TVWorld: Foundations for Remote-Control TV Agents
作者: Zhantao Ma, Quanfeng Lu, Shuai Zhong, Dahai Yu, Ping Luo, Michael K. Ng
分类: cs.CV, cs.AI, cs.CL
发布日期: 2026-01-19
💡 一句话要点
提出TVWorld以解决远程控制电视代理的导航问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 远程控制 电视导航 拓扑感知 视觉语言模型 图模型 智能家居 长时间导航
📋 核心要点
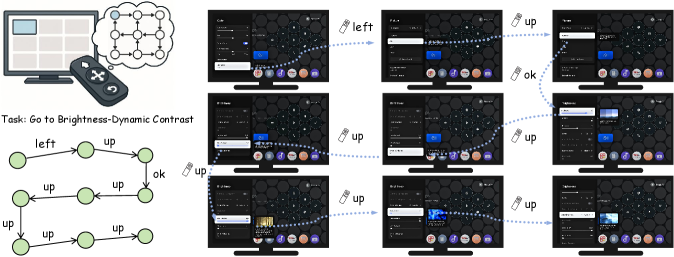
- 现有的设备控制研究主要集中在点选交互,远程控制交互的研究相对较少,导致电视导航能力的不足。
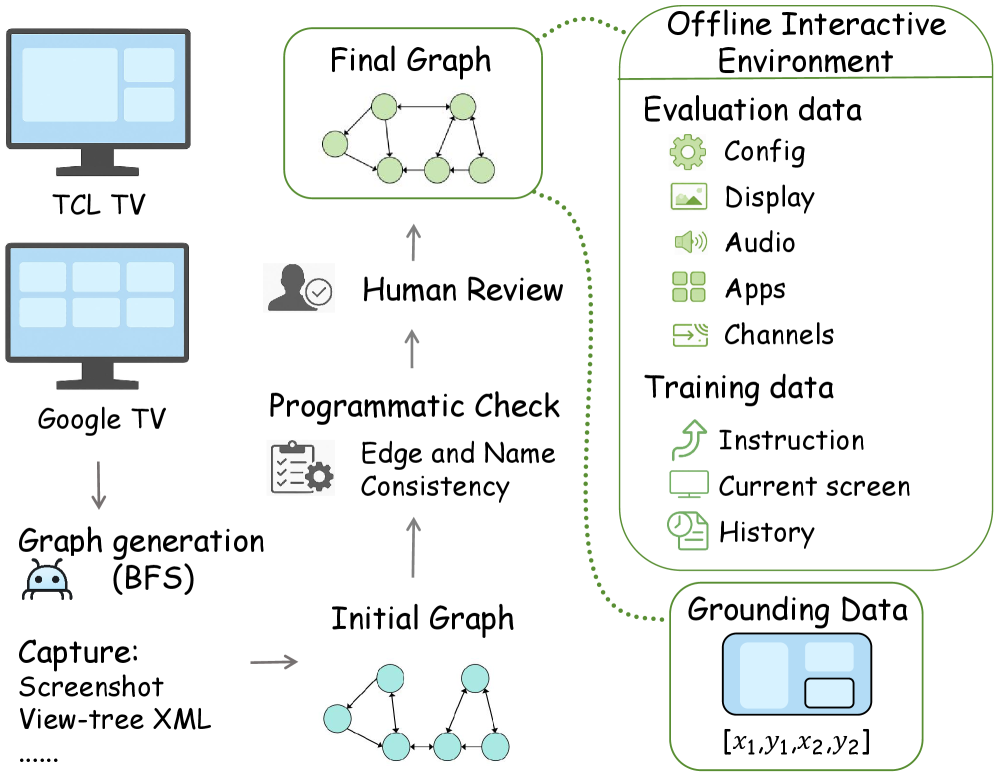
- 论文提出了TVWorld,一个基于图的离线抽象,结合拓扑感知训练框架,提升了电视导航的能力。
- TVTheseus模型在TVWorld-N基准上取得68.3%的成功率,超越了现有的闭源基线,展现出显著的性能提升。
📝 摘要(中文)
近年来,大型视觉语言模型(LVLMs)在设备控制方面展现出强大的潜力。然而,现有研究主要集中在点选交互(PnC),而日常电视使用中常见的远程控制(RC)交互仍然未被充分探索。为填补这一空白,我们引入了TVWorld,这是一个基于图的离线抽象,旨在实现可重复和无部署的评估。在此基础上,我们提出了两个互补的基准,全面评估电视使用能力:TVWorld-N用于拓扑感知导航,TVWorld-G用于聚焦感知定位。这些基准揭示了现有代理的一个关键局限性:在基于聚焦的长时间电视导航中,拓扑感知不足。基于此发现,我们提出了拓扑感知训练框架,将拓扑感知注入LVLMs,并开发了专门用于电视导航的基础模型TVTheseus。TVTheseus在TVWorld-N上取得了68.3%的成功率,超越了强大的闭源基线,确立了最先进的性能。
🔬 方法详解
问题定义:本论文旨在解决现有远程控制电视代理在长时间导航中的拓扑感知不足问题。现有方法主要集中于点选交互,未能有效处理复杂的电视导航场景。
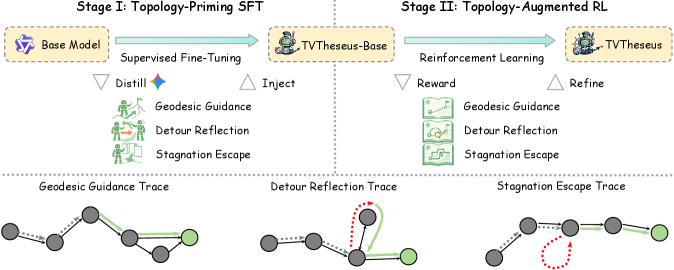
核心思路:论文的核心思路是通过引入拓扑感知训练框架,增强LVLMs在电视导航中的表现,使其能够更好地理解和利用电视界面的结构信息。
技术框架:整体架构包括TVWorld图模型的构建、拓扑感知训练框架的设计,以及TVTheseus模型的开发。主要模块包括图结构表示、导航策略学习和聚焦定位能力的提升。
关键创新:最重要的技术创新点在于提出了拓扑感知训练框架,将拓扑信息有效融入到LVLMs中,从而显著提升了模型在复杂导航任务中的表现。
关键设计:在模型设计中,采用了特定的损失函数来优化拓扑感知能力,并在网络结构中引入了图卷积网络(GCN)以增强对电视界面结构的理解。
🖼️ 关键图片
📊 实验亮点
TVTheseus模型在TVWorld-N基准上取得68.3%的成功率,显著超越了闭源基线如Gemini 3 Flash,确立了当前的最先进性能。这一结果表明,拓扑感知训练框架在提升电视导航能力方面的有效性。
🎯 应用场景
该研究的潜在应用领域包括智能电视、家庭娱乐系统以及任何需要远程控制的设备。通过提升电视导航能力,用户可以获得更流畅的观看体验,未来可能推动智能家居设备的更广泛应用和发展。
📄 摘要(原文)
Recent large vision-language models (LVLMs) have demonstrated strong potential for device control. However, existing research has primarily focused on point-and-click (PnC) interaction, while remote-control (RC) interaction commonly encountered in everyday TV usage remains largely underexplored. To fill this gap, we introduce \textbf{TVWorld}, an offline graph-based abstraction of real-world TV navigation that enables reproducible and deployment-free evaluation. On this basis, we derive two complementary benchmarks that comprehensively assess TV-use capabilities: \textbf{TVWorld-N} for topology-aware navigation and \textbf{TVWorld-G} for focus-aware grounding. These benchmarks expose a key limitation of existing agents: insufficient topology awareness for focus-based, long-horizon TV navigation. Motivated by this finding, we propose a \emph{Topology-Aware Training} framework that injects topology awareness into LVLMs. Using this framework, we develop \textbf{TVTheseus}, a foundation model specialized for TV navigation. TVTheseus achieves a success rate of $68.3\%$ on TVWorld-N, surpassing strong closed-source baselines such as Gemini 3 Flash and establishing state-of-the-art (SOTA) performance. Additional analyses further provide valuable insights into the development of effective TV-use agents.