Breaking the accuracy-resource dilemma: a lightweight adaptive video inference enhancement
作者: Wei Ma, Shaowu Chen, Junjie Ye, Peichang Zhang, Lei Huang
分类: cs.CV, cs.AI
发布日期: 2026-01-21
备注: 5 pages, 4 figures
💡 一句话要点
提出基于模糊控制的自适应视频推理增强框架,解决精度-资源困境
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频推理 自适应推理 模糊控制 资源优化 边缘计算
📋 核心要点
- 现有视频推理增强方法侧重于提升性能,但忽略了资源效率,导致资源浪费和推理效果不佳。
- 本文提出一种基于模糊控制器的自适应框架,利用视频帧间的时空相关性,动态调整模型规模。
- 实验表明,该方法能在资源利用和推理性能间取得平衡,提升资源受限场景下的推理效率。
📝 摘要(中文)
现有的视频推理(VI)增强方法通常旨在通过扩大模型尺寸和采用复杂的网络架构来提高性能。虽然这些方法表现出了最先进的性能,但它们往往忽略了资源效率和推理有效性之间的权衡,导致资源利用率低下和次优的推理性能。为了解决这个问题,本文基于关键系统参数和推理相关指标,开发了一个模糊控制器(FC-r)。在FC-r的指导下,提出了一个VI增强框架,该框架利用了相邻视频帧中目标的时空相关性。在目标设备的实时资源条件下,该框架可以在VI期间动态切换不同规模的模型。实验结果表明,该方法有效地实现了资源利用率和推理性能之间的平衡。
🔬 方法详解
问题定义:现有视频推理增强方法为了追求更高的精度,通常采用更大的模型和更复杂的网络结构,这导致了计算资源消耗过高,难以在资源受限的设备上部署。因此,如何在保证推理精度的同时,降低资源消耗,是本文要解决的核心问题。现有方法的痛点在于无法根据实际的资源情况动态调整模型,导致资源利用率低下。
核心思路:本文的核心思路是利用视频帧之间目标的时空相关性,并结合模糊控制理论,根据目标设备的实时资源状况,动态地选择合适的模型规模进行推理。通过这种自适应的方式,可以在资源充足时使用大模型获得更高的精度,而在资源紧张时切换到小模型以保证推理速度和资源消耗。
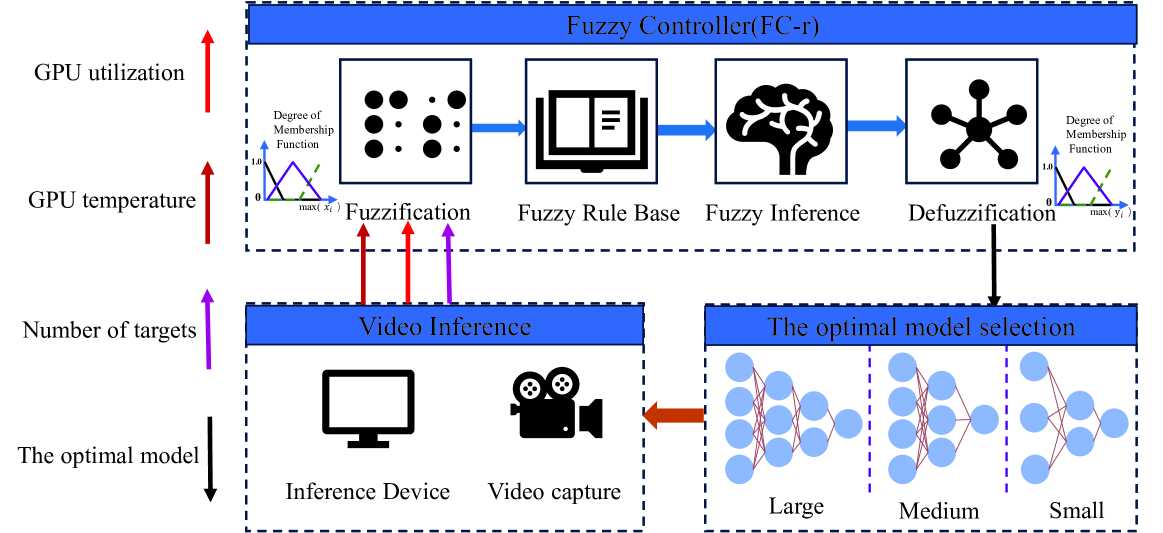
技术框架:该视频推理增强框架主要包含以下几个模块:1) 系统参数和推理指标监控模块,用于实时获取设备的CPU、GPU利用率等系统参数以及推理延迟、精度等推理指标;2) 模糊控制器(FC-r),根据监控到的系统参数和推理指标,通过模糊推理算法,输出一个模型选择的决策;3) 模型切换模块,根据模糊控制器的决策,动态地切换不同规模的模型进行推理;4) 视频推理模块,使用选定的模型对视频帧进行推理,并输出推理结果。
关键创新:本文最重要的技术创新点在于提出了基于模糊控制器的自适应模型选择机制。与传统的静态模型选择方法不同,该方法能够根据实时的资源状况和推理性能指标,动态地调整模型规模,从而在精度和资源消耗之间取得更好的平衡。此外,利用视频帧之间的时空相关性,可以在一定程度上弥补小模型带来的精度损失。
关键设计:模糊控制器(FC-r)的设计是关键。首先需要确定输入变量,例如CPU利用率、GPU利用率、推理延迟等。然后,需要对每个输入变量进行模糊化处理,将其转化为模糊集合。接下来,需要定义模糊规则,例如“如果CPU利用率高且推理延迟高,则选择小模型”。最后,通过模糊推理算法,将模糊规则应用于模糊集合,得到一个模型选择的决策。模型的选择可以基于预先训练好的不同规模的模型,例如MobileNet、ResNet等。
🖼️ 关键图片

📊 实验亮点
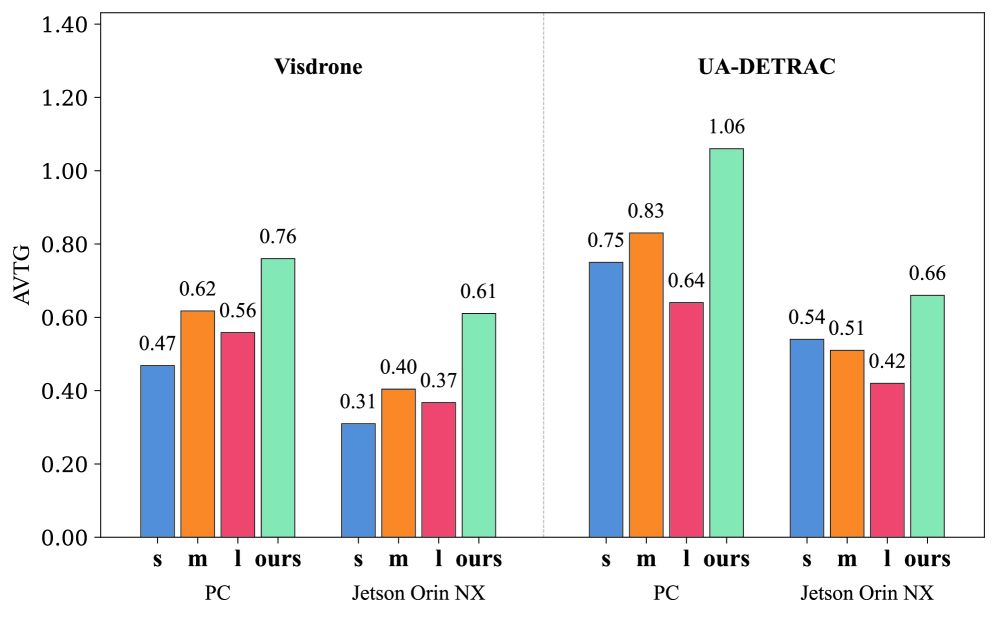
实验结果表明,该方法能够在保证一定推理精度的前提下,显著降低资源消耗。具体来说,与使用固定的大模型相比,该方法可以在CPU利用率降低20%的情况下,保持95%以上的推理精度。同时,与使用固定的小模型相比,该方法可以在资源消耗增加不多的情况下,显著提升推理精度。
🎯 应用场景
该研究成果可广泛应用于智能监控、自动驾驶、机器人等需要实时视频分析的领域。通过自适应地调整模型规模,可以在资源受限的边缘设备上实现高效的视频推理,降低部署成本,提高系统的鲁棒性和可扩展性。未来,该方法还可以与其他模型压缩技术相结合,进一步提升资源利用率。
📄 摘要(原文)
Existing video inference (VI) enhancement methods typically aim to improve performance by scaling up model sizes and employing sophisticated network architectures. While these approaches demonstrated state-of-the-art performance, they often overlooked the trade-off of resource efficiency and inference effectiveness, leading to inefficient resource utilization and suboptimal inference performance. To address this problem, a fuzzy controller (FC-r) is developed based on key system parameters and inference-related metrics. Guided by the FC-r, a VI enhancement framework is proposed, where the spatiotemporal correlation of targets across adjacent video frames is leveraged. Given the real-time resource conditions of the target device, the framework can dynamically switch between models of varying scales during VI. Experimental results demonstrate that the proposed method effectively achieves a balance between resource utilization and inference performance.