M2I2HA: A Multi-modal Object Detection Method Based on Intra- and Inter-Modal Hypergraph Attention
作者: Xiaofan Yang, Yubin Liu, Wei Pan, Guoqing Chu, Junming Zhang, Jie Zhao, Zhuoqi Man, Xuanming Cao
分类: cs.CV
发布日期: 2026-01-21
备注: 43 pages, 13 figures
💡 一句话要点
提出M2I2HA,利用超图注意力进行多模态目标检测,提升复杂环境下的检测精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多模态目标检测 超图注意力 跨模态融合 高阶关系建模 特征增强
📋 核心要点
- 现有方法难以有效提取模态内和模态间任务相关信息,且跨模态对齐精度不足,限制了多模态目标检测的性能。
- M2I2HA利用超图结构建模模态内高阶关系和模态间配置空间关系,实现特征增强和对齐,提升检测精度。
- 实验结果表明,M2I2HA在多个数据集上取得了state-of-the-art的性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种基于超图理论的多模态感知网络M2I2HA,旨在解决多模态目标检测中有效提取模态内和模态间任务相关信息以及精确跨模态对齐的挑战。该架构包含一个模态内超图增强模块,用于捕获每个模态内的全局多对多高阶关系;以及一个模态间超图融合模块,通过桥接数据源之间的配置和空间差距,对齐、增强和融合跨模态特征。此外,引入M2-FullPAD模块,实现网络内多模态增强特征的自适应多级融合,同时增强整个架构中的数据分布和流动。在多个公共数据集上进行的大量目标检测实验表明,M2I2HA在多模态目标检测任务中实现了最先进的性能。
🔬 方法详解
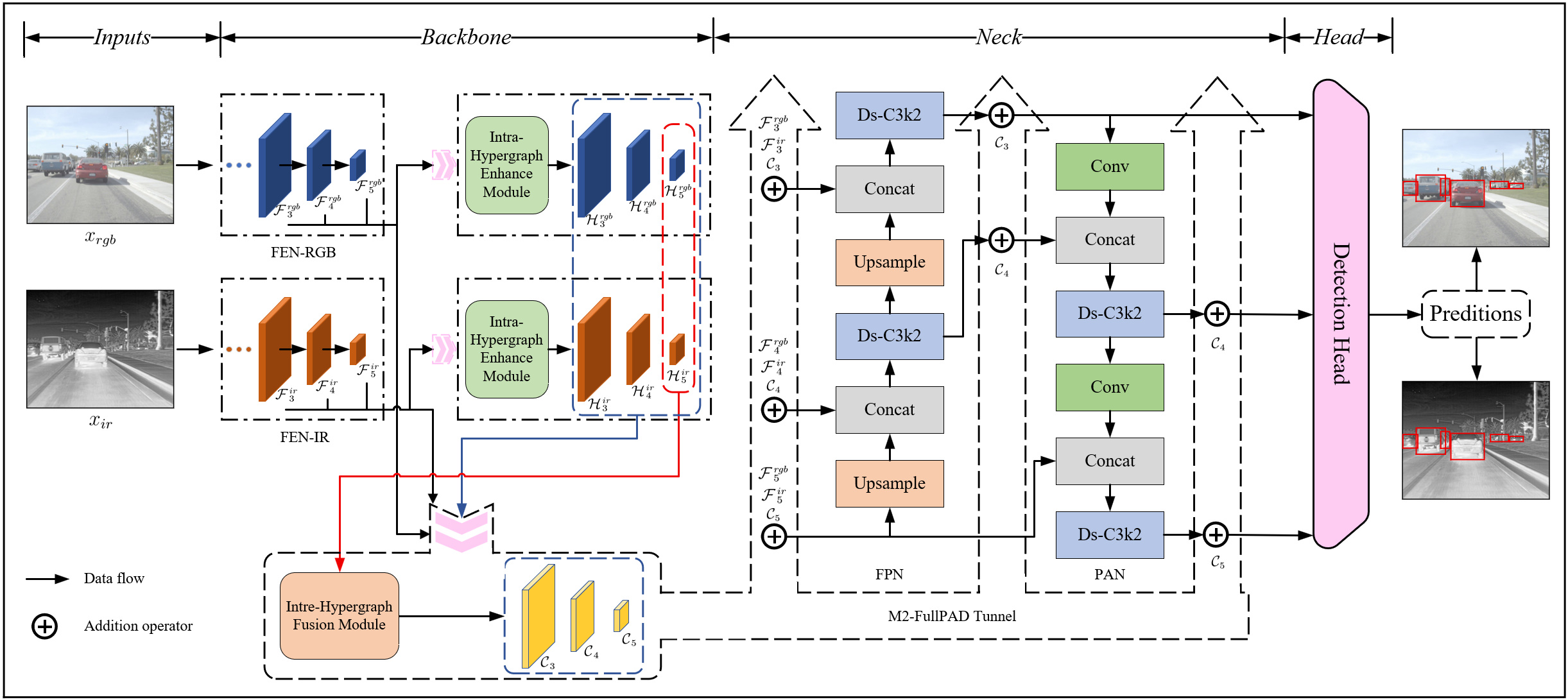
问题定义:多模态目标检测旨在融合来自不同传感器(如RGB、热成像、深度)的信息,以提高在光照不足或过度曝光等复杂环境下的检测精度。然而,现有方法难以有效提取模态内和模态间任务相关的特征,并且在跨模态对齐方面存在精度不足的问题。卷积神经网络感受野有限,Transformer计算复杂度高,而状态空间模型则破坏了2D空间结构。
核心思路:本文的核心思路是利用超图(Hypergraph)来建模模态内的高阶关系和模态间的配置空间关系。超图能够表示多个节点之间的连接,从而捕获传统图结构难以表达的复杂关系。通过超图注意力机制,可以自适应地学习不同节点之间的重要性,从而实现特征增强和跨模态对齐。
技术框架:M2I2HA网络主要包含三个模块:1) 模态内超图增强模块(Intra-Hypergraph Enhancement):用于捕获每个模态内的全局多对多高阶关系。2) 模态间超图融合模块(Inter-Hypergraph Fusion):用于对齐、增强和融合跨模态特征,桥接数据源之间的配置和空间差距。3) M2-FullPAD模块:实现网络内多模态增强特征的自适应多级融合,同时增强整个架构中的数据分布和流动。
关键创新:本文的关键创新在于将超图理论引入到多模态目标检测中,并设计了相应的超图注意力机制。与传统的卷积、Transformer和状态空间模型相比,超图能够更好地建模高阶关系和非欧几里得空间中的数据,从而更有效地提取任务相关特征和实现跨模态对齐。M2-FullPAD模块实现了自适应多级融合,进一步提升了性能。
关键设计:模态内超图增强模块和模态间超图融合模块都采用了超图注意力机制,具体实现细节未知。M2-FullPAD模块的具体结构和参数设置未知。损失函数的设计也未在摘要中提及,具体实现未知。
🖼️ 关键图片


📊 实验亮点
摘要中提到,M2I2HA在多个公共数据集上进行了大量的目标检测实验,并取得了state-of-the-art的性能。具体的性能数据、对比基线和提升幅度未知,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于自动驾驶、安防监控、机器人导航等领域。在这些场景中,多模态传感器能够提供更全面的环境信息,从而提高目标检测的鲁棒性和准确性。例如,在光照条件不佳的情况下,热成像传感器可以提供额外的目标信息,从而弥补RGB传感器的不足。该研究的未来影响在于推动多模态感知技术的发展,为智能系统的应用提供更可靠的基础。
📄 摘要(原文)
Recent advances in multi-modal detection have significantly improved detection accuracy in challenging environments (e.g., low light, overexposure). By integrating RGB with modalities such as thermal and depth, multi-modal fusion increases data redundancy and system robustness. However, significant challenges remain in effectively extracting task-relevant information both within and across modalities, as well as in achieving precise cross-modal alignment. While CNNs excel at feature extraction, they are limited by constrained receptive fields, strong inductive biases, and difficulty in capturing long-range dependencies. Transformer-based models offer global context but suffer from quadratic computational complexity and are confined to pairwise correlation modeling. Mamba and other State Space Models (SSMs), on the other hand, are hindered by their sequential scanning mechanism, which flattens 2D spatial structures into 1D sequences, disrupting topological relationships and limiting the modeling of complex higher-order dependencies. To address these issues, we propose a multi-modal perception network based on hypergraph theory called M2I2HA. Our architecture includes an Intra-Hypergraph Enhancement module to capture global many-to-many high-order relationships within each modality, and an Inter-Hypergraph Fusion module to align, enhance, and fuse cross-modal features by bridging configuration and spatial gaps between data sources. We further introduce a M2-FullPAD module to enable adaptive multi-level fusion of multi-modal enhanced features within the network, meanwhile enhancing data distribution and flow across the architecture. Extensive object detection experiments on multiple public datasets against baselines demonstrate that M2I2HA achieves state-of-the-art performance in multi-modal object detection tasks.