Hierarchical Long Video Understanding with Audiovisual Entity Cohesion and Agentic Search
作者: Xinlei Yin, Xiulian Peng, Xiao Li, Zhiwei Xiong, Yan Lu
分类: cs.CV, cs.AI, cs.IR
发布日期: 2026-01-20
💡 一句话要点
提出HAVEN框架,通过视听实体关联和Agent搜索实现层级长视频理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 视听融合 实体关联 分层索引 Agent搜索 多模态学习 视频分析
📋 核心要点
- 现有长视频理解方法依赖简单分块,导致信息碎片化和全局连贯性丧失。
- HAVEN框架通过整合视听实体关联和分层视频索引,实现连贯和全面的推理。
- 实验表明,HAVEN在LVBench上取得了SOTA结果,尤其在推理方面表现突出。
📝 摘要(中文)
长视频理解因其极长的上下文窗口对视觉-语言模型提出了重大挑战。现有依赖于简单分块策略和检索增强生成的方法,通常会遭受信息碎片化和全局一致性丧失的问题。我们提出了HAVEN,一个统一的长视频理解框架,通过整合视听实体关联和带有Agent搜索的分层视频索引,实现连贯和全面的推理。首先,我们通过整合跨视觉和听觉流的实体级表示来保持语义一致性,同时将内容组织成一个结构化的层次,跨越全局摘要、场景、片段和实体级别。然后,我们采用Agent搜索机制来实现跨这些层的动态检索和推理,从而促进连贯的叙事重建和细粒度的实体跟踪。大量实验表明,我们的方法实现了良好的时间连贯性、实体一致性和检索效率,在LVBench上以84.1%的总体准确率建立了新的state-of-the-art。值得注意的是,它在具有挑战性的推理类别中取得了出色的表现,达到了80.1%。这些结果突出了结构化的多模态推理对于全面和上下文一致的长视频理解的有效性。
🔬 方法详解
问题定义:长视频理解任务面临着上下文窗口过长的问题,现有方法如简单分块和检索增强生成,难以保持信息的全局连贯性和实体一致性,导致推理能力下降。现有方法无法有效利用长视频中的多模态信息,特别是视听信息之间的关联。
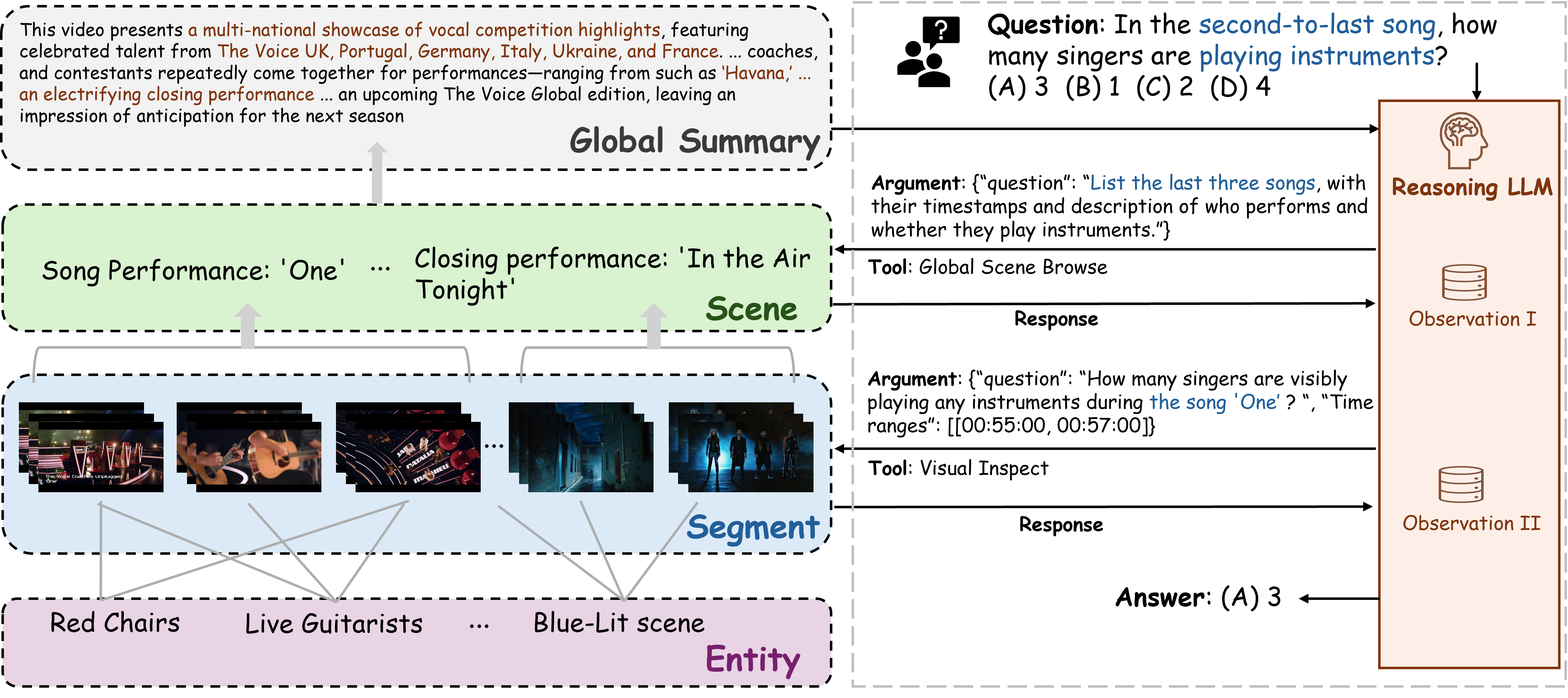
核心思路:HAVEN框架的核心思路是构建一个分层的视频表示,并利用视听实体关联来保持语义一致性。通过Agent搜索机制,动态地在不同层次的表示中进行检索和推理,从而实现连贯的叙事重建和细粒度的实体跟踪。这种方法旨在克服信息碎片化问题,提升长视频理解的整体性能。
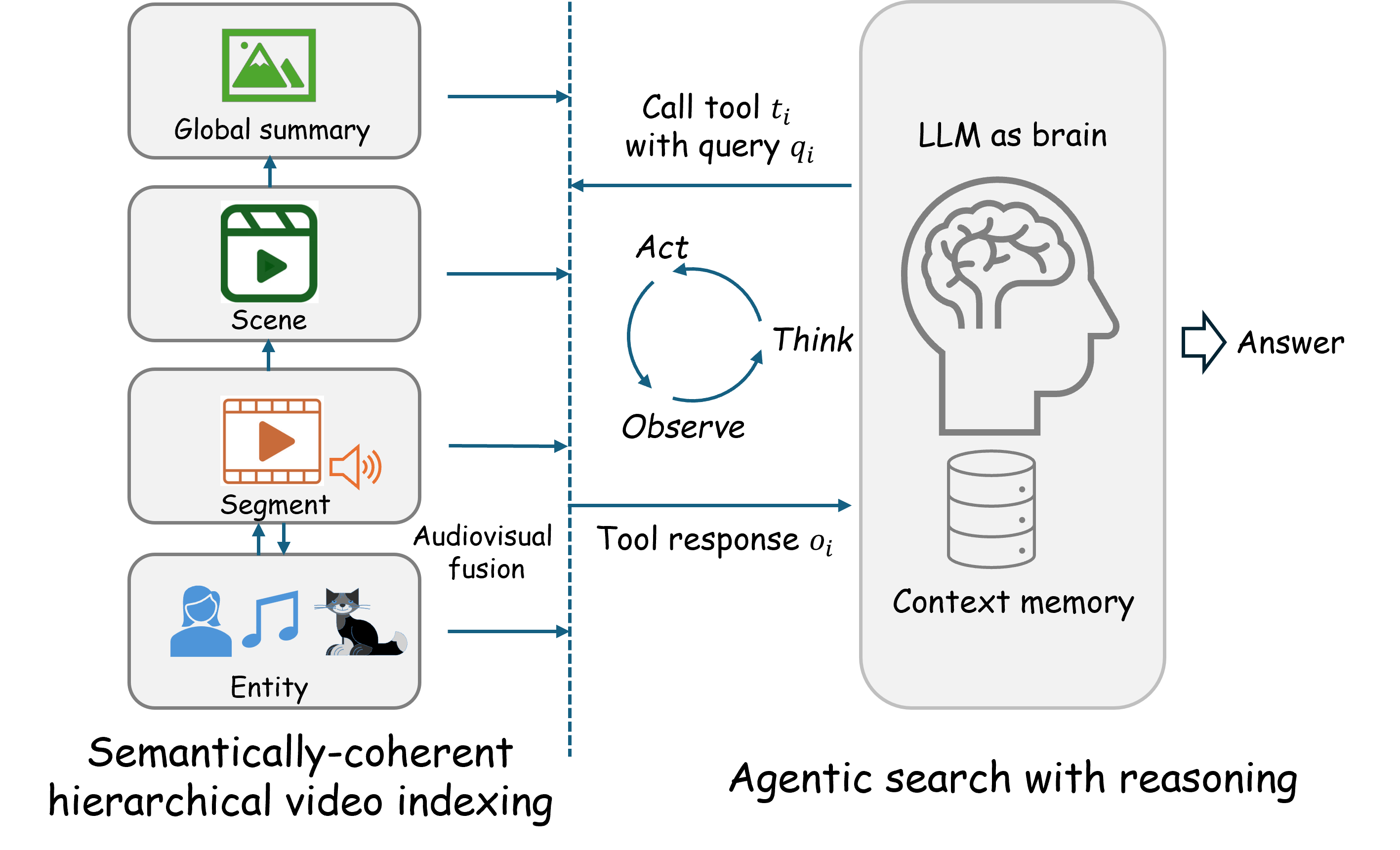
技术框架:HAVEN框架包含以下几个主要模块:1) 视听实体编码器:用于提取视频和音频中的实体级特征,并建立它们之间的关联。2) 分层视频索引:将视频内容组织成一个结构化的层次,包括全局摘要、场景、片段和实体级别。3) Agent搜索机制:允许Agent在不同层次的索引中进行动态检索和推理,以找到与当前任务相关的信息。4) 解码器:用于生成最终的理解结果。
关键创新:HAVEN的关键创新在于:1) 视听实体关联:通过显式地建模视频和音频中的实体之间的关系,来提高语义一致性。2) Agent搜索机制:允许动态地在分层视频表示中进行检索和推理,从而更好地利用上下文信息。3) 统一框架:将视听信息、分层表示和Agent搜索整合到一个统一的框架中,实现了端到端的长视频理解。
关键设计:HAVEN框架的具体技术细节包括:1) 视听实体编码器可以使用预训练的视觉和音频模型,例如CLIP和Whisper。2) 分层视频索引可以使用树状结构或图结构来表示。3) Agent搜索机制可以使用强化学习或基于规则的方法来实现。4) 损失函数可以包括交叉熵损失、对比损失和一致性损失等。
🖼️ 关键图片
📊 实验亮点
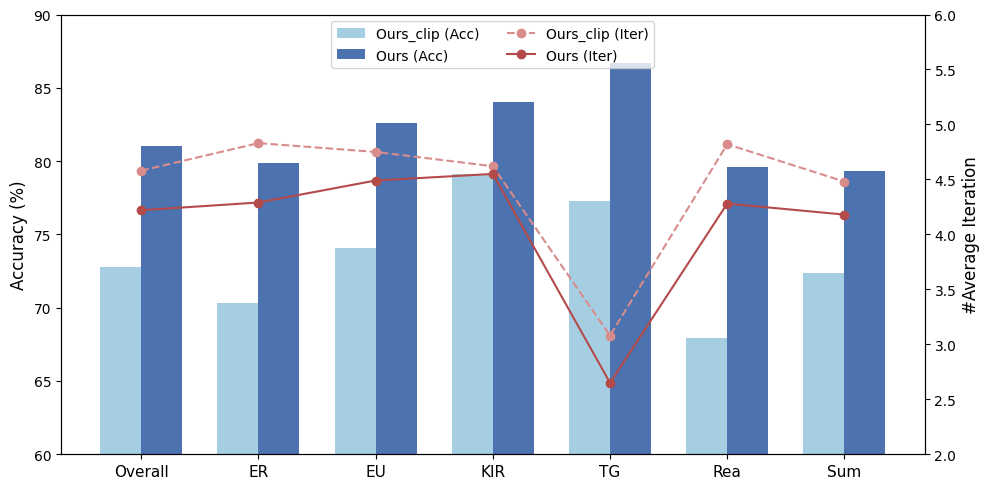
HAVEN在LVBench数据集上取得了显著的性能提升,总体准确率达到84.1%,建立了新的SOTA。尤其在推理类别中,准确率高达80.1%,表明HAVEN在复杂推理任务中具有强大的能力。实验结果验证了视听实体关联和Agent搜索机制的有效性,以及分层视频表示对于长视频理解的重要性。
🎯 应用场景
HAVEN框架可应用于视频监控、智能安防、在线教育、电影分析等领域。通过对长视频内容的深入理解,可以实现更智能的事件检测、行为分析、内容推荐和信息检索,具有广阔的应用前景和实际价值,并可能推动长视频内容分析和理解的进一步发展。
📄 摘要(原文)
Long video understanding presents significant challenges for vision-language models due to extremely long context windows. Existing solutions relying on naive chunking strategies with retrieval-augmented generation, typically suffer from information fragmentation and a loss of global coherence. We present HAVEN, a unified framework for long-video understanding that enables coherent and comprehensive reasoning by integrating audiovisual entity cohesion and hierarchical video indexing with agentic search. First, we preserve semantic consistency by integrating entity-level representations across visual and auditory streams, while organizing content into a structured hierarchy spanning global summary, scene, segment, and entity levels. Then we employ an agentic search mechanism to enable dynamic retrieval and reasoning across these layers, facilitating coherent narrative reconstruction and fine-grained entity tracking. Extensive experiments demonstrate that our method achieves good temporal coherence, entity consistency, and retrieval efficiency, establishing a new state-of-the-art with an overall accuracy of 84.1% on LVBench. Notably, it achieves outstanding performance in the challenging reasoning category, reaching 80.1%. These results highlight the effectiveness of structured, multimodal reasoning for comprehensive and context-consistent understanding of long-form videos.