Scaling Test-time Inference for Visual Grounding
作者: Guanqi Zhan, Changye Li, Zhijian Liu, Yao Lu, Yi Wu, Song Han, Ligeng Zhu
分类: cs.CV
发布日期: 2026-01-20
💡 一句话要点
提出EGM:通过扩展测试时计算量提升视觉定位小模型的性能与效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 视觉语言模型 测试时计算扩展 模型效率 非模态定位
📋 核心要点
- 现有视觉定位模型体积庞大,推理速度慢,难以部署,小型模型在语言理解能力上存在不足。
- EGM通过扩展小型模型在测试时的计算量(token生成),弥补了其在语言理解方面的差距。
- 实验表明,EGM能显著提升小型模型在视觉定位和非模态定位上的性能,并降低推理延迟。
📝 摘要(中文)
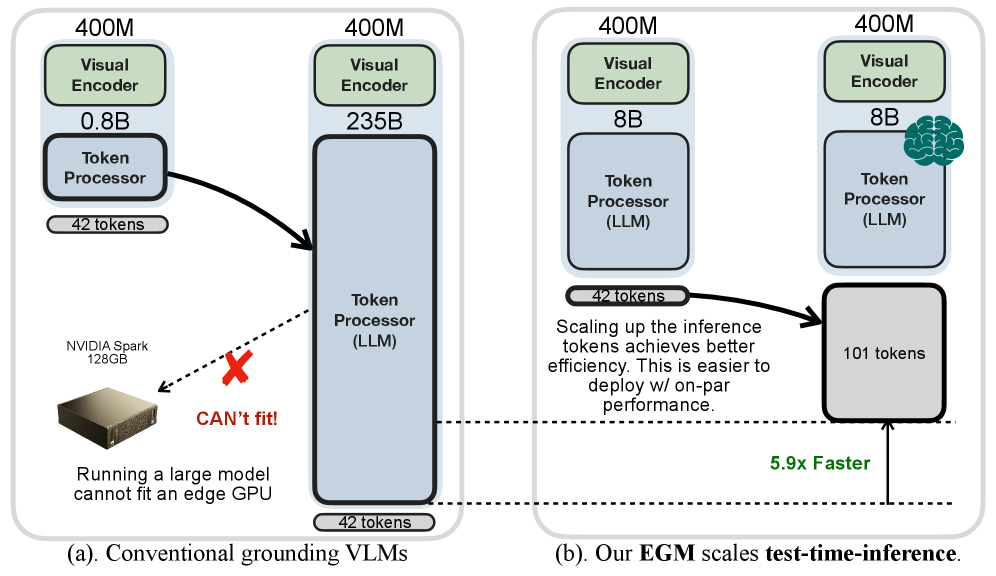
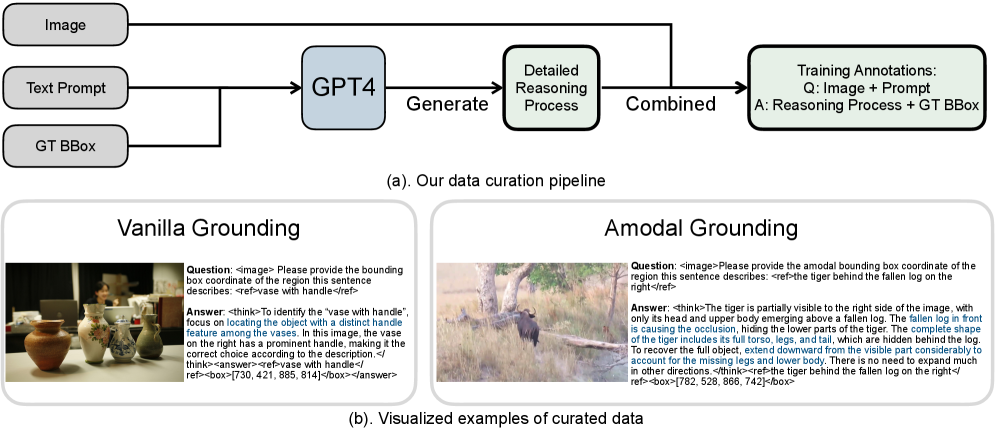
视觉定位是视觉语言模型(VLM)理解真实物理世界的一项关键能力。目前最先进的视觉语言模型通常模型规模庞大,导致部署困难且推理速度慢。然而,我们注意到,对于小型和大型VLM,视觉编码器的大小几乎相同,主要区别在于语言模型的大小。小型VLM在定位方面落后于大型VLM,是因为语言理解能力的差异,而不是视觉信息处理能力。为了弥合这一差距,我们引入了“高效视觉定位语言模型”(EGM):一种扩展测试时计算量(#生成的token)的方法。扩展小型模型的测试时计算量对部署友好,并且由于每个token的成本远低于直接运行大型模型,因此可以产生更好的端到端延迟。在RefCOCO基准测试中,我们的EGM-Qwen3-VL-8B展示了91.4的IoU,平均延迟为737ms(快5.9倍),而Qwen3-VL-235B需要4,320ms才能达到90.5的IoU。为了验证我们方法的通用性,我们进一步建立了一个新的非模态定位设置,要求模型预测物体的可见和遮挡部分。实验表明,我们的方法可以持续且显著地提高小型模型的原始定位和非模态定位能力,使其与大型模型相媲美甚至超越大型模型,从而提高视觉定位的效率。
🔬 方法详解
问题定义:论文旨在解决视觉定位任务中,大型视觉语言模型推理速度慢、部署成本高的问题,以及小型视觉语言模型由于语言理解能力不足导致定位精度低的问题。现有方法要么依赖于庞大的模型,要么牺牲精度以换取效率。
核心思路:论文的核心思路是,通过在测试时增加小型视觉语言模型的计算量(即生成更多的token),来提升其语言理解能力,从而提高定位精度。这种方法的优势在于,它避免了训练大型模型,并且由于小型模型生成token的成本较低,因此可以实现更好的端到端延迟。
技术框架:EGM方法的核心在于扩展测试时的计算量。具体流程是,给定输入图像和文本描述,小型视觉语言模型生成多个token,这些token被用于指导视觉定位。通过增加生成的token数量,模型可以更全面地理解文本描述,并更准确地定位图像中的目标对象。
关键创新:EGM的关键创新在于,它将计算量扩展放在测试时,而不是训练时。这使得小型模型能够在部署时根据需要动态地调整计算量,从而在精度和效率之间取得平衡。此外,EGM还适用于非模态定位任务,这表明其具有较强的通用性。
关键设计:EGM的具体实现细节取决于所使用的视觉语言模型。一般来说,可以通过调整模型生成token的数量来实现计算量扩展。此外,还可以使用一些技巧来提高生成token的质量,例如使用beam search或sampling等方法。论文中使用了Qwen3-VL系列模型,并针对该模型进行了实验。
🖼️ 关键图片

📊 实验亮点
EGM-Qwen3-VL-8B在RefCOCO基准测试中取得了91.4的IoU,同时将推理延迟降低到737ms,比Qwen3-VL-235B快5.9倍(后者IoU为90.5,延迟为4,320ms)。此外,EGM在非模态定位任务中也取得了显著的性能提升,证明了其通用性。
🎯 应用场景
EGM方法可应用于各种需要视觉定位的场景,例如机器人导航、智能监控、图像搜索等。该方法可以提高这些应用在资源受限设备上的性能,并降低部署成本。此外,EGM在非模态定位上的应用,也为解决遮挡场景下的视觉定位问题提供了新的思路。
📄 摘要(原文)
Visual grounding is an essential capability of Visual Language Models (VLMs) to understand the real physical world. Previous state-of-the-art grounding visual language models usually have large model sizes, making them heavy for deployment and slow for inference. However, we notice that the sizes of visual encoders are nearly the same for small and large VLMs and the major difference is the sizes of the language models. Small VLMs fall behind larger VLMs in grounding because of the difference in language understanding capability rather than visual information handling. To mitigate the gap, we introduce 'Efficient visual Grounding language Models' (EGM): a method to scale the test-time computation (#generated tokens). Scaling the test-time computation of a small model is deployment-friendly, and yields better end-to-end latency as the cost of each token is much cheaper compared to directly running a large model. On the RefCOCO benchmark, our EGM-Qwen3-VL-8B demonstrates 91.4 IoU with an average of 737ms (5.9x faster) latency while Qwen3-VL-235B demands 4,320ms to achieve 90.5 IoU. To validate our approach's generality, we further set up a new amodal grounding setting that requires the model to predict both the visible and occluded parts of the objects. Experiments show our method can consistently and significantly improve the vanilla grounding and amodal grounding capabilities of small models to be on par with or outperform the larger models, thereby improving the efficiency for visual grounding.