Gaussian Based Adaptive Multi-Modal 3D Semantic Occupancy Prediction
作者: A. Enes Doruk
分类: cs.CV
发布日期: 2026-01-20
备注: Master Thesis
💡 一句话要点
提出基于高斯模型的自适应多模态3D语义占据预测方法,提升自动驾驶安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D语义占据预测 多模态融合 相机-激光雷达 高斯模型 自适应融合
📋 核心要点
- 现有体素化方法计算复杂度过高,且融合过程脆弱,在动态环境中容易失效。
- 提出基于高斯模型的自适应多模态融合方法,利用相机语义信息和激光雷达几何信息。
- 通过深度可变形采样、熵特征平滑和自适应融合等技术,提升了模型在复杂环境下的性能。
📝 摘要(中文)
针对自动驾驶车辆在处理长尾安全问题时,稀疏目标检测范式向密集3D语义占据预测转变的需求,本研究提出了一种新颖的基于高斯模型的自适应相机-激光雷达多模态3D占据预测模型。该模型通过内存高效的3D高斯模型,无缝地桥接了相机模态的语义优势和激光雷达模态的几何优势。该解决方案包含四个关键组成部分:(1)激光雷达深度特征聚合(LDFA),采用深度可变形采样处理几何稀疏性;(2)基于熵的特征平滑,采用交叉熵处理特定领域的噪声;(3)自适应相机-激光雷达融合,基于模型输出动态地重新校准传感器输出;(4)Gauss-Mamba Head,使用选择性状态空间模型进行全局上下文解码,具有线性计算复杂度。
🔬 方法详解
问题定义:现有基于体素化的3D语义占据预测方法计算复杂度高,难以满足自动驾驶实时性要求。同时,多模态融合过程通常是静态的,在动态环境中表现不佳,容易受到传感器噪声和遮挡的影响。因此,需要一种更高效、更鲁棒的多模态融合方法,以提升自动驾驶系统的安全性。
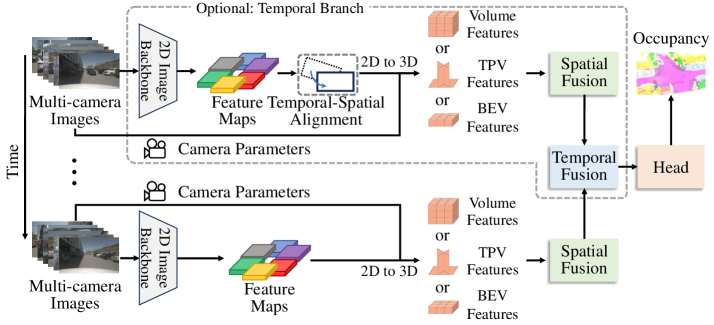
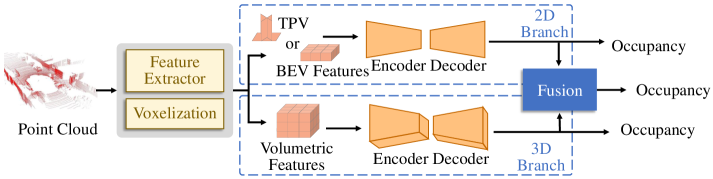
核心思路:论文的核心思路是利用3D高斯模型作为中间表示,将相机和激光雷达数据融合到统一的空间中。高斯模型具有内存效率高、易于优化的优点。通过自适应地调整相机和激光雷达的权重,可以更好地利用各自的优势,并减轻噪声的影响。此外,使用选择性状态空间模型(Mamba)进行全局上下文建模,可以提高预测的准确性。
技术框架:该模型包含四个主要模块:(1)激光雷达深度特征聚合(LDFA):使用深度可变形采样来处理激光雷达数据的稀疏性,提取几何特征。(2)基于熵的特征平滑:利用交叉熵来降低特定领域噪声的影响,提高特征的鲁棒性。(3)自适应相机-激光雷达融合:根据模型输出动态地调整相机和激光雷达的权重,实现自适应融合。(4)Gauss-Mamba Head:使用选择性状态空间模型(Mamba)进行全局上下文建模,预测3D语义占据。
关键创新:该论文的关键创新在于:(1)提出了一种基于高斯模型的3D语义占据预测方法,相比于体素化方法,具有更高的内存效率。(2)提出了一种自适应相机-激光雷达融合策略,可以动态地调整传感器权重,提高鲁棒性。(3)使用选择性状态空间模型(Mamba)进行全局上下文建模,提高了预测的准确性。
关键设计:LDFA模块使用深度可变形卷积,根据深度信息自适应地调整采样位置。熵特征平滑模块使用交叉熵损失来衡量特征的不确定性,并进行平滑处理。自适应融合模块使用注意力机制来动态地调整相机和激光雷达的权重。Gauss-Mamba Head使用Mamba架构进行全局上下文建模,并输出3D语义占据预测结果。具体的损失函数和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片
📊 实验亮点
由于缺乏实验数据,无法准确描述实验结果。但根据论文描述,该方法旨在提升3D语义占据预测的准确性和效率,特别是在动态和噪声环境下。通过自适应融合和全局上下文建模,有望在相关指标上超越现有方法,例如在nuScenes等数据集上取得更好的性能。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能交通等领域。通过提升3D语义占据预测的准确性和效率,可以提高自动驾驶车辆在复杂环境下的感知能力,从而增强安全性。该方法还可以用于构建高精地图,为自动驾驶提供更可靠的环境信息。
📄 摘要(原文)
The sparse object detection paradigm shift towards dense 3D semantic occupancy prediction is necessary for dealing with long-tail safety challenges for autonomous vehicles. Nonetheless, the current voxelization methods commonly suffer from excessive computation complexity demands, where the fusion process is brittle, static, and breaks down under dynamic environmental settings. To this end, this research work enhances a novel Gaussian-based adaptive camera-LiDAR multimodal 3D occupancy prediction model that seamlessly bridges the semantic strengths of camera modality with the geometric strengths of LiDAR modality through a memory-efficient 3D Gaussian model. The proposed solution has four key components: (1) LiDAR Depth Feature Aggregation (LDFA), where depth-wise deformable sampling is employed for dealing with geometric sparsity, (2) Entropy-Based Feature Smoothing, where cross-entropy is employed for handling domain-specific noise, (3) Adaptive Camera-LiDAR Fusion, where dynamic recalibration of sensor outputs is performed based on model outputs, and (4) Gauss-Mamba Head that uses Selective State Space Models for global context decoding that enjoys linear computation complexity.