Weather-R1: Logically Consistent Reinforcement Fine-Tuning for Multimodal Reasoning in Meteorology
作者: Kaiyu Wu, Pucheng Han, Hualong Zhang, Naigeng Wu, Keze Wang
分类: cs.CV
发布日期: 2026-01-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出LoCo-RFT,解决气象领域多模态推理中逻辑不一致问题,并构建Weather-R1模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 视觉语言模型 强化微调 逻辑一致性 气象学 领域自适应 WeatherQA基准
📋 核心要点
- 现有视觉语言模型在气象领域应用受限于领域知识不足和推理逻辑不一致,导致模型推理结果与最终答案矛盾。
- 提出逻辑一致性强化微调(LoCo-RFT),通过引入逻辑一致性奖励,鼓励模型进行符合逻辑的推理,解决自相矛盾问题。
- 构建WeatherQA基准并训练Weather-R1模型,实验结果表明,Weather-R1在WeatherQA上性能提升9.8%,优于现有方法。
📝 摘要(中文)
视觉语言模型(VLMs)在推理能力上不断进步,但其在气象领域的应用受到领域差距和推理忠实度差距的限制。主流的强化微调(RFT)可能导致自相矛盾的推理(Self-Contra),即模型的推理与其最终答案相矛盾,这在高风险领域是不可接受的。为了解决这些挑战,我们构建了WeatherQA,这是一个新的气象领域多模态推理基准。我们还提出了逻辑一致性强化微调(LoCo-RFT),通过引入逻辑一致性奖励来解决Self-Contra问题。此外,我们推出了Weather-R1,据我们所知,这是第一个在气象领域具有逻辑忠实性的推理VLM。实验表明,Weather-R1在WeatherQA上的性能比基线提高了9.8个百分点,优于监督微调和RFT,甚至超过了原始的Qwen2.5-VL-32B。这些结果突出了LoCo-RFT的有效性和Weather-R1的优越性。我们的基准和代码可在https://github.com/Marcowky/Weather-R1上找到。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)在气象领域应用时,由于领域知识不足和推理逻辑不一致导致的“自相矛盾推理”(Self-Contra)问题。现有强化微调(RFT)方法虽然能提升VLM性能,但无法保证推理过程的逻辑一致性,在高风险的气象领域,这种逻辑错误是不可接受的。
核心思路:论文的核心思路是引入逻辑一致性奖励,在强化微调过程中引导模型进行逻辑上合理的推理。通过显式地奖励逻辑一致的推理路径,惩罚自相矛盾的推理,从而提高模型推理的可靠性和可信度。这种方法旨在弥合模型推理过程和最终答案之间的差距,确保二者在逻辑上保持一致。
技术框架:整体框架包括三个主要部分:1)构建气象领域多模态推理基准WeatherQA;2)提出逻辑一致性强化微调(LoCo-RFT)方法;3)训练并评估Weather-R1模型。LoCo-RFT在标准RFT的基础上,增加了一个逻辑一致性奖励模块,该模块评估模型推理过程的逻辑合理性,并根据评估结果调整奖励信号。模型通过最大化累积奖励(包括标准奖励和逻辑一致性奖励)进行训练。
关键创新:最重要的技术创新点是逻辑一致性奖励的引入。与传统的强化微调只关注最终答案的正确性不同,LoCo-RFT同时关注推理过程的逻辑合理性。这种方法能够有效地解决自相矛盾推理问题,提高模型推理的可靠性和可解释性。此外,WeatherQA基准的构建也为气象领域的多模态推理研究提供了新的资源。
关键设计:逻辑一致性奖励的设计是关键。具体实现方式未知,但可以推测其可能涉及到对模型推理路径的分析,例如,检查推理步骤之间是否存在逻辑冲突,或者验证推理结果是否与已知的气象规律相符。奖励函数的具体形式和参数设置对最终性能有重要影响,需要在实验中进行仔细调整。此外,WeatherQA基准的构建也需要精心设计,以确保其能够有效地评估模型的推理能力和逻辑一致性。
🖼️ 关键图片
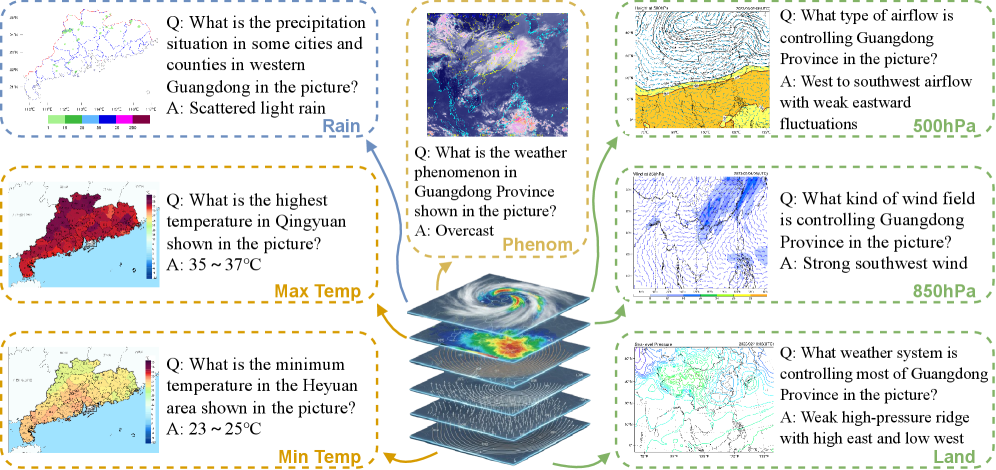
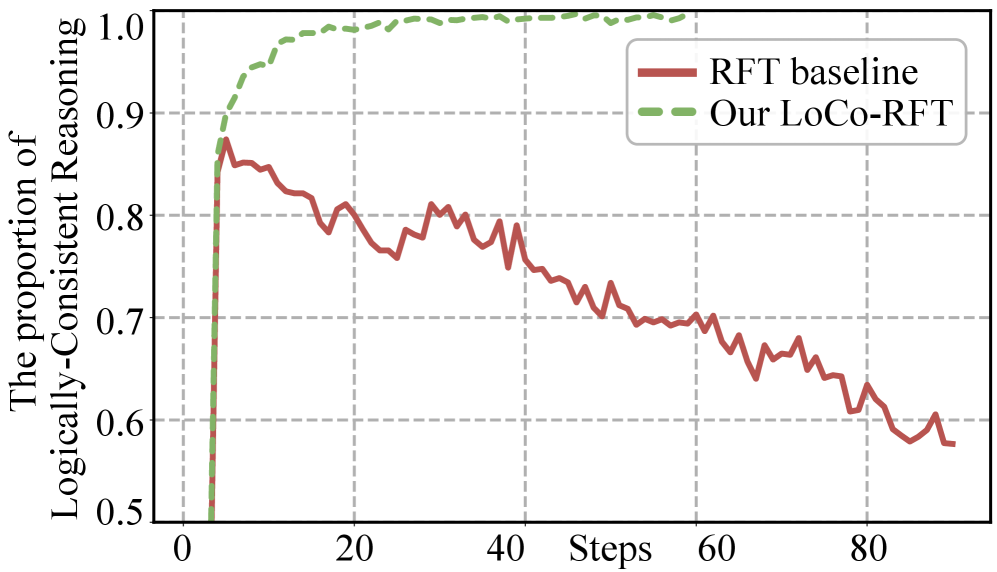
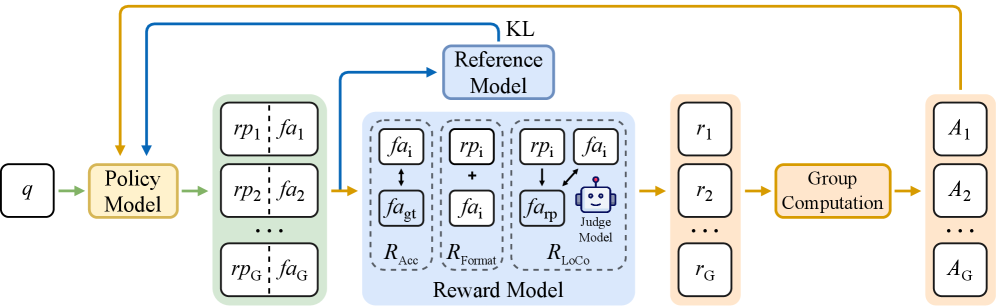
📊 实验亮点
Weather-R1在WeatherQA基准测试中,相较于基线模型性能提升了9.8个百分点,并且优于监督微调和传统的强化微调方法。更重要的是,Weather-R1甚至超越了原始的Qwen2.5-VL-32B模型,证明了LoCo-RFT的有效性和Weather-R1的优越性。这些结果表明,在气象领域,逻辑一致性对于提升视觉语言模型的推理能力至关重要。
🎯 应用场景
该研究成果可应用于智能气象服务、灾害预警、农业气象等领域。通过提高气象领域视觉语言模型的推理能力和逻辑一致性,可以为决策者提供更可靠、更准确的气象信息,从而提高气象服务的质量和效率,减少气象灾害带来的损失。未来,该技术还可扩展到其他高风险领域,如医疗诊断、金融风险评估等。
📄 摘要(原文)
While Vision Language Models (VLMs) show advancing reasoning capabilities, their application in meteorology is constrained by a domain gap and a reasoning faithfulness gap. Specifically, mainstream Reinforcement Fine-Tuning (RFT) can induce Self-Contradictory Reasoning (Self-Contra), where the model's reasoning contradicts its final answer, which is unacceptable in such a high-stakes domain. To address these challenges, we construct WeatherQA, a novel multimodal reasoning benchmark in meteorology. We also propose Logically Consistent Reinforcement Fine-Tuning (LoCo-RFT), which resolves Self-Contra by introducing a logical consistency reward. Furthermore, we introduce Weather-R1, the first reasoning VLM with logical faithfulness in meteorology, to the best of our knowledge. Experiments demonstrate that Weather-R1 improves performance on WeatherQA by 9.8 percentage points over the baseline, outperforming Supervised Fine-Tuning and RFT, and even surpassing the original Qwen2.5-VL-32B. These results highlight the effectiveness of our LoCo-RFT and the superiority of Weather-R1. Our benchmark and code are available at https://github.com/Marcowky/Weather-R1.