Think3D: Thinking with Space for Spatial Reasoning
作者: Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, Lijun Wang, Huchuan Lu
分类: cs.CV
发布日期: 2026-01-19
🔗 代码/项目: GITHUB
💡 一句话要点
Think3D:利用空间推理增强视觉大模型在空间理解上的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 空间推理 视觉大模型 3D重建 强化学习 多模态智能 链式思考 机器人导航
📋 核心要点
- 现有视觉大模型(VLMs)在空间理解方面存在不足,本质上是2D感知器,难以进行真正的3D推理。
- Think3D框架利用3D重建模型从图像或视频中恢复点云和相机姿态,使智能体能够主动操纵空间。
- Think3D显著提高了先进模型的空间推理性能,并通过强化学习策略提升了较小模型在空间探索方面的能力。
📝 摘要(中文)
理解和推理物理世界需要空间智能,即解释几何、透视和超出2D感知的空间关系的能力。虽然最近的视觉大模型(VLMs)在视觉理解方面表现出色,但它们本质上仍然是2D感知器,难以进行真正的3D推理。我们提出了Think3D,一个使VLM智能体能够利用3D空间进行思考的框架。通过利用从图像或视频中恢复点云和相机姿态的3D重建模型,Think3D允许智能体通过基于相机的操作和自我/全局视图切换来主动操纵空间,从而将空间推理转换为交互式的3D链式思考过程。无需额外训练,Think3D显著提高了GPT-4.1和Gemini 2.5 Pro等先进模型的空间推理性能,在BLINK Multi-view和MindCube上平均提升+7.8%,在VSI-Bench上提升+4.7%。我们进一步表明,在空间探索方面存在困难的较小模型,可以从强化学习策略中受益,该策略使模型能够选择信息丰富的视点和操作。通过强化学习,工具使用的好处从+0.7%增加到+6.8%。我们的研究结果表明,免训练、工具增强的空间探索是多模态智能体中更灵活和类人3D推理的可行途径,从而建立了多模态智能的新维度。代码和权重已在https://github.com/zhangzaibin/spagent上发布。
🔬 方法详解
问题定义:论文旨在解决视觉大模型(VLMs)在空间推理方面的不足。现有VLMs主要基于2D图像进行推理,缺乏对3D空间几何、透视和空间关系的理解,导致在需要空间智能的任务中表现不佳。
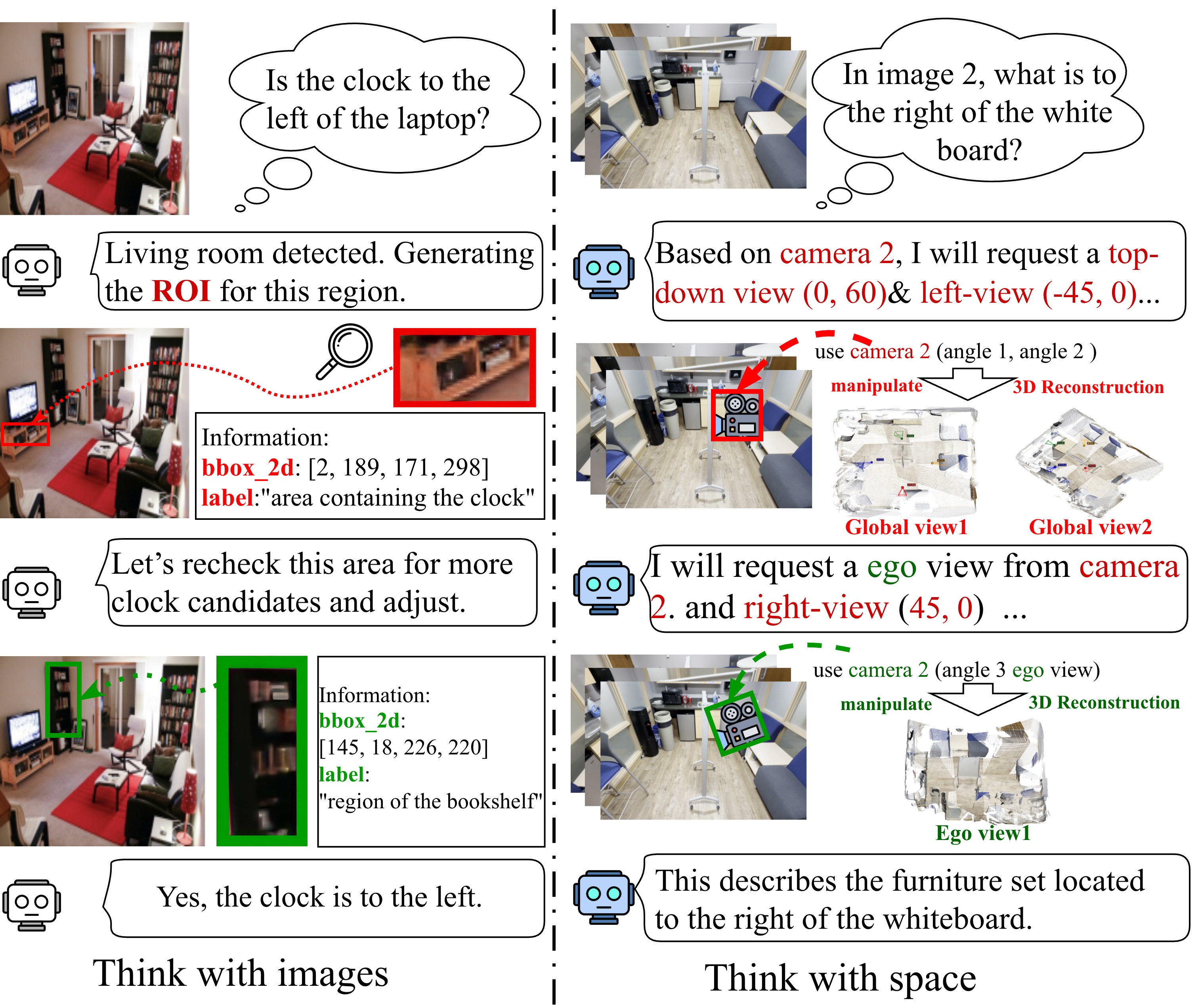
核心思路:论文的核心思路是赋予VLM智能体利用3D空间进行思考的能力。通过引入3D重建模块,将2D图像转换为3D点云和相机姿态信息,使智能体能够像人类一样在3D空间中进行交互和推理。这种方法将空间推理转化为一个交互式的3D链式思考过程。
技术框架:Think3D框架主要包含以下几个模块:1) 3D重建模块:从图像或视频中重建3D点云和相机姿态。2) 空间操作模块:允许智能体通过相机操作(如移动、旋转)和视图切换(自我/全局)来操纵3D空间。3) VLM推理模块:利用VLM(如GPT-4.1、Gemini 2.5 Pro)对3D空间信息进行推理。4) 强化学习模块(可选):用于训练智能体选择信息丰富的视点和操作。整体流程是:输入图像/视频 -> 3D重建 -> 空间操作 -> VLM推理 -> 输出结果。
关键创新:Think3D的关键创新在于它将VLM与3D重建技术相结合,使智能体能够以3D方式思考和推理。与传统的2D图像推理方法相比,Think3D能够更好地理解空间关系和几何信息,从而提高空间推理的准确性和鲁棒性。此外,论文还提出了利用强化学习来优化空间探索策略的方法,进一步提升了智能体的性能。
关键设计:3D重建模块可以使用现有的成熟算法,如COLMAP、Open3D等。空间操作模块的设计需要考虑操作的效率和可控性,例如可以使用预定义的相机移动和旋转角度。强化学习模块可以使用常见的策略梯度算法,如PPO,奖励函数可以根据任务目标进行设计,例如奖励智能体选择能够提高推理准确性的视点。
🖼️ 关键图片
📊 实验亮点
Think3D在多个空间推理基准测试中取得了显著的性能提升。在BLINK Multi-view和MindCube上,Think3D使GPT-4.1和Gemini 2.5 Pro等先进模型的平均性能提升了+7.8%。在VSI-Bench上,性能提升了+4.7%。此外,通过强化学习优化空间探索策略,工具使用的收益从+0.7%提高到+6.8%,表明了该方法在提升空间推理能力方面的有效性。
🎯 应用场景
Think3D具有广泛的应用前景,例如机器人导航、自动驾驶、场景理解、虚拟现实/增强现实等领域。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,Think3D可以提高车辆对复杂交通场景的理解能力,从而提高驾驶安全性。在VR/AR领域,Think3D可以创建更逼真的3D场景,增强用户体验。
📄 摘要(原文)
Understanding and reasoning about the physical world requires spatial intelligence: the ability to interpret geometry, perspective, and spatial relations beyond 2D perception. While recent vision large models (VLMs) excel at visual understanding, they remain fundamentally 2D perceivers and struggle with genuine 3D reasoning. We introduce Think3D, a framework that enables VLM agents to think with 3D space. By leveraging 3D reconstruction models that recover point clouds and camera poses from images or videos, Think3D allows the agent to actively manipulate space through camera-based operations and ego/global-view switching, transforming spatial reasoning into an interactive 3D chain-of-thought process. Without additional training, Think3D significantly improves the spatial reasoning performance of advanced models such as GPT-4.1 and Gemini 2.5 Pro, yielding average gains of +7.8% on BLINK Multi-view and MindCube, and +4.7% on VSI-Bench. We further show that smaller models, which struggle with spatial exploration, benefit significantly from a reinforcement learning policy that enables the model to select informative viewpoints and operations. With RL, the benefit from tool usage increases from +0.7% to +6.8%. Our findings demonstrate that training-free, tool-augmented spatial exploration is a viable path toward more flexible and human-like 3D reasoning in multimodal agents, establishing a new dimension of multimodal intelligence. Code and weights are released at https://github.com/zhangzaibin/spagent.