Face-Voice Association with Inductive Bias for Maximum Class Separation
作者: Marta Moscati, Oleksandr Kats, Mubashir Noman, Muhammad Zaigham Zaheer, Yufang Hou, Markus Schedl, Shah Nawaz
分类: cs.CV
发布日期: 2026-01-20
备注: Accepted at ICASSP 2026
💡 一句话要点
提出基于归纳偏置的最大类间分离人脸-语音关联方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人脸-语音关联 多模态学习 归纳偏置 最大类间分离 深度学习
📋 核心要点
- 现有的人脸-语音关联方法主要依赖损失函数来区分不同人的嵌入表示,缺乏明确的类间分离约束。
- 该论文提出将最大类间分离作为归纳偏置,直接增强人脸和语音嵌入表示的判别能力,从而提高关联性能。
- 实验结果表明,该方法在人脸-语音关联任务上达到了SOTA性能,并且与类间正交性损失结合使用效果更佳。
📝 摘要(中文)
人脸-语音关联是多模态学习中广泛研究的问题,其目标是学习人脸和语音的嵌入表示,使得同一人的嵌入表示彼此接近,而不同人的嵌入表示彼此分离。先前的工作主要通过损失函数来实现这一点。最近分类领域的进展表明,通过施加最大类间分离作为归纳偏置,可以增强嵌入表示的判别能力。然而,该技术尚未应用于人脸-语音关联领域。本文旨在填补这一空白,提出了一种人脸-语音关联方法,该方法将不同说话者的多模态表示之间的最大类间分离作为归纳偏置。通过定量实验,我们证明了该方法的有效性,表明其在两种人脸-语音关联任务的表述中均达到了SOTA性能。此外,我们进行了消融研究,表明当与类间正交性损失相结合时,施加归纳偏置最为有效。据我们所知,这项工作首次应用并证明了最大类间分离作为多模态学习中归纳偏置的有效性,从而为建立一种新的范式铺平了道路。
🔬 方法详解
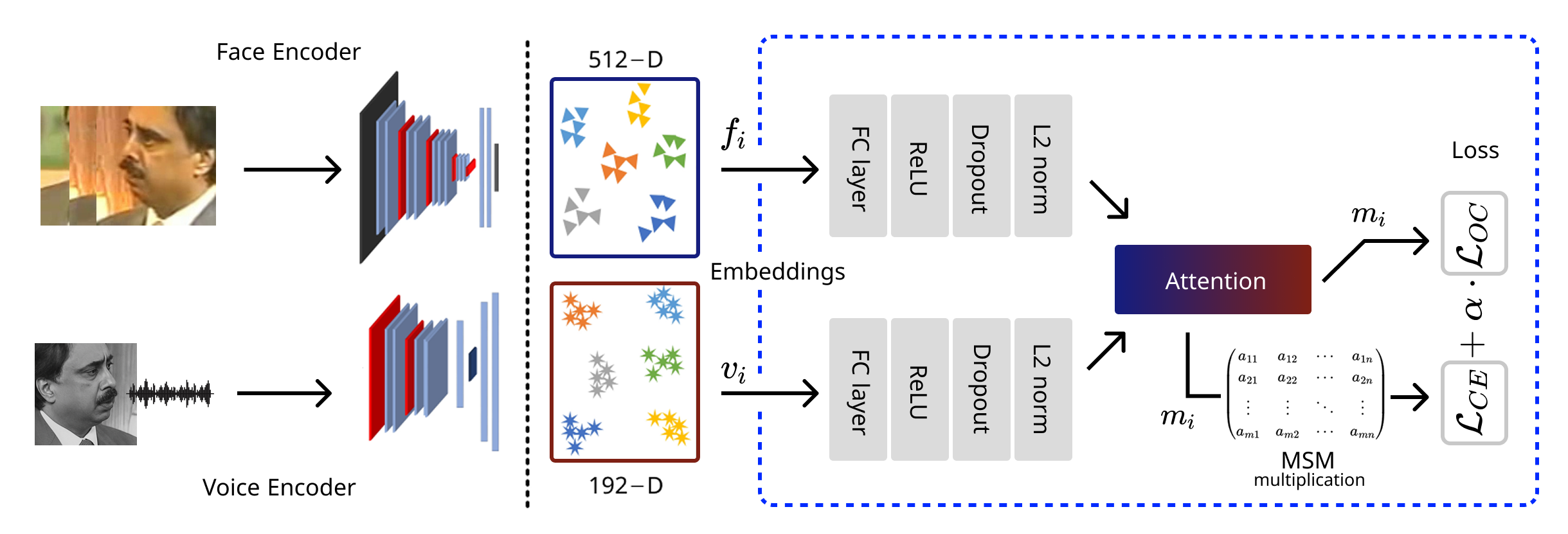
问题定义:论文旨在解决人脸-语音关联问题,即学习人脸和语音的联合嵌入空间,使得同一人的不同模态特征在该空间中距离更近,而不同人的特征距离更远。现有方法主要依赖于设计合适的损失函数来拉近同一个人不同模态的特征,并推远不同人的特征,但缺乏对类间分离的显式约束,可能导致嵌入空间拥挤,判别能力不足。
核心思路:论文的核心思路是将最大类间分离作为一种归纳偏置引入到人脸-语音关联的学习过程中。通过显式地最大化不同类别(不同人)的嵌入表示之间的距离,从而增强嵌入空间的判别能力,使得模型更容易区分不同的人。这种方法可以看作是对传统损失函数的一种补充,通过引入先验知识来指导模型的学习。
技术框架:整体框架包括人脸编码器、语音编码器以及一个用于施加最大类间分离归纳偏置的模块。首先,人脸和语音分别通过各自的编码器提取特征。然后,将提取的特征输入到最大类间分离模块中,该模块的目标是最大化不同类别特征之间的距离。最后,结合传统的损失函数(例如对比损失或三元组损失)来优化整个模型。
关键创新:该论文的关键创新在于首次将最大类间分离作为一种归纳偏置引入到多模态学习领域,特别是人脸-语音关联任务中。与传统方法相比,该方法不再仅仅依赖于损失函数来学习嵌入表示,而是通过引入先验知识来指导模型的学习,从而增强了嵌入空间的判别能力。
关键设计:在最大类间分离模块中,论文可能采用了诸如中心损失(Center Loss)或SphereFace等技术,这些技术旨在缩小类内距离,同时增大类间距离。此外,论文还可能探索了不同的损失函数组合方式,例如将最大类间分离损失与对比损失或三元组损失相结合,以达到更好的效果。具体的网络结构和参数设置需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
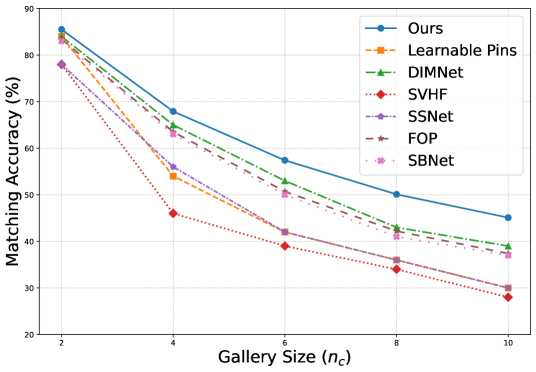
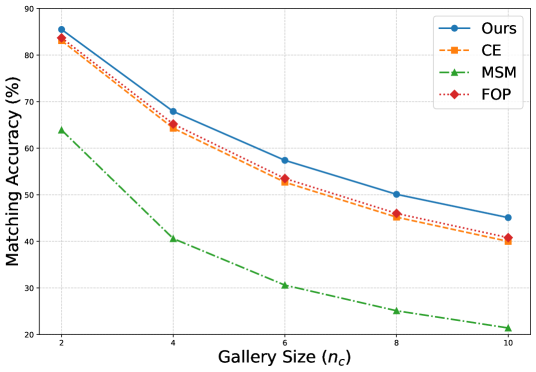
该方法在两种人脸-语音关联任务上取得了SOTA性能,证明了最大类间分离作为归纳偏置的有效性。消融实验表明,将最大类间分离与类间正交性损失相结合可以进一步提升性能。这些结果表明,引入先验知识可以有效地指导多模态学习,并提高模型的泛化能力。
🎯 应用场景
该研究成果可应用于视频会议、智能安防、人机交互等领域。例如,在视频会议中,可以利用人脸和语音信息来识别发言人;在智能安防中,可以结合人脸和语音特征进行身份验证;在人机交互中,可以根据用户的面部表情和语音语调来理解用户的情绪和意图。该研究为多模态身份识别和情感分析等任务提供了新的思路。
📄 摘要(原文)
Face-voice association is widely studied in multimodal learning and is approached representing faces and voices with embeddings that are close for a same person and well separated from those of others. Previous work achieved this with loss functions. Recent advancements in classification have shown that the discriminative ability of embeddings can be strengthened by imposing maximum class separation as inductive bias. This technique has never been used in the domain of face-voice association, and this work aims at filling this gap. More specifically, we develop a method for face-voice association that imposes maximum class separation among multimodal representations of different speakers as an inductive bias. Through quantitative experiments we demonstrate the effectiveness of our approach, showing that it achieves SOTA performance on two task formulation of face-voice association. Furthermore, we carry out an ablation study to show that imposing inductive bias is most effective when combined with losses for inter-class orthogonality. To the best of our knowledge, this work is the first that applies and demonstrates the effectiveness of maximum class separation as an inductive bias in multimodal learning; it hence paves the way to establish a new paradigm.