VIAFormer: Voxel-Image Alignment Transformer for High-Fidelity Voxel Refinement
作者: Tiancheng Fang, Bowen Pan, Lingxi Chen, Jiangjing Lyu, Chengfei Lyu, Chaoyue Niu, Fan Wu
分类: cs.CV
发布日期: 2026-01-20 (更新: 2026-01-21)
💡 一句话要点
提出VIAFormer,用于多视角图像引导下的高保真体素精细化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 体素精细化 多视角重建 Transformer 跨模态融合 3D重建 图像索引 校正流
📋 核心要点
- 现有方法难以有效利用多视角图像信息来修复体素数据中的噪声和不完整性,尤其是在严重损坏或真实伪影存在的情况下。
- VIAFormer通过图像索引建立2D图像tokens与3D空间之间的显式对应关系,并利用校正流目标学习直接的体素精细化轨迹。
- 实验结果表明,VIAFormer在合成数据和真实数据上均取得了显著的性能提升,为体素方法在3D创建流程中的应用提供了可能。
📝 摘要(中文)
本文提出了一种体素-图像对齐Transformer模型VIAFormer,用于多视角条件下的体素精细化任务,即利用校准后的多视角图像作为指导,修复不完整且带有噪声的体素。其有效性源于协同设计:一个为2D图像tokens提供显式3D空间基础的图像索引,一个学习直接体素精细化轨迹的校正流目标,以及一个实现鲁棒跨模态融合的混合流Transformer。实验表明,VIAFormer在校正由强大的视觉基础模型获得的体素形状上的严重合成损坏和真实伪影方面,建立了一个新的技术水平。除了基准测试之外,我们还展示了VIAFormer作为真实世界3D创建管道中实用且可靠的桥梁,为基于体素的方法在大模型、大数据浪潮中蓬勃发展铺平了道路。
🔬 方法详解
问题定义:论文旨在解决多视角图像引导下的体素精细化问题。现有方法在利用多视角图像信息方面存在不足,难以有效地修复体素数据中的噪声和不完整性,尤其是在面对由强大的视觉基础模型产生的、带有严重损坏或真实伪影的体素形状时,性能会显著下降。
核心思路:论文的核心思路是设计一个能够有效对齐体素和图像信息的Transformer模型。通过建立图像tokens与3D空间之间的显式对应关系,并学习直接的体素精细化轨迹,从而实现高保真度的体素修复。
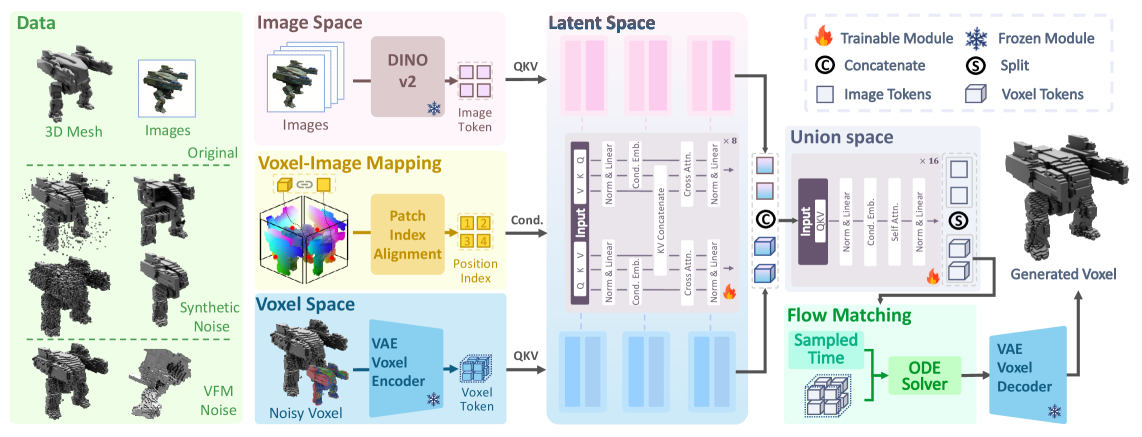
技术框架:VIAFormer的整体架构包含以下几个主要模块:1) 图像索引 (Image Index):为2D图像tokens提供显式的3D空间基础,建立图像特征与体素空间位置的对应关系。2) 校正流目标 (Correctional Flow Objective):学习从初始噪声体素到精细化体素的直接映射,指导网络学习体素修复的轨迹。3) 混合流Transformer (Hybrid Stream Transformer):融合图像和体素特征,实现鲁棒的跨模态信息交互。整个流程首先利用图像索引将图像特征与体素空间对齐,然后通过混合流Transformer进行特征融合,最后利用校正流目标优化体素形状。
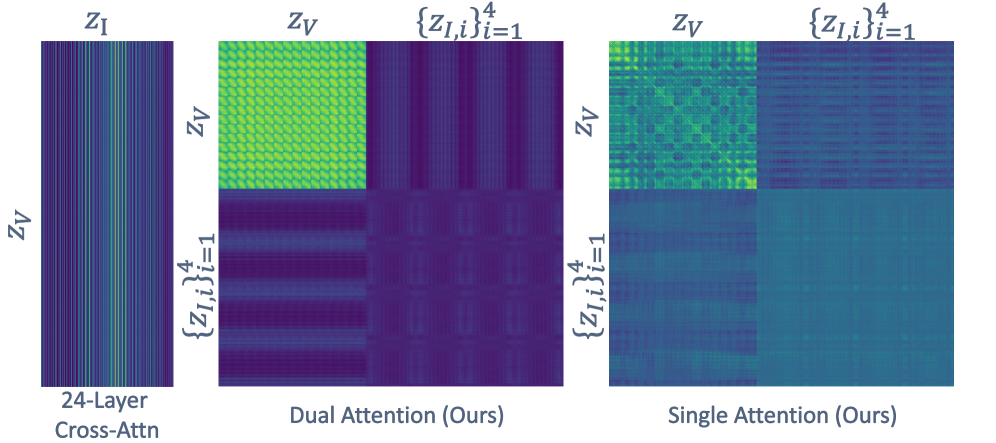
关键创新:VIAFormer的关键创新在于其图像索引模块和校正流目标。图像索引模块通过显式地建立图像tokens与3D空间位置的对应关系,克服了传统方法中图像特征与体素空间对齐困难的问题。校正流目标则通过学习直接的体素精细化轨迹,避免了中间步骤的误差累积,提高了修复的精度。
关键设计:图像索引模块的具体实现方式未知,可能涉及到坐标编码或注意力机制等技术。校正流目标的具体损失函数形式未知,但其目的是引导网络学习从噪声体素到精细化体素的映射。混合流Transformer的具体结构未知,但其关键在于如何有效地融合图像和体素特征。
🖼️ 关键图片

📊 实验亮点
VIAFormer在合成数据和真实数据上均取得了显著的性能提升,建立了新的技术水平。具体性能数据未知,但论文强调其在校正由强大的视觉基础模型获得的体素形状上的严重合成损坏和真实伪影方面表现出色。VIAFormer为真实世界3D创建管道提供了一个实用且可靠的桥梁。
🎯 应用场景
VIAFormer可应用于3D内容创建、自动驾驶、机器人导航等领域。在3D内容创建中,可以利用多视角图像重建出高质量的3D模型。在自动驾驶和机器人导航中,可以利用多传感器数据(如相机和激光雷达)重建出准确的环境地图,提高感知能力和决策能力。该研究为基于体素的方法在大模型、大数据时代的应用奠定了基础。
📄 摘要(原文)
We propose VIAFormer, a Voxel-Image Alignment Transformer model designed for Multi-view Conditioned Voxel Refinement--the task of repairing incomplete noisy voxels using calibrated multi-view images as guidance. Its effectiveness stems from a synergistic design: an Image Index that provides explicit 3D spatial grounding for 2D image tokens, a Correctional Flow objective that learns a direct voxel-refinement trajectory, and a Hybrid Stream Transformer that enables robust cross-modal fusion. Experiments show that VIAFormer establishes a new state of the art in correcting both severe synthetic corruptions and realistic artifacts on the voxel shape obtained from powerful Vision Foundation Models. Beyond benchmarking, we demonstrate VIAFormer as a practical and reliable bridge in real-world 3D creation pipelines, paving the way for voxel-based methods to thrive in large-model, big-data wave.