ICo3D: An Interactive Conversational 3D Virtual Human
作者: Richard Shaw, Youngkyoon Jang, Athanasios Papaioannou, Arthur Moreau, Helisa Dhamo, Zhensong Zhang, Eduardo Pérez-Pellitero
分类: cs.CV, cs.HC
发布日期: 2026-01-19
备注: Accepted by International Journal on Computer Vision (IJCV). Project page: https://ico3d.github.io/. This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this article is published in International Journal of Computer Vision and is available online at https://doi.org/10.1007/s11263-025-02725-8
DOI: 10.1007/s11263-025-02725-8
💡 一句话要点
ICo3D:提出交互式对话3D虚拟人生成方法,实现逼真实时互动
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D虚拟人 实时交互 对话系统 高斯splatting 多视角重建
📋 核心要点
- 现有虚拟人生成方法在实时交互性、逼真度和对话能力上存在挑战,难以提供沉浸式体验。
- ICo3D通过多视角捕捉构建可动画的3D面部和身体模型,并结合LLM实现自然对话和语音驱动的面部动画。
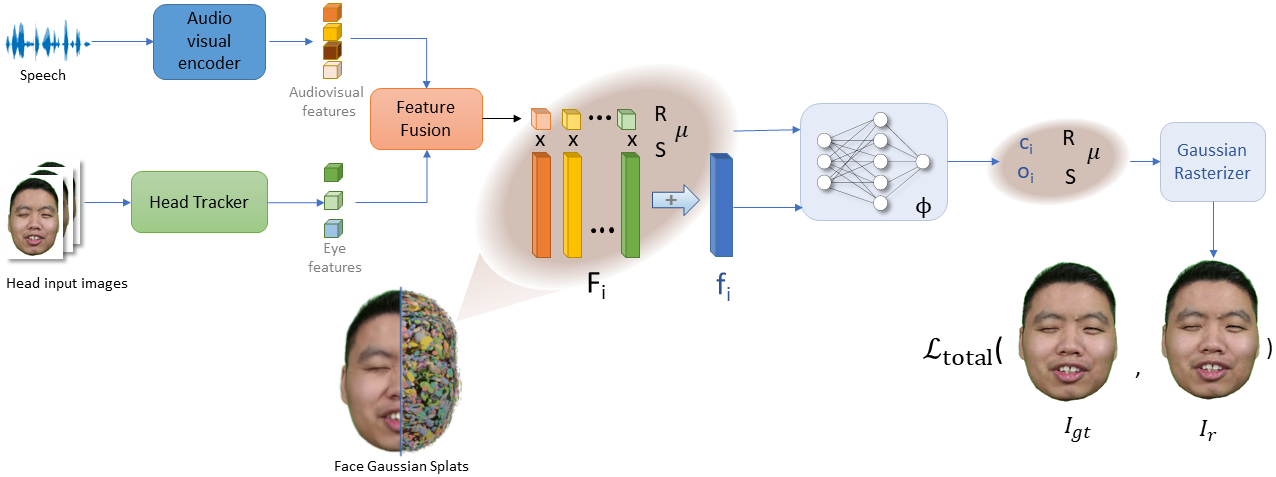
- 通过SWinGS++和HeadGaS++改进动态高斯模型,提升了身体和面部重建的逼真度,并解决了模型融合问题。
📝 摘要(中文)
本文提出了一种交互式对话3D虚拟人(ICo3D)生成方法,该方法能够生成交互式、对话式和照片级真实的3D人体化身。基于主体的多视角捕捉,我们创建了一个可动画的3D面部模型和一个动态3D身体模型,两者都通过高斯基元的splatting进行渲染。将它们合并后,便构成了一个栩栩如生的虚拟人体化身,适用于实时用户交互。我们为化身配备了一个LLM,以实现对话能力。在对话过程中,化身的声音语音被用作驱动信号来动画面部模型,从而实现精确的同步。我们描述了对动态高斯模型的改进,以增强照片真实感:用于身体重建的SWinGS++和用于面部重建的HeadGaS++,并提供了一种解决方案来合并单独的面部和身体模型,而不会产生伪影。我们还展示了完整系统的演示,展示了与3D化身进行实时对话的几个用例。我们的方法提供了一种完全集成的虚拟化身体验,支持沉浸式环境中口头和书面形式的交互。ICo3D适用于广泛的领域,包括游戏、虚拟助手和个性化教育等。
🔬 方法详解
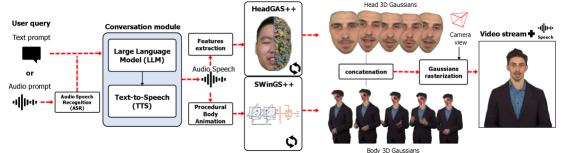
问题定义:现有方法在生成具有逼真外观、自然对话能力和实时交互性的3D虚拟人方面存在挑战。尤其是在面部和身体的无缝融合,以及语音驱动的面部动画的精确同步方面,仍有改进空间。
核心思路:ICo3D的核心思路是利用多视角捕捉数据构建高精度、可动画的3D面部和身体模型,并结合大型语言模型(LLM)实现自然语言对话。通过语音驱动面部动画,增强交互的真实感和沉浸感。
技术框架:ICo3D系统主要包含以下几个模块:1) 多视角数据采集;2) 基于SWinGS++的动态3D身体模型重建;3) 基于HeadGaS++的动态3D面部模型重建;4) 面部和身体模型的无缝融合;5) LLM驱动的对话系统;6) 语音驱动的面部动画。整体流程是从多视角视频中提取3D信息,分别构建面部和身体模型,然后将二者融合,并通过语音和文本与用户进行交互。
关键创新:ICo3D的关键创新在于:1) 提出了SWinGS++和HeadGaS++,改进了动态高斯模型的重建质量,提升了面部和身体的逼真度;2) 解决了面部和身体模型的无缝融合问题,避免了伪影的产生;3) 实现了语音驱动的精确面部动画,增强了对话的真实感。
关键设计:SWinGS++和HeadGaS++的具体技术细节(例如损失函数、网络结构等)在论文中未详细描述,属于未知信息。面部和身体模型的融合方法也未给出具体细节。语音驱动面部动画的具体实现方式(例如,如何将语音信号映射到面部表情参数)也属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文展示了ICo3D系统的demo,证明了其生成具有逼真外观和自然对话能力的3D虚拟人的能力。虽然论文中没有提供具体的性能数据或与其他基线的定量比较,但通过demo展示了SWinGS++和HeadGaS++在提升面部和身体重建质量方面的有效性,以及面部和身体模型融合的无缝性。语音驱动的面部动画也表现出较好的同步性和真实感。
🎯 应用场景
ICo3D技术可广泛应用于游戏、虚拟助手、个性化教育、远程医疗、虚拟会议等领域。它能够提供更具沉浸感和互动性的用户体验,例如,在游戏中创建逼真的NPC角色,在教育领域提供个性化的虚拟导师,或在远程医疗中实现更自然的医患沟通。未来,该技术有望成为元宇宙等沉浸式环境的关键组成部分。
📄 摘要(原文)
This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others. Project page: https://ico3d.github.io/