3D Space as a Scratchpad for Editable Text-to-Image Generation
作者: Oindrila Saha, Vojtech Krs, Radomir Mech, Subhransu Maji, Matheus Gadelha, Kevin Blackburn-Matzen
分类: cs.CV
发布日期: 2026-01-21
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于3D空间草稿板的可编辑文本到图像生成框架,提升空间推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 3D空间推理 可编辑图像生成 视觉语言模型 场景规划 智能体 空间一致性
📋 核心要点
- 现有视觉语言模型缺乏空间推理机制,难以准确生成反映几何关系、物体身份和组合意图的图像。
- 论文提出空间草稿板,将文本提示解析为可编辑的3D网格,通过智能体规划场景,再渲染成图像。
- 实验表明,该方法在GenAI-Bench上文本对齐度提升32%,验证了显式3D推理在图像生成中的优势。
📝 摘要(中文)
本文提出了一种空间草稿板的概念,它是一个连接语言意图和图像合成的3D推理基底。该框架首先解析文本提示中的主体和背景元素,并将它们实例化为可编辑的3D网格。然后,利用智能体进行场景规划,确定物体的位置、方向和视角。最终,将3D场景渲染回图像域,并保留身份信息,从而使视觉语言模型(VLM)能够生成空间一致且视觉连贯的输出。与以往基于2D布局的方法不同,该方法支持直观的3D编辑,并能可靠地传播到最终图像中。在GenAI-Bench上的实验结果表明,文本对齐度提高了32%,证明了显式3D推理对于精确、可控图像生成的好处。这项研究为视觉语言模型开辟了一个新的范例,使其不仅在语言上,而且在空间上进行推演。
🔬 方法详解
问题定义:现有的文本到图像生成模型在处理复杂场景和需要精确空间关系的提示时表现不足。它们通常依赖于2D布局或注意力机制来隐式地学习空间关系,但缺乏显式的空间推理能力,导致生成的图像在物体位置、大小、方向等方面存在不一致性,并且难以进行精确的编辑和控制。
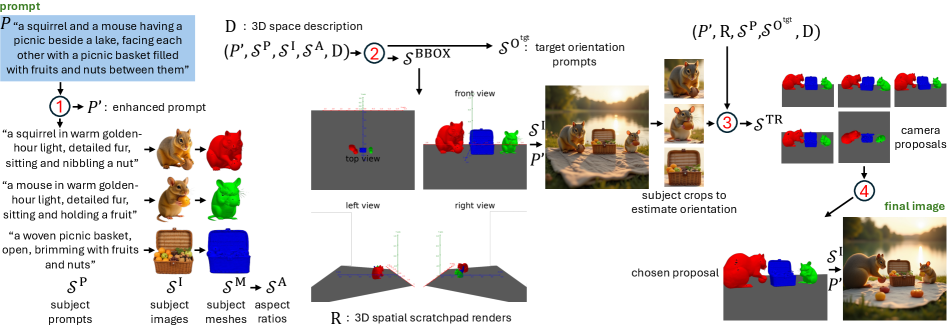
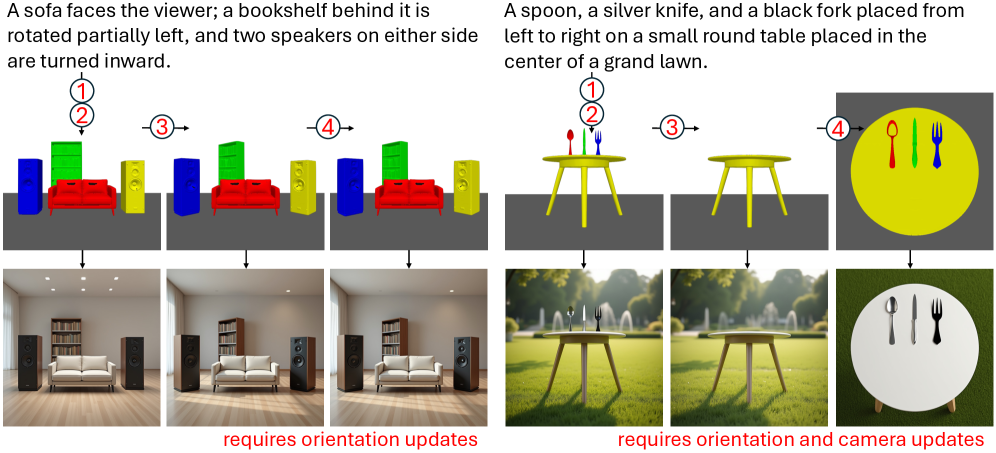
核心思路:论文的核心思路是将文本到图像的生成过程分解为两个阶段:首先,利用3D空间作为中间表示,显式地建模场景中的物体和它们之间的空间关系;然后,将3D场景渲染成2D图像,并利用视觉语言模型进行图像生成。通过这种方式,可以有效地利用3D空间的几何约束来提高生成图像的空间一致性和可控性。
技术框架:该框架包含以下几个主要模块:1) 文本解析模块,用于从文本提示中提取主体和背景元素;2) 3D实例化模块,用于将提取的元素实例化为可编辑的3D网格;3) 场景规划模块,利用智能体来规划物体的位置、方向和视角,以满足文本提示的要求;4) 渲染模块,将3D场景渲染成2D图像;5) 图像生成模块,利用视觉语言模型对渲染的图像进行进一步的优化和生成。
关键创新:该方法最重要的创新点在于引入了3D空间作为文本到图像生成过程中的中间表示。与以往基于2D布局的方法相比,该方法能够显式地建模场景中的物体和它们之间的空间关系,从而提高生成图像的空间一致性和可控性。此外,该方法还支持直观的3D编辑,并能可靠地传播到最终图像中。
关键设计:在场景规划模块中,论文采用了基于强化学习的智能体来规划物体的位置、方向和视角。智能体的奖励函数被设计为鼓励生成满足文本提示要求的场景,并惩罚违反空间约束的场景。此外,在渲染模块中,论文采用了身份保持的渲染技术,以确保生成的图像能够保留原始3D模型的身份信息。
🖼️ 关键图片

📊 实验亮点
该方法在GenAI-Bench数据集上进行了评估,实验结果表明,该方法在文本对齐度方面取得了显著的提升,达到了32%。与现有的基于2D布局的方法相比,该方法能够生成更加空间一致和视觉连贯的图像。此外,该方法还支持直观的3D编辑,并能可靠地传播到最终图像中,为用户提供了更大的创作自由。
🎯 应用场景
该研究成果可应用于各种需要精确空间控制的图像生成场景,例如:虚拟现实内容创作、游戏场景设计、产品设计可视化、以及教育领域的3D模型辅助教学等。通过提供直观的3D编辑界面,用户可以轻松地创建和修改复杂的场景,从而提高创作效率和质量。未来,该技术有望与更强大的视觉语言模型结合,实现更逼真、更可控的图像生成。
📄 摘要(原文)
Recent progress in large language models (LLMs) has shown that reasoning improves when intermediate thoughts are externalized into explicit workspaces, such as chain-of-thought traces or tool-augmented reasoning. Yet, visual language models (VLMs) lack an analogous mechanism for spatial reasoning, limiting their ability to generate images that accurately reflect geometric relations, object identities, and compositional intent. We introduce the concept of a spatial scratchpad -- a 3D reasoning substrate that bridges linguistic intent and image synthesis. Given a text prompt, our framework parses subjects and background elements, instantiates them as editable 3D meshes, and employs agentic scene planning for placement, orientation, and viewpoint selection. The resulting 3D arrangement is rendered back into the image domain with identity-preserving cues, enabling the VLM to generate spatially consistent and visually coherent outputs. Unlike prior 2D layout-based methods, our approach supports intuitive 3D edits that propagate reliably into final images. Empirically, it achieves a 32% improvement in text alignment on GenAI-Bench, demonstrating the benefit of explicit 3D reasoning for precise, controllable image generation. Our results highlight a new paradigm for vision-language models that deliberate not only in language, but also in space. Code and visualizations at https://oindrilasaha.github.io/3DScratchpad/