FunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
作者: Jiaxuan Liu, Yang Xiang, Han Zhao, Xiangang Li, Zhenhua Ling
分类: cs.CV, cs.AI
发布日期: 2026-01-21
💡 一句话要点
FunCineForge:面向多样化电影场景的零样本电影配音统一工具包与模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电影配音 多模态学习 大语言模型 数据集构建 视听对齐
📋 核心要点
- 现有电影配音方法依赖小规模、低质量数据集,且标注成本高昂,限制了模型训练效果。
- FunCineForge提出端到端生产流程,构建大规模高质量中文电视配音数据集,并设计MLLM配音模型。
- 实验表明,该模型在音频质量、唇形同步、音色转换和指令遵循方面均优于现有最佳方法。
📝 摘要(中文)
电影配音是一项根据视频场景,从剧本中合成语音的任务,它需要精确的唇形同步、忠实的声音转换以及对角色身份和情感的适当建模。然而,现有方法面临两个主要限制:(1)高质量的多模态配音数据集规模有限,存在高词错误率,包含稀疏的注释,依赖于昂贵的手动标注,并且仅限于独白场景,所有这些都阻碍了有效的模型训练;(2)现有的配音模型仅依赖于唇部区域来学习视听对齐,这限制了它们在复杂的实景电影场景中的适用性,并且在唇形同步、语音质量和情感表达方面表现不佳。为了解决这些问题,我们提出了FunCineForge,它包括一个用于大规模配音数据集的端到端生产流程和一个专为多样化电影场景设计的基于MLLM的配音模型。使用该流程,我们构建了第一个具有丰富注释的中文电视配音数据集,并证明了这些数据的高质量。在独白、叙述、对话和多说话人场景中的实验表明,我们的配音模型在音频质量、唇形同步、音色转换和指令遵循方面始终优于SOTA方法。代码和演示可在https://anonymous.4open.science/w/FunCineForge获得。
🔬 方法详解
问题定义:现有电影配音方法主要面临两个问题:一是高质量多模态配音数据集的匮乏,现有数据集规模小、错误率高、标注稀疏且成本高昂,限制了模型训练;二是现有模型过度依赖唇部区域进行视听对齐,导致在复杂电影场景中表现不佳,唇形同步、语音质量和情感表达均有待提升。
核心思路:FunCineForge的核心思路是构建大规模、高质量的配音数据集,并设计一个能够有效利用多模态信息(不仅仅是唇部)的配音模型。通过数据和模型的双重优化,提升配音的真实感和表现力。
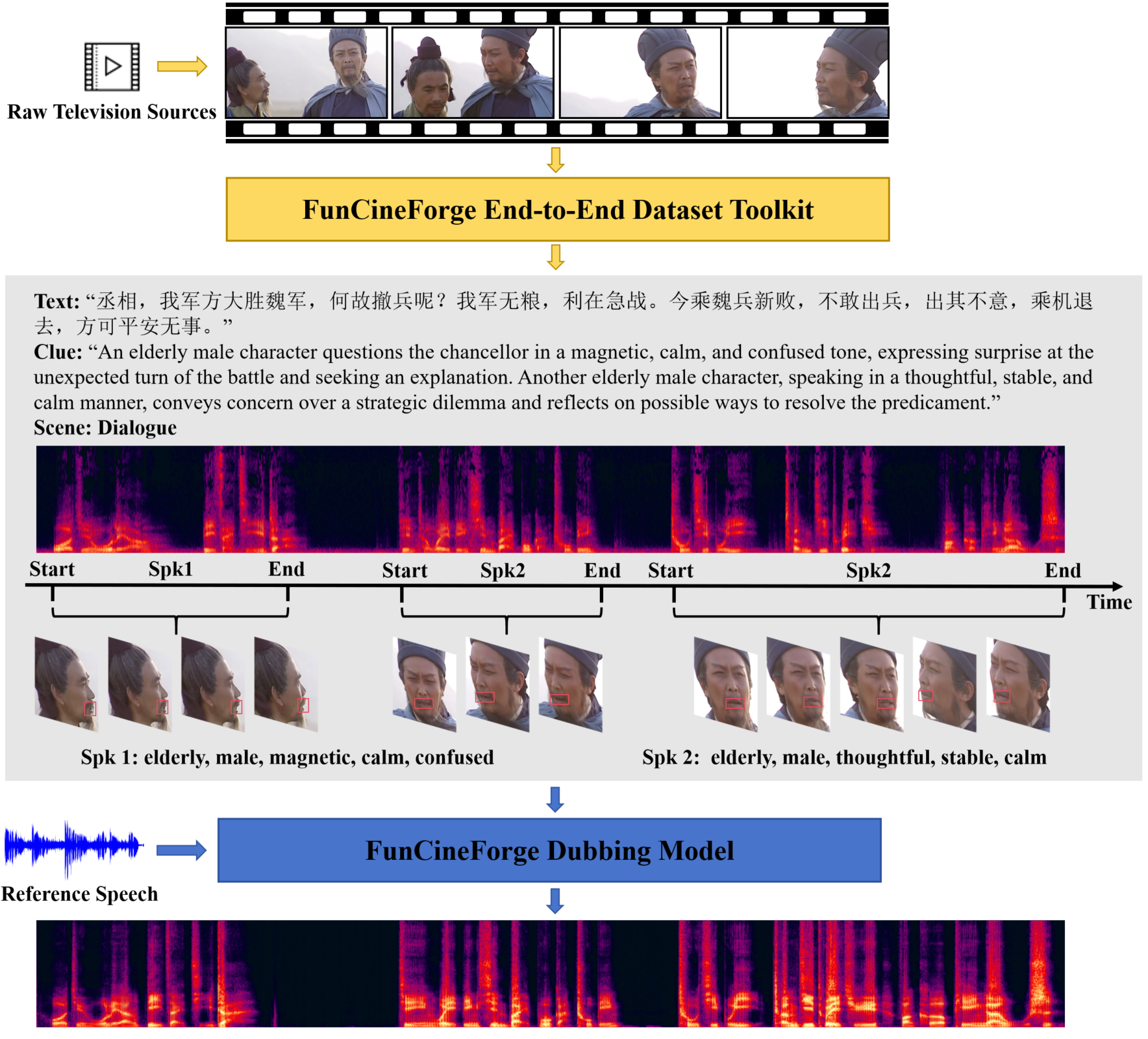
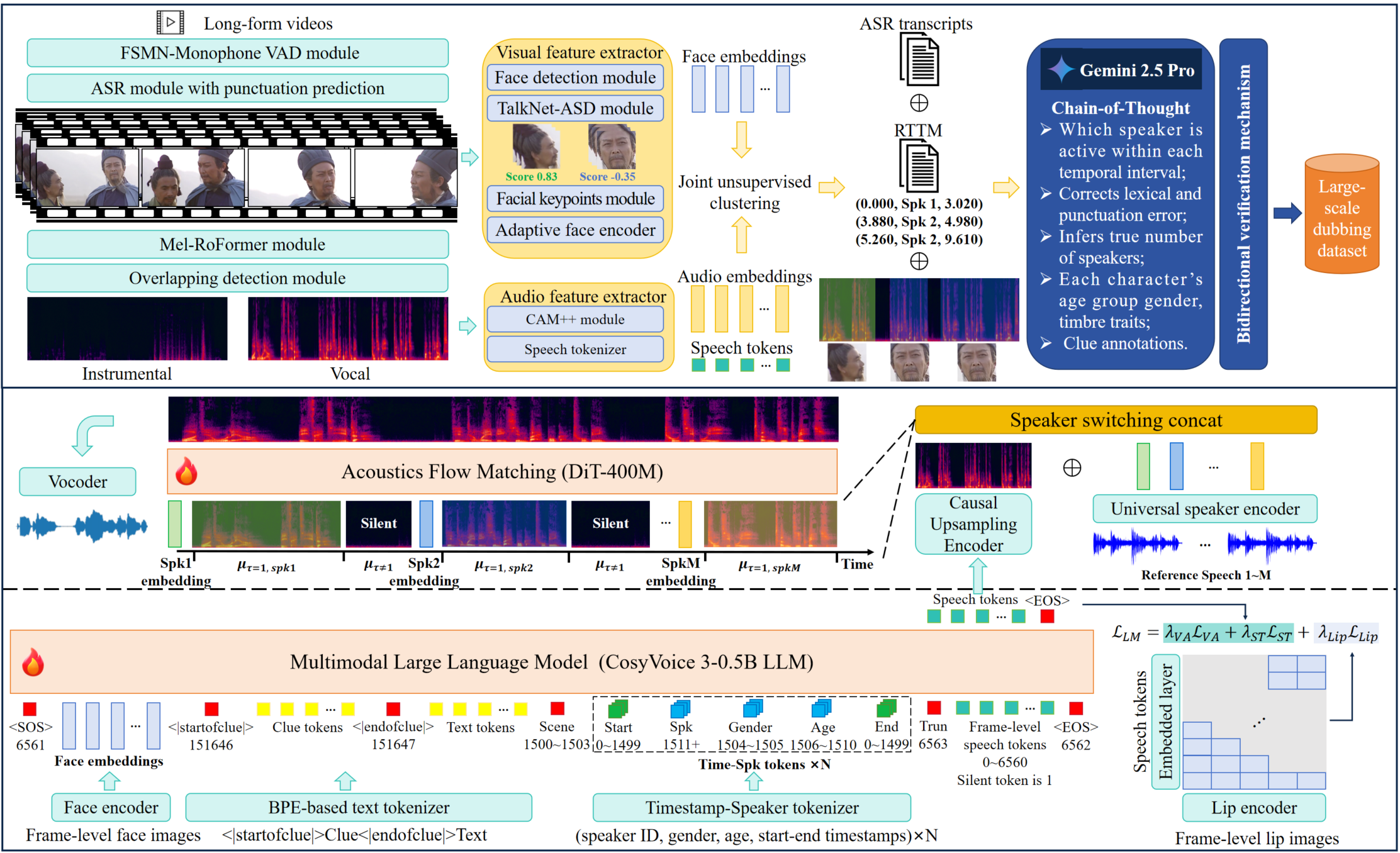
技术框架:FunCineForge包含两个主要组成部分:一是端到端的数据生产流程,用于构建大规模配音数据集;二是基于多模态大语言模型(MLLM)的配音模型。数据生产流程负责收集、清洗、标注数据,MLLM配音模型则利用这些数据进行训练,实现高质量的配音效果。具体流程细节未知。
关键创新:该论文的关键创新在于:(1) 提出了一个端到端的数据生产流程,能够高效地构建大规模、高质量的配音数据集,解决了数据匮乏的问题;(2) 设计了一个基于MLLM的配音模型,能够更好地利用多模态信息,提升配音的真实感和表现力。与现有方法相比,该方法不再局限于唇部区域,而是能够综合考虑场景、角色等多种因素。
关键设计:论文中关于数据生产流程和MLLM配音模型的具体技术细节描述较少,例如数据清洗和标注的具体方法、MLLM模型的具体结构、损失函数的设计等。这些细节需要参考论文原文或代码才能进一步了解。关于参数设置、网络结构等技术细节未知。
🖼️ 关键图片
📊 实验亮点
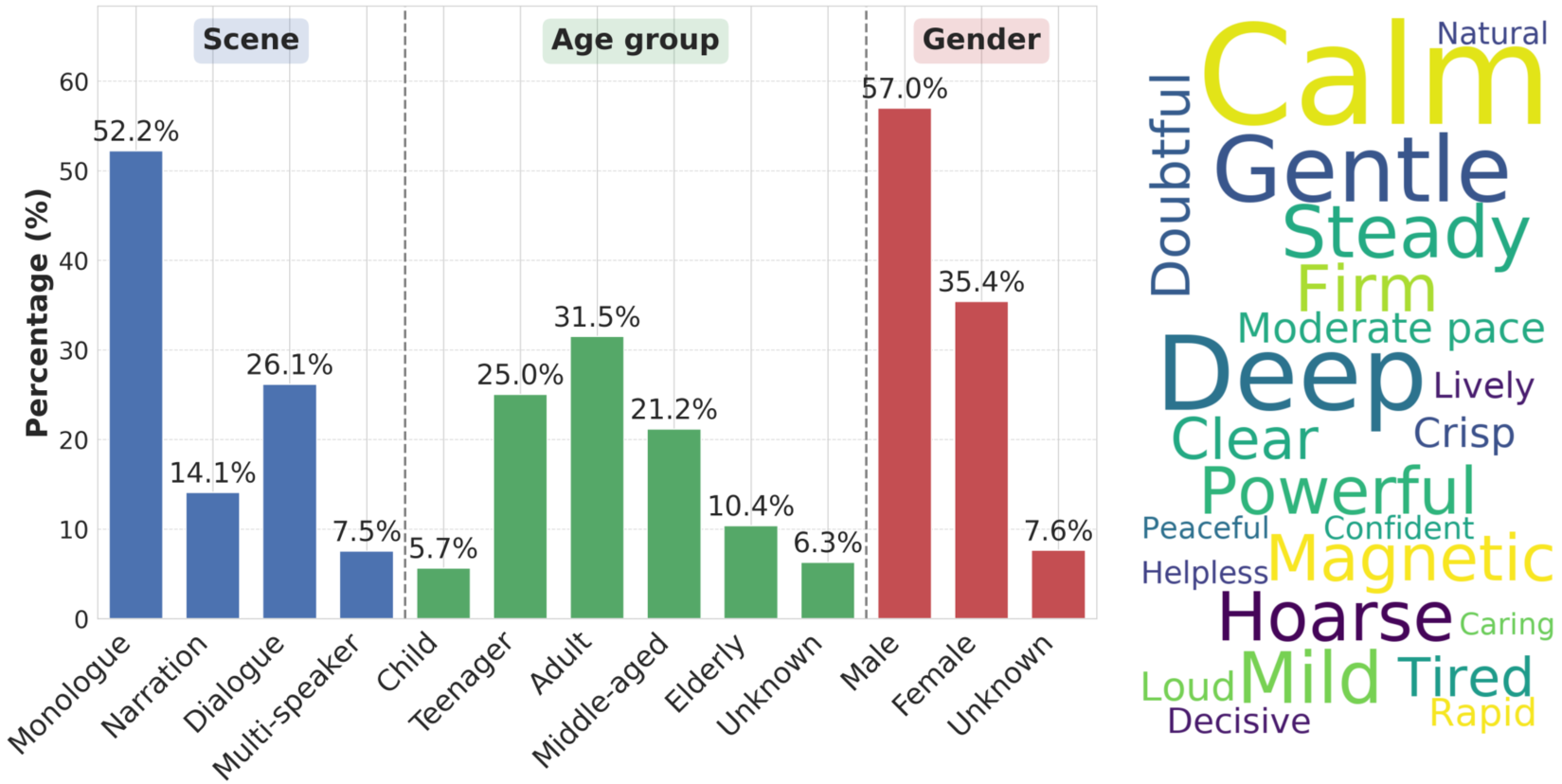
FunCineForge构建了首个具有丰富注释的中文电视配音数据集,并证明了其高质量。实验结果表明,该配音模型在独白、叙述、对话和多说话人场景中,音频质量、唇形同步、音色转换和指令遵循方面均优于现有最佳方法(SOTA)。具体的性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于电影、电视剧、动画等领域的配音制作,降低配音成本,提高配音效率和质量。同时,该技术还可应用于虚拟角色语音合成、语音助手等领域,具有广阔的应用前景和商业价值。未来,该技术有望实现更加智能化的配音,例如自动根据角色情感调整语音语调。
📄 摘要(原文)
Movie dubbing is the task of synthesizing speech from scripts conditioned on video scenes, requiring accurate lip sync, faithful timbre transfer, and proper modeling of character identity and emotion. However, existing methods face two major limitations: (1) high-quality multimodal dubbing datasets are limited in scale, suffer from high word error rates, contain sparse annotations, rely on costly manual labeling, and are restricted to monologue scenes, all of which hinder effective model training; (2) existing dubbing models rely solely on the lip region to learn audio-visual alignment, which limits their applicability to complex live-action cinematic scenes, and exhibit suboptimal performance in lip sync, speech quality, and emotional expressiveness. To address these issues, we propose FunCineForge, which comprises an end-to-end production pipeline for large-scale dubbing datasets and an MLLM-based dubbing model designed for diverse cinematic scenes. Using the pipeline, we construct the first Chinese television dubbing dataset with rich annotations, and demonstrate the high quality of these data. Experiments across monologue, narration, dialogue, and multi-speaker scenes show that our dubbing model consistently outperforms SOTA methods in audio quality, lip sync, timbre transfer, and instruction following. Code and demos are available at https://anonymous.4open.science/w/FunCineForge.