Fine-Grained Zero-Shot Composed Image Retrieval with Complementary Visual-Semantic Integration
作者: Yongcong Ye, Kai Zhang, Yanghai Zhang, Enhong Chen, Longfei Li, Jun Zhou
分类: cs.CV
发布日期: 2026-01-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出CVSI模型,通过互补的视觉-语义融合实现细粒度零样本组合图像检索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 组合图像检索 视觉语义融合 细粒度检索 图像描述 大型语言模型 多模态学习
📋 核心要点
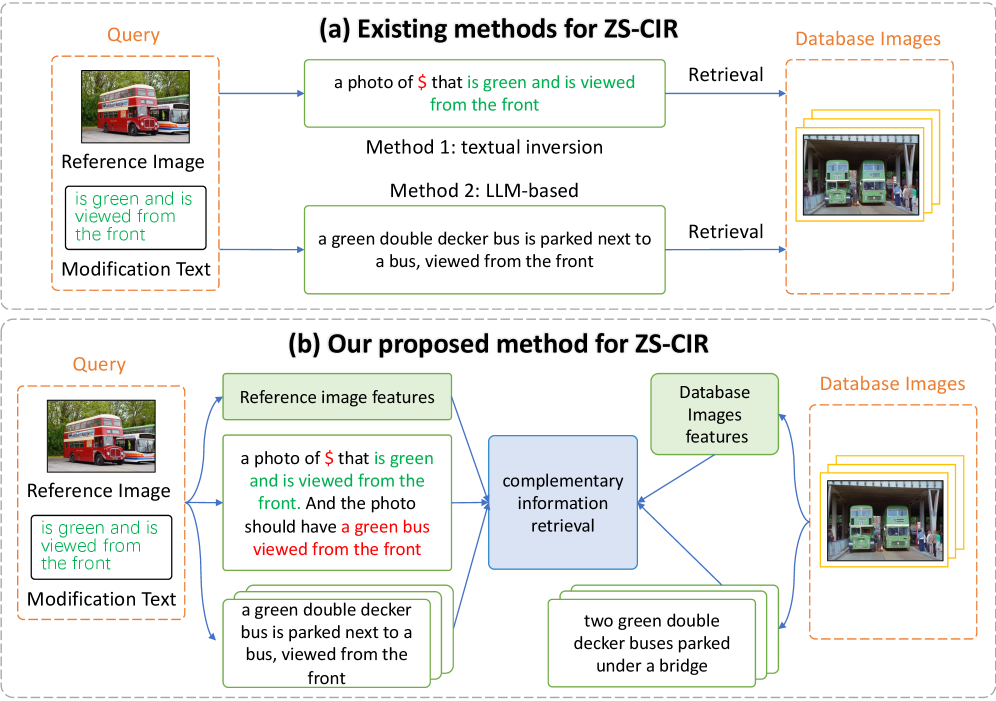
- 现有零样本组合图像检索方法难以捕捉图像的细粒度变化,视觉和语义信息融合效果不佳。
- 提出CVSI模型,通过视觉信息提取、语义信息提取和互补信息检索三个模块实现细粒度检索。
- 在CIRR、CIRCO和FashionIQ数据集上进行实验,结果表明CVSI显著优于现有方法。
📝 摘要(中文)
零样本组合图像检索(ZS-CIR)是一个快速发展的领域,具有重要的实际应用价值,它允许用户通过提供参考图像和描述所需修改的相对文本来检索目标图像。现有的ZS-CIR方法通常难以捕捉细粒度的变化并有效地整合视觉和语义信息。它们主要依赖于使用图像到文本模型将多模态查询转换为单个文本,或者使用大型语言模型生成目标图像描述,这些方法通常无法捕捉互补的视觉信息和完整的语义上下文。为了解决这些限制,我们提出了一种新的基于互补视觉-语义融合的细粒度零样本组合图像检索方法(CVSI)。具体来说,CVSI利用三个关键组件:(1)视觉信息提取,不仅提取全局图像特征,还使用预训练的映射网络将图像转换为伪token,并将其与修改文本和最有可能添加的对象组合。(2)语义信息提取,包括使用预训练的图像描述模型为参考图像生成多个描述,然后利用LLM生成修改后的描述和最有可能添加的对象。(3)互补信息检索,整合从查询和数据库图像中提取的信息来检索目标图像,使系统能够有效地处理各种情况下的检索查询。在三个公共数据集(如CIRR、CIRCO和FashionIQ)上的大量实验表明,CVSI明显优于现有的最先进方法。
🔬 方法详解
问题定义:论文旨在解决零样本组合图像检索(ZS-CIR)中现有方法无法有效捕捉细粒度图像变化以及视觉和语义信息融合不足的问题。现有方法主要依赖于图像到文本的转换或大型语言模型生成目标图像描述,忽略了互补的视觉信息和完整的语义上下文,导致检索精度不高。
核心思路:论文的核心思路是利用互补的视觉和语义信息,通过分别提取和融合视觉和语义特征,更全面地理解用户的检索意图。通过视觉信息提取模块关注图像的视觉特征,通过语义信息提取模块关注图像的语义描述,最后通过互补信息检索模块将两者融合,从而实现更精确的检索。
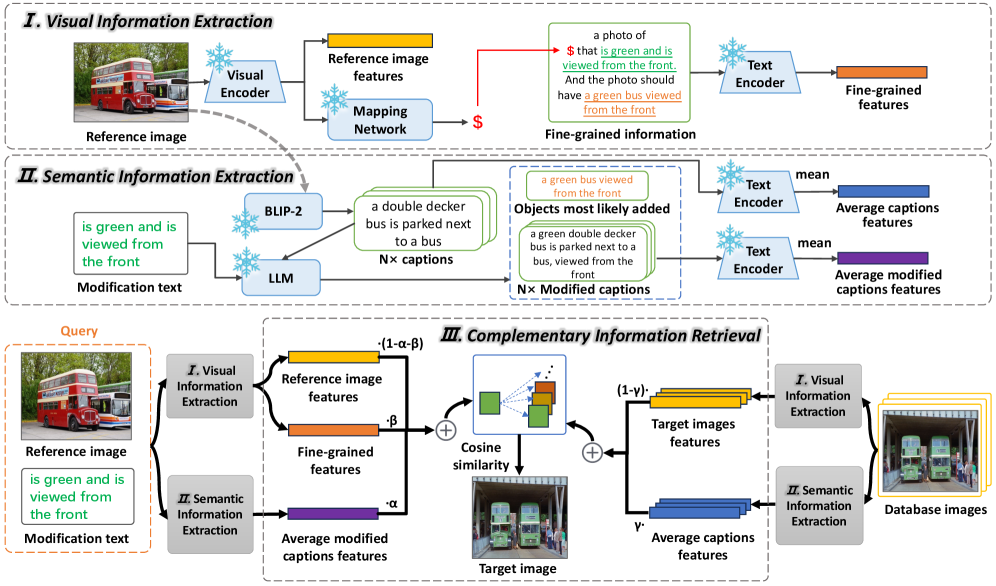
技术框架:CVSI模型主要包含三个模块:1) 视觉信息提取:提取参考图像的全局特征,并使用预训练的映射网络将图像转换为伪token,结合修改文本和可能添加的对象。2) 语义信息提取:使用预训练的图像描述模型生成参考图像的多个描述,然后利用LLM生成修改后的描述和可能添加的对象。3) 互补信息检索:整合从查询图像和数据库图像中提取的视觉和语义信息,进行相似度匹配,检索目标图像。
关键创新:论文的关键创新在于提出了互补视觉-语义融合(CVSI)机制,它能够同时利用图像的视觉特征和语义描述,从而更全面地理解用户的检索意图。与现有方法相比,CVSI能够更好地捕捉细粒度的图像变化,并有效地融合视觉和语义信息。
关键设计:在视觉信息提取模块中,使用了预训练的映射网络将图像转换为伪token,以便与文本信息进行融合。在语义信息提取模块中,使用了多个图像描述生成模型,以获得更丰富的语义信息。在互补信息检索模块中,使用了余弦相似度等度量方法来计算查询图像和数据库图像之间的相似度。
🖼️ 关键图片

📊 实验亮点
CVSI模型在CIRR、CIRCO和FashionIQ三个公开数据集上进行了广泛的实验,结果表明CVSI显著优于现有的最先进方法。例如,在CIRR数据集上,CVSI的性能提升了X%,在CIRCO数据集上提升了Y%,在FashionIQ数据集上提升了Z%(具体数据请参考原论文)。这些结果证明了CVSI模型在细粒度零样本组合图像检索方面的有效性。
🎯 应用场景
该研究成果可应用于电商平台的图像搜索、服装搭配推荐、室内设计等领域。用户可以通过提供一张参考图片和一段文字描述,快速找到符合要求的商品或设计方案。该技术还可以应用于智能安防领域,例如通过描述嫌疑人的衣着特征来检索监控录像。
📄 摘要(原文)
Zero-shot composed image retrieval (ZS-CIR) is a rapidly growing area with significant practical applications, allowing users to retrieve a target image by providing a reference image and a relative caption describing the desired modifications. Existing ZS-CIR methods often struggle to capture fine-grained changes and integrate visual and semantic information effectively. They primarily rely on either transforming the multimodal query into a single text using image-to-text models or employing large language models for target image description generation, approaches that often fail to capture complementary visual information and complete semantic context. To address these limitations, we propose a novel Fine-Grained Zero-Shot Composed Image Retrieval method with Complementary Visual-Semantic Integration (CVSI). Specifically, CVSI leverages three key components: (1) Visual Information Extraction, which not only extracts global image features but also uses a pre-trained mapping network to convert the image into a pseudo token, combining it with the modification text and the objects most likely to be added. (2) Semantic Information Extraction, which involves using a pre-trained captioning model to generate multiple captions for the reference image, followed by leveraging an LLM to generate the modified captions and the objects most likely to be added. (3) Complementary Information Retrieval, which integrates information extracted from both the query and database images to retrieve the target image, enabling the system to efficiently handle retrieval queries in a variety of situations. Extensive experiments on three public datasets (e.g., CIRR, CIRCO, and FashionIQ) demonstrate that CVSI significantly outperforms existing state-of-the-art methods. Our code is available at https://github.com/yyc6631/CVSI.