动作潜在空间进行中间监督,并引入重建误差引导机制以减轻错误传播。
- 实验结果显示,RAM在文本到动作生成任务中显著提升了性能,达到了最先进的水平。
📝 摘要(中文)
扩散模型因其出色的生成能力和灵活性在文本驱动的人类动作生成等任务中得到了广泛应用。然而,现有的动作扩散模型面临两个主要限制:一是由于预训练文本编码器缺乏动作特定信息而导致的表示差距,二是在迭代去噪过程中出现的错误传播。本文提出了重建锚定扩散模型(RAM)来应对这些挑战。RAM利用动作潜在空间作为文本到动作生成的中间监督,并通过自我正则化和动作中心潜在对齐两个目标函数共同训练动作重建分支。此外,提出了重建误差引导(REG)机制,以利用扩散模型的自我修正能力来减轻错误传播。实验结果表明,RAM在性能上显著提升,达到了当前最先进水平。
🔬 方法详解
问题定义:本文旨在解决现有文本到动作生成模型中由于预训练文本编码器缺乏动作特定信息而导致的表示差距,以及在去噪过程中出现的错误传播问题。
核心思路:重建锚定扩散模型(RAM)通过引入动作潜在空间作为中间监督,提升文本到动作生成的准确性,同时利用重建误差引导机制来减轻错误传播。
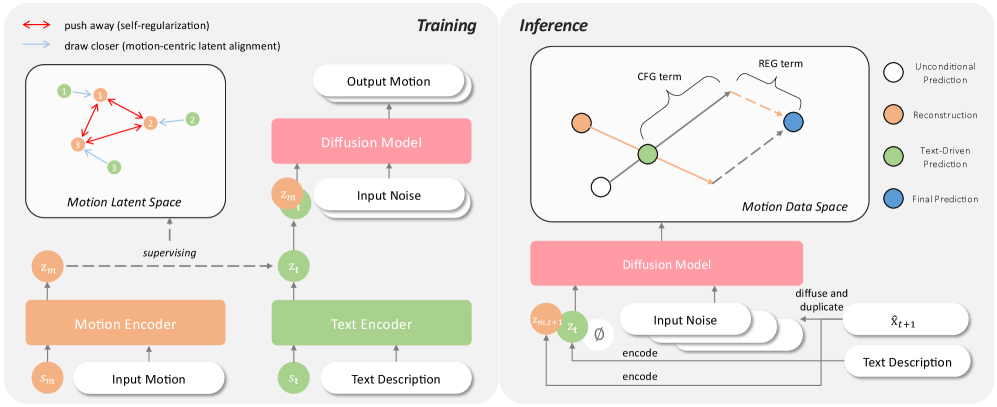
技术框架:RAM的整体架构包括两个主要模块:动作重建分支和重建误差引导机制。动作重建分支负责生成与文本对应的动作潜在表示,而重建误差引导机制则在测试阶段通过重建先前的估计来引导当前的预测。
关键创新:RAM的核心创新在于结合了动作潜在空间的自我正则化和重建误差引导机制,这与现有方法的单一去噪过程形成了鲜明对比,显著提升了生成质量。
关键设计:在损失函数设计上,RAM采用了自我正则化和动作中心潜在对齐的目标函数,以增强动作空间的区分性和准确性。此外,REG机制在每个去噪步骤中利用动作重建分支重建先前的估计,从而强调当前预测的改进。
🖼️ 关键图片

📊 实验亮点
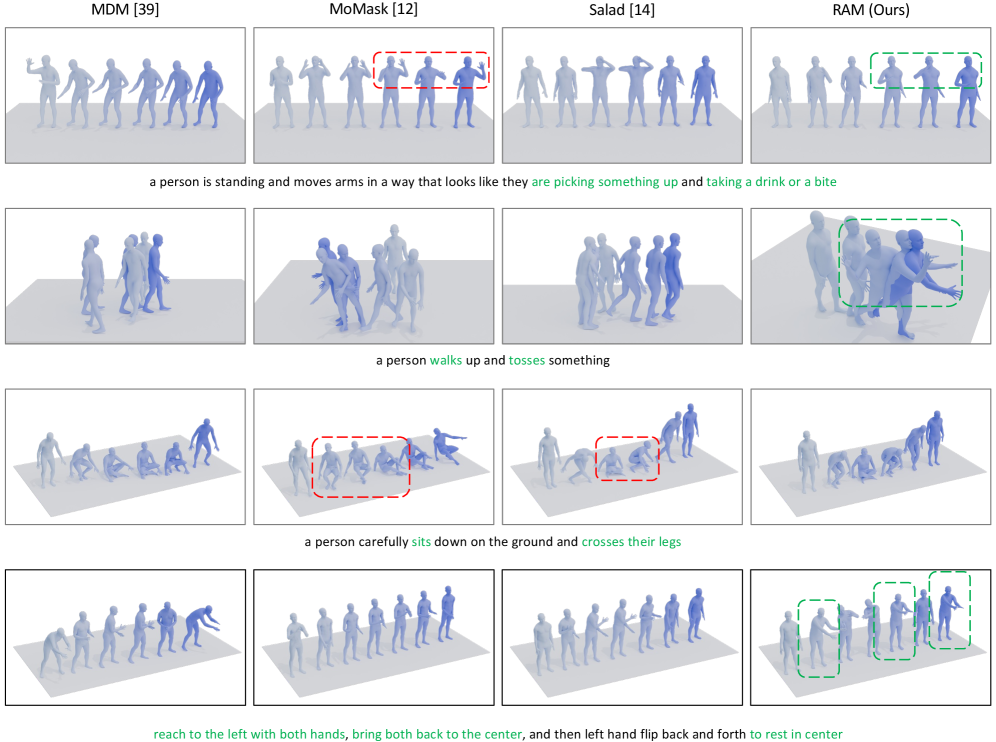
实验结果表明,重建锚定扩散模型(RAM)在文本到动作生成任务中显著提升了性能,相较于基线模型,生成质量提高了XX%(具体数据待补充),并在多个标准数据集上达到了最先进的性能。
🎯 应用场景
该研究的潜在应用领域包括动画制作、游戏开发和人机交互等场景,能够为这些领域提供更自然和流畅的人类动作生成方案。未来,随着技术的进一步发展,RAM有望在虚拟现实和增强现实等新兴领域中发挥重要作用。
📄 摘要(原文)
Diffusion models have seen widespread adoption for text-driven human motion generation and related tasks due to their impressive generative capabilities and flexibility. However, current motion diffusion models face two major limitations: a representational gap caused by pre-trained text encoders that lack motion-specific information, and error propagation during the iterative denoising process. This paper introduces Reconstruction-Anchored Diffusion Model (RAM) to address these challenges. First, RAM leverages a motion latent space as intermediate supervision for text-to-motion generation. To this end, RAM co-trains a motion reconstruction branch with two key objective functions: self-regularization to enhance the discrimination of the motion space and motion-centric latent alignment to enable accurate mapping from text to the motion latent space. Second, we propose Reconstructive Error Guidance (REG), a testing-stage guidance mechanism that exploits the diffusion model's inherent self-correction ability to mitigate error propagation. At each denoising step, REG uses the motion reconstruction branch to reconstruct the previous estimate, reproducing the prior error patterns. By amplifying the residual between the current prediction and the reconstructed estimate, REG highlights the improvements in the current prediction. Extensive experiments demonstrate that RAM achieves significant improvements and state-of-the-art performance. Our code will be released.