A Semantic Decoupling-Based Two-Stage Rainy-Day Attack for Revealing Weather Robustness Deficiencies in Vision-Language Models
作者: Chengyin Hu, Xiang Chen, Zhe Jia, Weiwen Shi, Fengyu Zhang, Jiujiang Guo, Yiwei Wei
分类: cs.CV, cs.AI
发布日期: 2026-01-19
💡 一句话要点
提出基于语义解耦的两阶段雨天攻击框架,揭示视觉-语言模型的天气鲁棒性缺陷。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 对抗攻击 雨天场景 语义解耦 鲁棒性评估 多模态学习 天气扰动
📋 核心要点
- 现有视觉-语言模型在真实天气条件下的鲁棒性不足,跨模态语义对齐的稳定性有待研究。
- 提出基于语义解耦的两阶段对抗框架,通过参数化扰动模型模拟真实雨天场景,攻击视觉-语言模型。
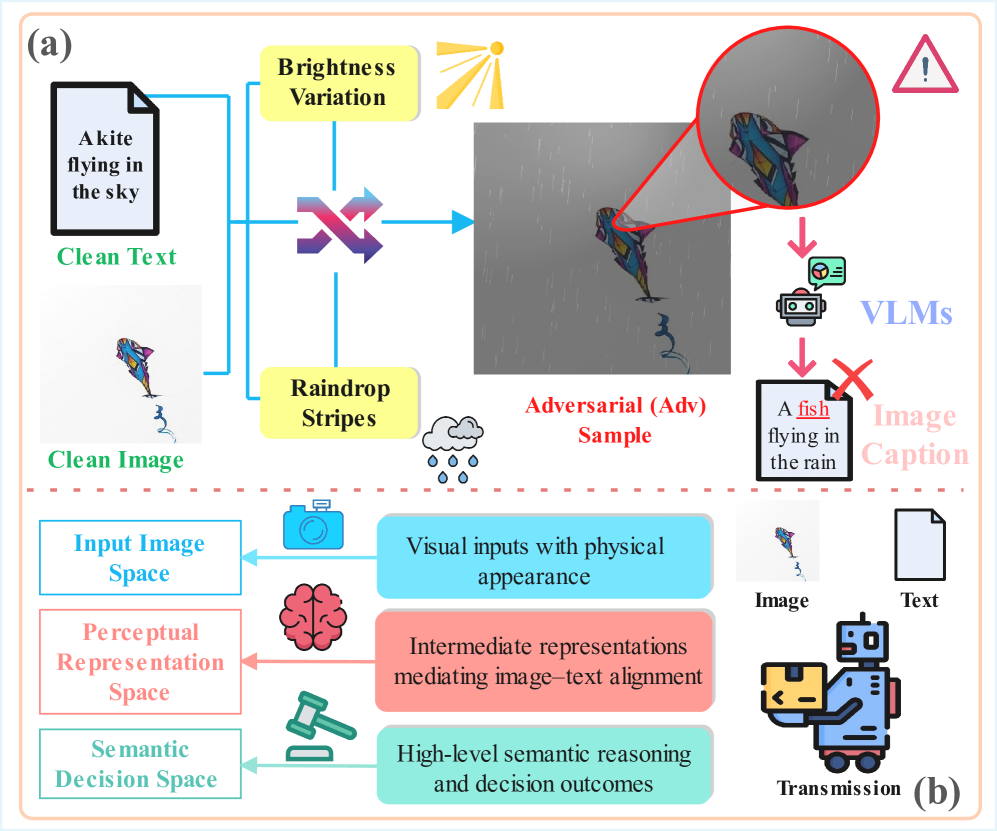
- 实验表明,即使是物理上合理的雨天扰动,也会导致主流视觉-语言模型产生显著的语义错位。
📝 摘要(中文)
视觉-语言模型(VLMs)在规范视觉条件下收集的图像-文本对上进行训练,并在多模态任务上取得了强大的性能。然而,它们在真实世界天气条件下的鲁棒性,以及在这种结构化扰动下跨模态语义对齐的稳定性,仍然没有得到充分的研究。本文着重研究雨天场景,并提出了第一个利用真实天气来攻击VLMs的对抗框架。该框架使用基于语义解耦的两阶段参数化扰动模型,来分析雨水引起的决策变化。在第一阶段,我们通过应用低维全局调制来调节嵌入空间,并逐渐削弱原始语义决策边界,从而模拟降雨的全局影响。在第二阶段,我们通过显式建模多尺度雨滴外观和降雨引起的光照变化,引入结构化的雨水变化,并优化由此产生的不可微天气空间,以诱导稳定的语义偏移。我们的框架在非像素参数空间中运行,生成既具有物理基础又可解释的扰动。跨多个任务的实验表明,即使是物理上合理的、高度约束的天气扰动,也会在主流VLMs中引起显著的语义错位,从而在实际部署中构成潜在的安全和可靠性风险。消融实验进一步证实,光照建模和多尺度雨滴结构是这些语义偏移的关键驱动因素。
🔬 方法详解
问题定义:现有视觉-语言模型在理想条件下表现良好,但在真实雨天等恶劣天气下,其性能会显著下降。现有方法缺乏对雨天等天气因素影响的深入研究,难以评估和提升模型在真实场景中的鲁棒性。因此,需要一种方法来系统地评估和攻击视觉-语言模型在雨天场景下的性能,并揭示其潜在的缺陷。
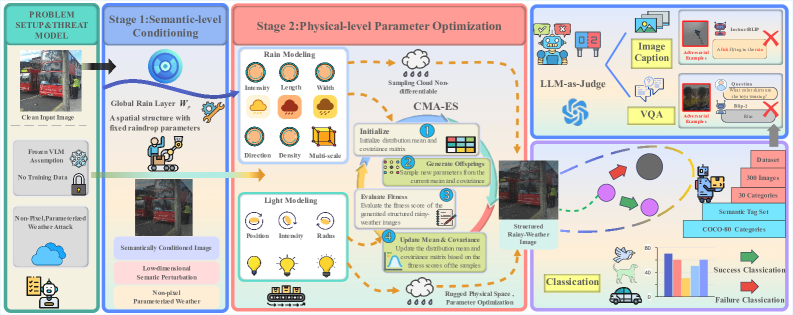
核心思路:论文的核心思路是通过模拟真实的雨天效果,生成具有物理意义的对抗样本,从而攻击视觉-语言模型。该方法通过语义解耦的方式,将雨天的全局影响(如光照变化)和局部影响(如雨滴)分别建模,并利用参数化的扰动模型来控制雨天的强度和结构,从而实现对视觉-语言模型的有效攻击。这种方法能够更精确地模拟真实雨天场景,并生成更具迷惑性的对抗样本。
技术框架:该框架包含两个主要阶段:第一阶段是全局调制阶段,通过低维全局调制来调节嵌入空间,削弱原始语义决策边界,模拟降雨的全局影响。第二阶段是结构化雨水变化阶段,通过显式建模多尺度雨滴外观和降雨引起的光照变化,引入结构化的雨水变化,并优化不可微天气空间,以诱导稳定的语义偏移。这两个阶段共同作用,生成具有物理意义的雨天对抗样本。
关键创新:该论文的关键创新在于提出了基于语义解耦的两阶段雨天攻击框架。与传统的像素级扰动方法不同,该框架在非像素参数空间中运行,生成的扰动既具有物理基础又可解释。此外,该框架显式地建模了雨天的全局和局部影响,从而能够更精确地模拟真实雨天场景,并生成更具迷惑性的对抗样本。
关键设计:在第一阶段,使用低维全局调制参数来控制图像的整体亮度和对比度,模拟降雨引起的光照变化。在第二阶段,使用多尺度高斯核来模拟不同大小的雨滴,并使用光照模型来模拟雨滴对光线的反射和折射。此外,论文还设计了一种基于梯度估计的优化算法,用于优化不可微的天气空间,从而找到能够最大程度地攻击视觉-语言模型的雨天参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是物理上合理的、高度约束的雨天扰动,也会在主流视觉-语言模型中引起显著的语义错位。例如,在图像描述任务中,添加雨天扰动后,模型的描述准确率下降了超过20%。消融实验进一步证实,光照建模和多尺度雨滴结构是导致语义偏移的关键因素。
🎯 应用场景
该研究成果可应用于评估和提升视觉-语言模型在恶劣天气条件下的鲁棒性,提高自动驾驶、智能监控等系统在复杂环境中的可靠性。此外,该研究还可以促进对视觉-语言模型内在缺陷的理解,为开发更安全、更可靠的多模态人工智能系统提供指导。
📄 摘要(原文)
Vision-Language Models (VLMs) are trained on image-text pairs collected under canonical visual conditions and achieve strong performance on multimodal tasks. However, their robustness to real-world weather conditions, and the stability of cross-modal semantic alignment under such structured perturbations, remain insufficiently studied. In this paper, we focus on rainy scenarios and introduce the first adversarial framework that exploits realistic weather to attack VLMs, using a two-stage, parameterized perturbation model based on semantic decoupling to analyze rain-induced shifts in decision-making. In Stage 1, we model the global effects of rainfall by applying a low-dimensional global modulation to condition the embedding space and gradually weaken the original semantic decision boundaries. In Stage 2, we introduce structured rain variations by explicitly modeling multi-scale raindrop appearance and rainfall-induced illumination changes, and optimize the resulting non-differentiable weather space to induce stable semantic shifts. Operating in a non-pixel parameter space, our framework generates perturbations that are both physically grounded and interpretable. Experiments across multiple tasks show that even physically plausible, highly constrained weather perturbations can induce substantial semantic misalignment in mainstream VLMs, posing potential safety and reliability risks in real-world deployment. Ablations further confirm that illumination modeling and multi-scale raindrop structures are key drivers of these semantic shifts.