Glance-or-Gaze: Incentivizing LMMs to Adaptively Focus Search via Reinforcement Learning
作者: Hongbo Bai, Yujin Zhou, Yile Wu, Chi-Min Chan, Pengcheng Wen, Kunhao Pan, Sirui Han, Yike Guo
分类: cs.CV, cs.AI
发布日期: 2026-01-20
💡 一句话要点
提出Glance-or-Gaze框架,通过强化学习自适应地聚焦搜索,提升LMMs在知识密集型视觉问答中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉问答 强化学习 知识增强 主动视觉 选择性注意 大型多模态模型
📋 核心要点
- 现有LMMs在处理知识密集型视觉查询时,由于静态知识和整图检索引入的冗余信息,效果不佳。
- GoG框架通过选择性注视机制,动态决定是浏览全局还是聚焦高价值区域,过滤无关信息,实现主动视觉规划。
- GoG采用双阶段训练,包括监督微调的行为对齐和强化学习的复杂性自适应,在多个基准测试中达到SOTA。
📝 摘要(中文)
大型多模态模型(LMMs)在视觉理解方面取得了显著成功,但由于静态参数知识,它们在处理涉及长尾实体或不断发展的信息的知识密集型查询时表现不佳。最近的搜索增强方法试图解决这一限制,但现有方法依赖于不加区分的整图检索,引入了大量的视觉冗余和噪声,并且缺乏深度迭代反思,限制了它们在复杂视觉查询中的有效性。为了克服这些挑战,我们提出了Glance-or-Gaze (GoG),一个完全自主的框架,它从被动感知转变为主动视觉规划。GoG引入了一种选择性注视机制,动态地选择是浏览全局上下文还是注视高价值区域,从而在检索之前过滤掉不相关的信息。我们设计了一个双阶段训练策略:通过监督微调进行反思性GoG行为对齐,灌输基本的GoG范式,而复杂性自适应强化学习进一步增强了模型通过迭代推理处理复杂查询的能力。在六个基准测试上的实验证明了最先进的性能。消融研究证实,选择性注视和复杂性自适应强化学习对于有效的视觉搜索都是必不可少的。我们将很快发布我们的数据和模型,以供进一步探索。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在处理知识密集型视觉查询时遇到的困难。现有方法通常采用整图检索,导致引入大量视觉冗余和噪声,并且缺乏迭代反思能力,无法有效处理复杂查询。这些问题限制了LMMs在需要外部知识或处理长尾实体时的性能。
核心思路:论文的核心思路是让LMMs具备主动视觉规划能力,使其能够根据查询内容动态地选择是“浏览”(Glance)全局上下文,还是“注视”(Gaze)高价值区域。通过这种选择性注视机制,模型可以在检索之前过滤掉不相关的信息,从而提高检索效率和准确性。这种设计模拟了人类在视觉搜索中的注意力机制。
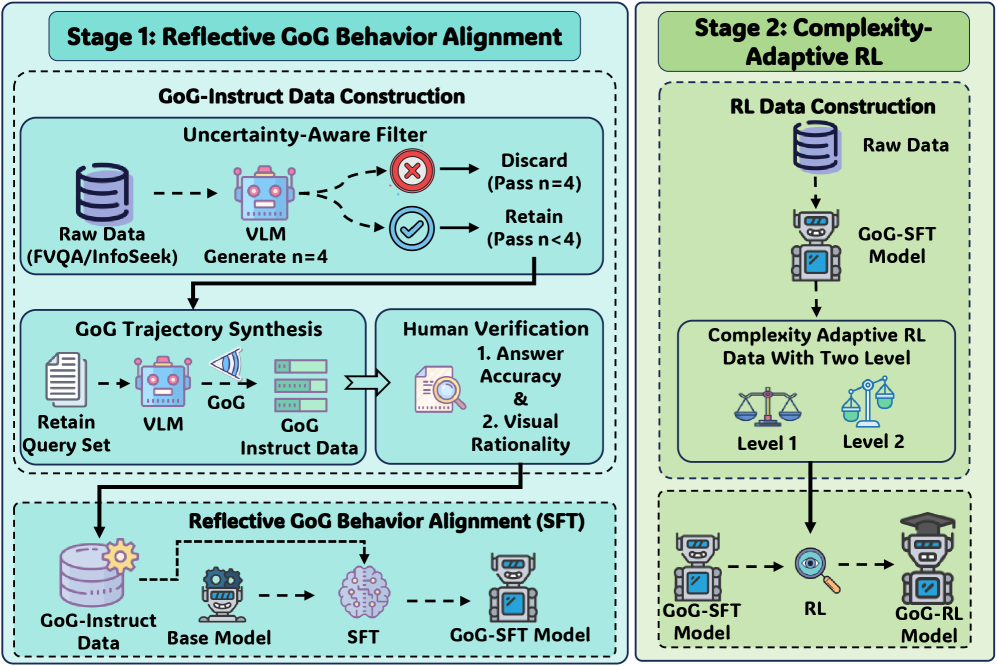
技术框架:GoG框架包含以下主要模块:1) 选择性注视模块:根据当前状态(包括查询和视觉信息)决定是进行全局浏览还是局部注视。2) 检索模块:根据选择性注视的结果,从外部知识库中检索相关信息。3) 推理模块:将检索到的信息与原始视觉信息和查询进行融合,进行迭代推理。4) 决策模块:根据推理结果,更新状态并重复上述过程,直到达到停止条件。整个框架通过强化学习进行训练,以优化决策策略。
关键创新:GoG的关键创新在于引入了选择性注视机制,将被动感知转变为主动视觉规划。与现有方法中不加区分的整图检索相比,GoG能够根据查询内容动态地调整注意力焦点,从而更有效地利用外部知识。此外,GoG采用双阶段训练策略,首先通过监督微调进行行为对齐,然后通过强化学习进行复杂性自适应,进一步提高了模型的性能。
关键设计:GoG的关键设计包括:1) 选择性注视的决策策略:使用强化学习训练一个策略网络,根据当前状态选择“浏览”或“注视”动作。奖励函数的设计至关重要,需要平衡检索效率和准确性。2) 复杂性自适应强化学习:根据查询的复杂程度动态调整训练策略,使模型能够更好地处理不同难度的任务。3) 双阶段训练策略:首先通过监督微调学习GoG的基本行为模式,然后通过强化学习进行优化,避免了从头开始训练的困难。
🖼️ 关键图片

📊 实验亮点
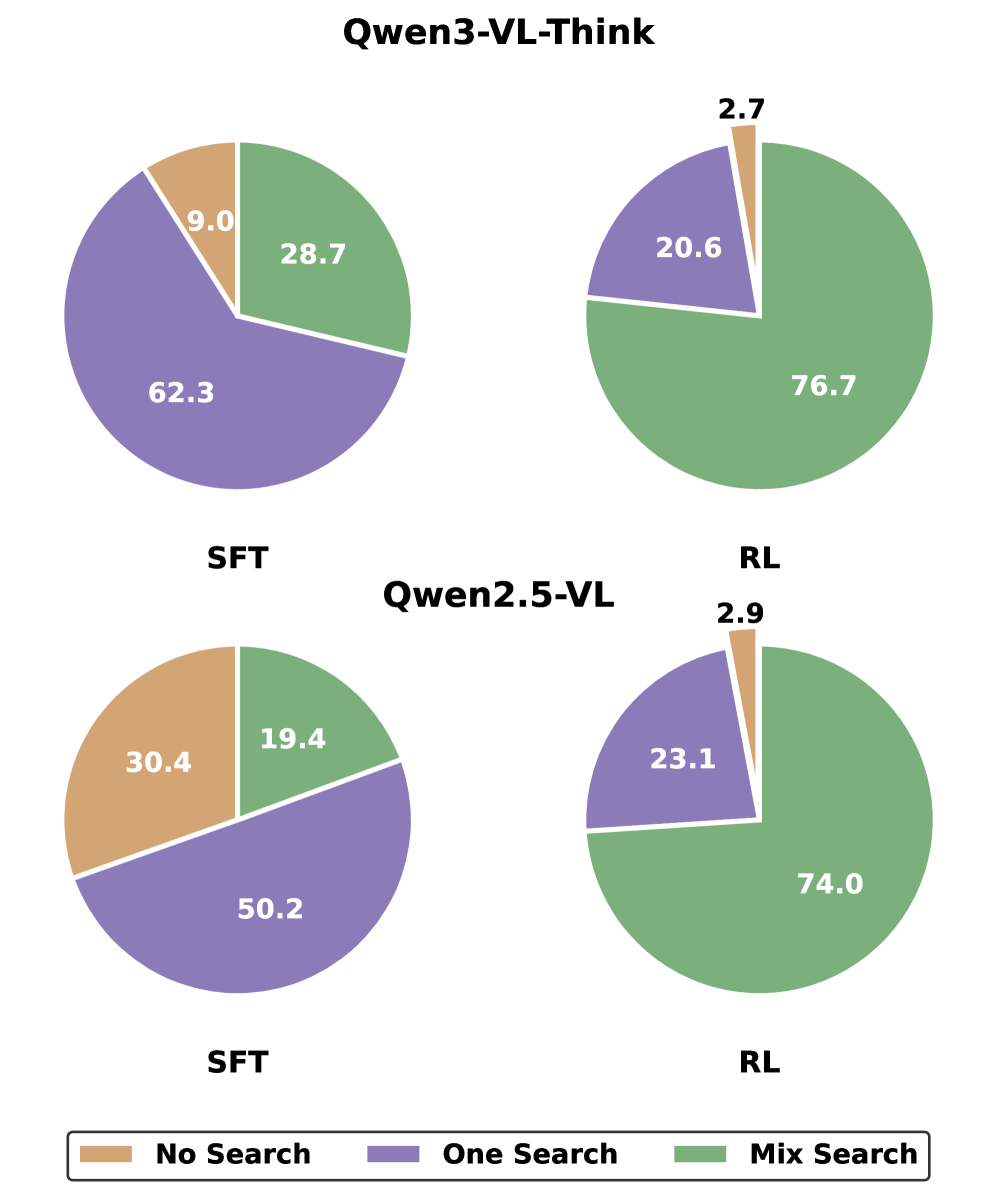
实验结果表明,GoG在六个基准测试中均取得了SOTA性能。消融研究证实,选择性注视和复杂性自适应强化学习对于GoG的有效性至关重要。具体性能数据未知,但摘要强调了显著的性能提升。
🎯 应用场景
GoG框架可应用于各种需要知识增强的视觉任务,例如视觉问答、图像描述、目标检测等。它在医疗诊断、智能客服、自动驾驶等领域具有潜在的应用价值,可以帮助LMMs更好地理解复杂场景,并做出更准确的决策。该研究有望推动LMMs在实际应用中的普及。
📄 摘要(原文)
Large Multimodal Models (LMMs) have achieved remarkable success in visual understanding, yet they struggle with knowledge-intensive queries involving long-tail entities or evolving information due to static parametric knowledge. Recent search-augmented approaches attempt to address this limitation, but existing methods rely on indiscriminate whole-image retrieval that introduces substantial visual redundancy and noise, and lack deep iterative reflection, limiting their effectiveness on complex visual queries. To overcome these challenges, we propose Glance-or-Gaze (GoG), a fully autonomous framework that shifts from passive perception to active visual planning. GoG introduces a Selective Gaze mechanism that dynamically chooses whether to glance at global context or gaze into high-value regions, filtering irrelevant information before retrieval. We design a dual-stage training strategy: Reflective GoG Behavior Alignment via supervised fine-tuning instills the fundamental GoG paradigm, while Complexity-Adaptive Reinforcement Learning further enhances the model's capability to handle complex queries through iterative reasoning. Experiments across six benchmarks demonstrate state-of-the-art performance. Ablation studies confirm that both Selective Gaze and complexity-adaptive RL are essential for effective visual search. We will release our data and models for further exploration soon.