CausalSpatial: A Benchmark for Object-Centric Causal Spatial Reasoning
作者: Wenxin Ma, Chenlong Wang, Ruisheng Yuan, Hao Chen, Nanru Dai, S. Kevin Zhou, Yijun Yang, Alan Yuille, Jieneng Chen
分类: cs.CV
发布日期: 2026-01-19
备注: Code is available: https://github.com/CausalSpatial/CausalSpatial
🔗 代码/项目: GITHUB
💡 一句话要点
提出CausalSpatial基准测试,评估多模态大语言模型在因果空间推理中的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果空间推理 多模态大语言模型 基准测试 动态模拟 视觉推理
📋 核心要点
- 现有的多模态大语言模型在3D场景中进行因果空间推理时,无法有效利用视觉信息,过度依赖文本推理,导致空间理解不足。
- 论文提出因果对象世界模型(COW),通过生成模拟视频来提供显式的因果视觉线索,从而帮助模型更好地进行空间推理。
- CausalSpatial基准测试表明,人类在此任务上表现远超现有模型,COW模型通过引入视觉信息,显著提升了模型性能。
📝 摘要(中文)
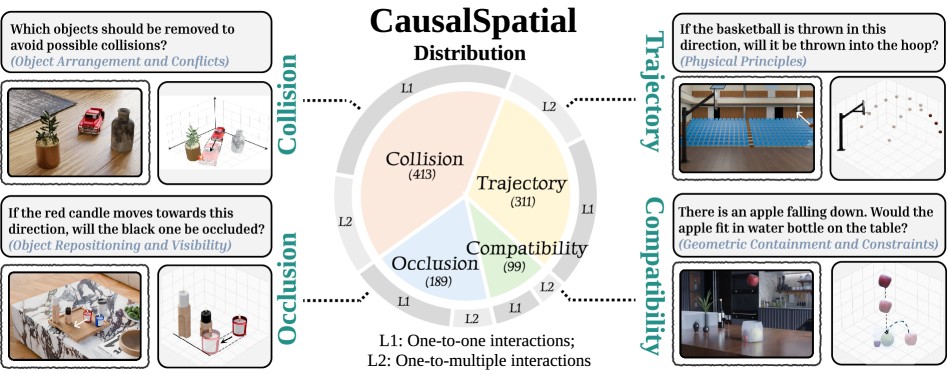
人类可以通过观察静态场景立即预测接下来会发生什么,例如移动一个物体是否会导致碰撞,这种能力被称为因果空间推理。然而,目前的多模态大语言模型(MLLMs)无法做到这一点,因为它们主要局限于静态空间感知,难以回答3D场景中的“假设”问题。本文提出了CausalSpatial,一个诊断基准,用于评估模型预测物体运动结果的能力,包含碰撞、兼容性、遮挡和轨迹四个任务。结果表明存在严重差距:人类得分84%,而GPT-5仅为54%。分析揭示了一个根本缺陷:模型过度依赖于文本的思维链推理,偏离了视觉证据,产生流畅但空间上无根据的幻觉。为了解决这个问题,本文提出了因果对象世界模型(COW),通过生成假设动态的视频来外部化模拟过程。通过显式的因果视觉线索,COW使模型能够将其推理建立在物理现实而非语言先验之上。数据集和代码已公开。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在因果空间推理方面的不足。现有MLLMs在处理涉及物理动态的“假设”问题时,过度依赖文本推理,而忽略了视觉信息,导致空间理解能力较差,无法准确预测物体运动的后果。
核心思路:论文的核心思路是外部化模拟过程,通过生成假设动态的视频来提供显式的因果视觉线索。这样可以使模型能够将其推理建立在物理现实而非语言先验之上,从而提高因果空间推理的准确性。
技术框架:论文提出了因果对象世界模型(COW),该框架包含以下主要模块:1) 场景理解模块:用于理解输入场景的几何和语义信息。2) 动态模拟模块:根据场景信息和给定的动作,生成模拟视频,展示物体运动的可能结果。3) 推理模块:利用生成的视频和原始场景信息,进行因果空间推理,预测物体运动的后果。
关键创新:论文的关键创新在于将动态模拟过程显式地引入到MLLM的推理过程中。通过生成模拟视频,COW模型能够提供更丰富的视觉信息,从而帮助模型更好地理解场景中的物理关系和因果关系。这与现有方法过度依赖文本推理形成了鲜明对比。
关键设计:COW模型的动态模拟模块可以使用各种物理引擎或基于学习的动态预测模型来实现。推理模块可以使用现有的MLLM架构,但需要针对视频输入进行调整。论文中可能使用了特定的损失函数来训练动态模拟模块,以确保生成的视频能够准确反映物体运动的物理规律。(具体细节未知)
🖼️ 关键图片

📊 实验亮点
CausalSpatial基准测试表明,人类在因果空间推理任务上的表现远超现有MLLMs,GPT-5的得分仅为54%,而人类为84%。COW模型通过引入显式的视觉线索,显著提升了模型在CausalSpatial基准测试上的性能,表明了视觉信息在因果空间推理中的重要性。(具体提升幅度未知)
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。例如,机器人可以利用因果空间推理能力预测自身动作对环境的影响,从而规划更安全、更有效的路径。自动驾驶系统可以预测其他车辆或行人的运动轨迹,从而避免交通事故。游戏AI可以模拟更逼真的物理交互,提升游戏体验。
📄 摘要(原文)
Humans can look at a static scene and instantly predict what happens next -- will moving this object cause a collision? We call this ability Causal Spatial Reasoning. However, current multimodal large language models (MLLMs) cannot do this, as they remain largely restricted to static spatial perception, struggling to answer "what-if" questions in a 3D scene. We introduce CausalSpatial, a diagnostic benchmark evaluating whether models can anticipate consequences of object motions across four tasks: Collision, Compatibility, Occlusion, and Trajectory. Results expose a severe gap: humans score 84% while GPT-5 achieves only 54%. Why do MLLMs fail? Our analysis uncovers a fundamental deficiency: models over-rely on textual chain-of-thought reasoning that drifts from visual evidence, producing fluent but spatially ungrounded hallucinations. To address this, we propose the Causal Object World model (COW), a framework that externalizes the simulation process by generating videos of hypothetical dynamics. With explicit visual cues of causality, COW enables models to ground their reasoning in physical reality rather than linguistic priors. We make the dataset and code publicly available here: https://github.com/CausalSpatial/CausalSpatial