One-Shot Refiner: Boosting Feed-forward Novel View Synthesis via One-Step Diffusion
作者: Yitong Dong, Qi Zhang, Minchao Jiang, Zhiqiang Wu, Qingnan Fan, Ying Feng, Huaqi Zhang, Hujun Bao, Guofeng Zhang
分类: cs.CV
发布日期: 2026-01-20
💡 一句话要点
提出One-Shot Refiner,通过单步扩散提升前馈式新视角合成质量
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 3D高斯溅射 扩散模型 Vision Transformer 图像增强
📋 核心要点
- 现有基于ViT的3DGS方法在新视角合成中受限于ViT计算成本,无法处理高分辨率输入,导致细节不足。
- 论文提出双域细节感知模块和特征引导的扩散网络,结合ViT骨干网络,在高分辨率下保持几何一致性和细节。
- 实验结果表明,该方法在多个数据集上实现了高质量的新视角合成,优于现有方法,尤其是在细节保持方面。
📝 摘要(中文)
本文提出了一种新颖的框架,用于从稀疏图像中进行高保真新视角合成(NVS)。该框架旨在解决基于Vision Transformer (ViT)骨干网络构建的最新前馈3D高斯溅射(3DGS)方法的关键限制。虽然基于ViT的pipeline提供了强大的几何先验,但由于计算成本,它们通常受到低分辨率输入的限制。此外,现有的生成增强方法往往与3D无关,导致跨视角的不一致结构,尤其是在未见区域。为了克服这些挑战,我们设计了一个双域细节感知模块,该模块能够处理高分辨率图像而不受ViT骨干网络的限制,并赋予高斯函数额外的特征来存储高频细节。我们开发了一个特征引导的扩散网络,该网络可以在恢复过程中保留高频细节。我们引入了一种统一的训练策略,可以联合优化基于ViT的几何骨干网络和基于扩散的细化模块。实验表明,我们的方法可以在多个数据集上保持卓越的生成质量。
🔬 方法详解
问题定义:现有基于ViT的3DGS方法虽然具有良好的几何先验,但由于ViT的计算复杂度,通常只能处理低分辨率的输入图像,导致合成的新视角图像缺乏高频细节。此外,现有的图像增强方法通常是3D无关的,容易导致不同视角下结构不一致的问题,尤其是在未见过的区域。
核心思路:论文的核心思路是将基于ViT的几何建模与基于扩散模型的细节增强相结合。利用ViT强大的几何先验来保证整体结构的一致性,同时利用扩散模型生成高频细节,从而克服现有方法的局限性。通过联合训练ViT骨干网络和扩散模型,实现端到端的优化。
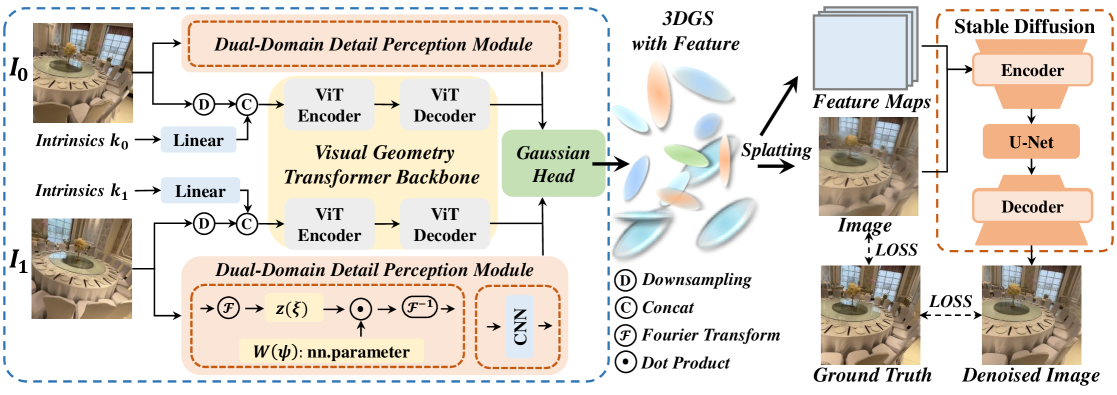
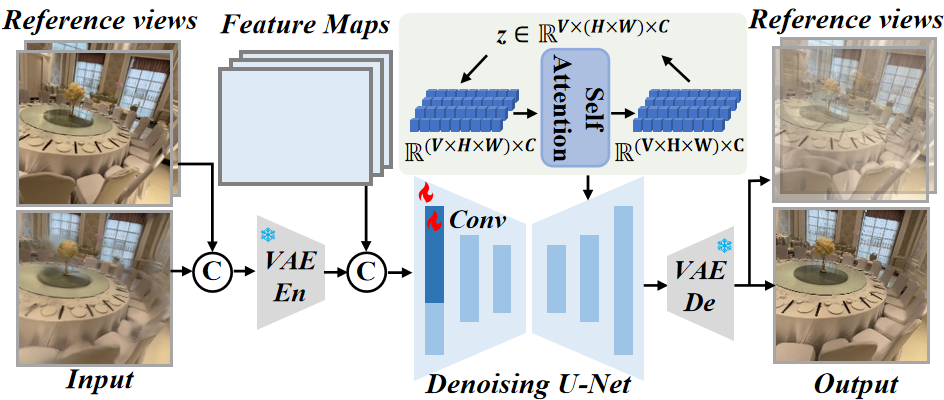
技术框架:该方法包含两个主要模块:基于ViT的几何骨干网络和基于扩散模型的细化模块。几何骨干网络负责从输入图像中提取几何信息,并生成初始的3D高斯表示。细化模块则利用特征引导的扩散网络,对初始的高斯表示进行增强,生成高分辨率、高细节的新视角图像。双域细节感知模块用于处理高分辨率图像,并为高斯函数赋予额外的特征以存储高频细节。
关键创新:该方法的关键创新在于将3D感知的几何建模与2D图像的细节增强相结合,克服了现有方法中几何一致性和细节不足的矛盾。特征引导的扩散网络能够有效地保留和增强高频细节,同时保持视角一致性。双域细节感知模块的设计使得模型能够处理高分辨率输入,而不会受到ViT骨干网络的限制。
关键设计:双域细节感知模块的具体实现方式未知。特征引导的扩散网络可能使用了U-Net结构,并引入了注意力机制来引导细节生成。损失函数可能包括几何损失(例如D-SSIM)和感知损失(例如LPIPS),以保证几何一致性和图像质量。训练策略采用联合优化,同时更新ViT骨干网络和扩散模型的参数。
🖼️ 关键图片

📊 实验亮点
论文提出的方法在多个数据集上取得了优异的性能,能够生成高分辨率、高细节的新视角图像。具体性能数据未知,但论文强调该方法在保持几何一致性的同时,能够显著提升图像的细节质量,优于现有的基于ViT和扩散模型的方法。实验结果表明,该方法能够有效地克服现有方法的局限性。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发、电影制作等领域,能够从少量图像中生成高质量的新视角图像,提升用户体验。例如,在VR/AR应用中,可以利用该技术快速生成用户视角的图像,减少延迟和计算负担。在游戏开发中,可以用于生成逼真的场景和角色。
📄 摘要(原文)
We present a novel framework for high-fidelity novel view synthesis (NVS) from sparse images, addressing key limitations in recent feed-forward 3D Gaussian Splatting (3DGS) methods built on Vision Transformer (ViT) backbones. While ViT-based pipelines offer strong geometric priors, they are often constrained by low-resolution inputs due to computational costs. Moreover, existing generative enhancement methods tend to be 3D-agnostic, resulting in inconsistent structures across views, especially in unseen regions. To overcome these challenges, we design a Dual-Domain Detail Perception Module, which enables handling high-resolution images without being limited by the ViT backbone, and endows Gaussians with additional features to store high-frequency details. We develop a feature-guided diffusion network, which can preserve high-frequency details during the restoration process. We introduce a unified training strategy that enables joint optimization of the ViT-based geometric backbone and the diffusion-based refinement module. Experiments demonstrate that our method can maintain superior generation quality across multiple datasets.