Vision-Based Natural Language Scene Understanding for Autonomous Driving: An Extended Dataset and a New Model for Traffic Scene Description Generation
作者: Danial Sadrian Zadeh, Otman A. Basir, Behzad Moshiri
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2026-01-20
备注: Under review at Computer Vision and Image Understanding (submitted July 25, 2025)
💡 一句话要点
提出一种基于视觉的自然语言场景理解框架,用于自动驾驶交通场景描述生成。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自动驾驶 场景理解 自然语言描述 混合注意力机制 交通场景 单目视觉 数据集构建
📋 核心要点
- 现有方法在交通场景理解中缺乏对空间布局和语义关系的有效建模,导致场景描述不够准确。
- 提出一种混合注意力机制,增强空间和语义特征的提取,并融合这些特征生成更丰富的场景描述。
- 构建了一个新的数据集,并结合定量评估和人工评估,验证了模型在场景描述生成任务上的有效性。
📝 摘要(中文)
本文提出了一种新颖的框架,用于将单目正面视角的相机图像转换为简洁的自然语言描述,有效地捕捉空间布局、语义关系和与驾驶相关的线索,从而实现自动驾驶车辆对交通场景的准确感知和理解。该模型利用混合注意力机制来增强空间和语义特征的提取,并将这些特征整合以生成上下文丰富且详细的场景描述。为了解决该领域专业数据集可用性有限的问题,本文基于 BDD100K 数据集开发了一个新的数据集,并提供了全面的构建指南。此外,该研究还深入讨论了相关的评估指标,确定了最适合该任务的度量标准。通过使用 CIDEr 和 SPICE 等指标进行的大量定量评估,以及人工判断评估,证明了所提出的模型在新开发的数据集上实现了强大的性能,并有效地实现了其预期目标。
🔬 方法详解
问题定义:自动驾驶需要准确理解交通场景,现有方法难以从单目图像中提取足够丰富的空间和语义信息,导致生成的场景描述不够准确和完整。缺乏专门用于自然语言交通场景描述的数据集也限制了相关研究的进展。
核心思路:利用混合注意力机制,同时关注图像的空间特征和语义特征,从而更全面地理解场景。通过融合这两种特征,生成更具上下文信息和细节的场景描述。同时,构建新的数据集来支持模型训练和评估。
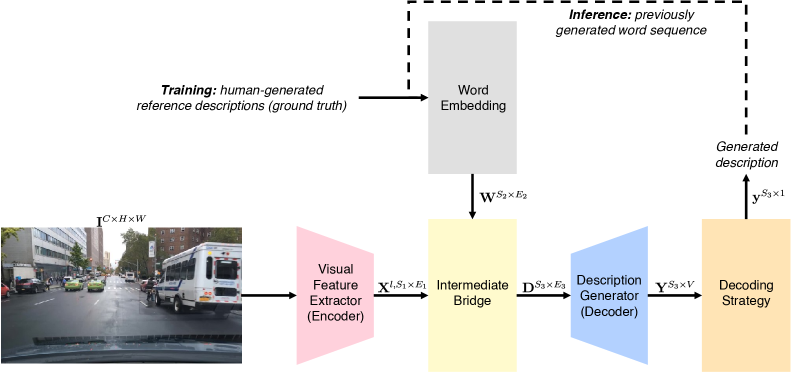
技术框架:该框架接收单目相机图像作为输入,首先使用卷积神经网络提取图像特征。然后,应用混合注意力机制,分别提取空间注意力和语义注意力。空间注意力关注图像中不同区域的空间关系,语义注意力关注不同对象之间的语义关系。将提取的特征融合后,输入到循环神经网络(RNN)中,生成自然语言描述。
关键创新:混合注意力机制是关键创新点,它能够同时关注图像的空间和语义信息,从而更全面地理解场景。与传统的注意力机制相比,混合注意力机制能够更好地捕捉场景中的复杂关系。此外,新构建的数据集也为该领域的研究提供了宝贵的资源。
关键设计:混合注意力机制的具体实现方式未知,论文中可能包含具体的网络结构和参数设置。损失函数可能包括交叉熵损失,用于优化生成的文本序列。数据集的构建指南可能包含详细的标注规范和数据清洗方法。
🖼️ 关键图片


📊 实验亮点
该模型在新建数据集上进行了评估,使用 CIDEr 和 SPICE 等指标进行定量评估,并结合人工评估。实验结果表明,该模型能够生成准确且详细的交通场景描述,优于现有方法。具体的性能提升幅度未知,需要在论文中查找详细的实验数据。
🎯 应用场景
该研究成果可应用于自动驾驶系统,提升车辆对周围环境的感知和理解能力,从而提高行驶安全性。生成的自然语言描述可以用于人机交互,例如向驾驶员或乘客提供场景解释。此外,该技术还可以应用于智能交通管理系统,用于监控和分析交通状况。
📄 摘要(原文)
Traffic scene understanding is essential for enabling autonomous vehicles to accurately perceive and interpret their environment, thereby ensuring safe navigation. This paper presents a novel framework that transforms a single frontal-view camera image into a concise natural language description, effectively capturing spatial layouts, semantic relationships, and driving-relevant cues. The proposed model leverages a hybrid attention mechanism to enhance spatial and semantic feature extraction and integrates these features to generate contextually rich and detailed scene descriptions. To address the limited availability of specialized datasets in this domain, a new dataset derived from the BDD100K dataset has been developed, with comprehensive guidelines provided for its construction. Furthermore, the study offers an in-depth discussion of relevant evaluation metrics, identifying the most appropriate measures for this task. Extensive quantitative evaluations using metrics such as CIDEr and SPICE, complemented by human judgment assessments, demonstrate that the proposed model achieves strong performance and effectively fulfills its intended objectives on the newly developed dataset.