XD-MAP: Cross-Modal Domain Adaptation using Semantic Parametric Mapping
作者: Frank Bieder, Hendrik Königshof, Haohao Hu, Fabian Immel, Yinzhe Shen, Jan-Hendrik Pauls, Christoph Stiller
分类: cs.CV, cs.AI, eess.IV
发布日期: 2026-01-20
💡 一句话要点
提出XD-MAP,利用语义参数化映射实现图像到LiDAR的跨模态领域自适应
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨模态学习 领域自适应 语义分割 LiDAR 伪标签
📋 核心要点
- 深度学习模型依赖于特定领域的数据,而获取大量标注的LiDAR数据成本高昂,限制了模型在LiDAR领域的应用。
- XD-MAP利用相机图像的检测结果构建语义参数化地图,生成LiDAR数据的伪标签,从而实现跨模态的知识迁移。
- 实验表明,XD-MAP在2D和3D语义分割任务上显著优于基线方法,无需人工标注即可在LiDAR数据上取得良好性能。
📝 摘要(中文)
在开放世界基础模型达到专用方法性能之前,深度学习模型的有效性仍然严重依赖于数据集的可用性。训练数据不仅要与目标对象类别对齐,还要与传感器特性和模态对齐。为了弥合可用数据集和部署领域之间的差距,领域自适应策略被广泛使用。本文提出了一种新颖的方法,将特定于传感器的知识从图像数据集迁移到完全不同的传感领域LiDAR。我们的方法XD-MAP利用来自相机图像的神经网络检测来创建语义参数化映射。映射元素被建模为在目标域中生成伪标签,而无需任何手动标注。与之前的领域迁移方法不同,我们的方法不需要传感器之间的直接重叠,并且能够将视角范围从前视相机扩展到完整的360度视角。在我们的大规模道路特征数据集上,XD-MAP在2D语义分割方面优于单次基线方法+19.5 mIoU,在2D全景分割方面优于+19.5 PQth,在3D语义分割方面优于+32.3 mIoU。结果表明,我们的方法在没有任何手动标注的情况下,在LiDAR数据上实现了强大的性能。
🔬 方法详解
问题定义:现有深度学习模型在特定传感器和模态的数据上表现良好,但当目标领域缺乏标注数据时,性能会显著下降。尤其是在LiDAR领域,获取大量标注数据成本高昂。因此,如何利用已有的图像数据来提升LiDAR数据的处理能力是一个关键问题。现有领域迁移方法通常需要传感器之间存在直接的重叠区域,限制了其应用范围。
核心思路:XD-MAP的核心思路是利用相机图像的检测结果,构建一个语义参数化地图,该地图能够将图像中的语义信息映射到LiDAR坐标系下。通过这种方式,可以为LiDAR数据生成伪标签,从而实现跨模态的领域自适应。这种方法无需传感器之间的直接重叠,并且能够扩展视角范围。
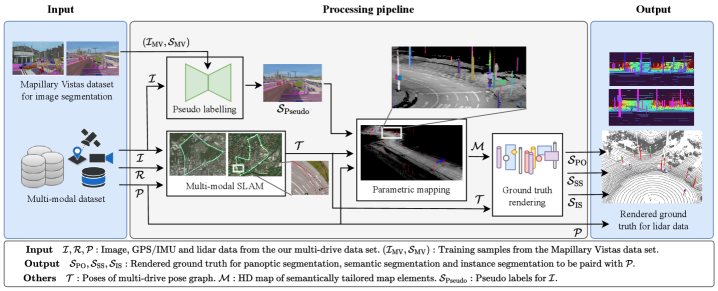
技术框架:XD-MAP的整体框架包括以下几个主要步骤:1) 使用在图像数据上训练的神经网络进行目标检测;2) 基于检测结果构建语义参数化地图,该地图将图像中的目标位置、类别等信息参数化表示;3) 将语义参数化地图投影到LiDAR坐标系下,生成LiDAR数据的伪标签;4) 使用生成的伪标签训练LiDAR领域的模型。
关键创新:XD-MAP的关键创新在于其语义参数化地图的设计。该地图能够将图像中的语义信息以一种紧凑且可迁移的方式表示出来,从而实现跨模态的知识迁移。与传统的领域自适应方法相比,XD-MAP无需传感器之间的直接重叠,并且能够扩展视角范围。此外,该方法完全依赖于自动生成的伪标签,无需任何人工标注。
关键设计:语义参数化地图的设计是该方法的核心。具体来说,每个地图元素都包含目标的位置、类别、置信度等信息。这些信息被参数化表示,以便于在不同的坐标系之间进行转换。在生成伪标签时,需要考虑相机和LiDAR之间的标定参数,以及传感器噪声的影响。损失函数的设计需要保证生成的伪标签的质量,例如可以使用交叉熵损失函数或 focal loss。
🖼️ 关键图片


📊 实验亮点
XD-MAP在道路特征数据集上取得了显著的性能提升。在2D语义分割任务中,相比于单次基线方法,XD-MAP取得了+19.5 mIoU的提升;在2D全景分割任务中,取得了+19.5 PQth的提升;在3D语义分割任务中,取得了+32.3 mIoU的提升。这些结果表明,XD-MAP能够有效地利用图像数据来提升LiDAR数据的处理能力,并且无需任何人工标注。
🎯 应用场景
XD-MAP可应用于自动驾驶、机器人导航、智慧城市等领域。通过利用廉价的相机数据辅助训练,可以降低对昂贵LiDAR数据的依赖,加速相关技术的落地。该方法还可扩展到其他传感器组合,例如毫米波雷达和相机,具有广泛的应用前景。
📄 摘要(原文)
Until open-world foundation models match the performance of specialized approaches, the effectiveness of deep learning models remains heavily dependent on dataset availability. Training data must align not only with the target object categories but also with the sensor characteristics and modalities. To bridge the gap between available datasets and deployment domains, domain adaptation strategies are widely used. In this work, we propose a novel approach to transferring sensor-specific knowledge from an image dataset to LiDAR, an entirely different sensing domain. Our method XD-MAP leverages detections from a neural network on camera images to create a semantic parametric map. The map elements are modeled to produce pseudo labels in the target domain without any manual annotation effort. Unlike previous domain transfer approaches, our method does not require direct overlap between sensors and enables extending the angular perception range from a front-view camera to a full 360 view. On our large-scale road feature dataset, XD-MAP outperforms single shot baseline approaches by +19.5 mIoU for 2D semantic segmentation, +19.5 PQth for 2D panoptic segmentation, and +32.3 mIoU in 3D semantic segmentation. The results demonstrate the effectiveness of our approach achieving strong performance on LiDAR data without any manual labeling.