Open Vocabulary Panoptic Segmentation With Retrieval Augmentation
作者: Nafis Sadeq, Qingfeng Liu, Mostafa El-Khamy
分类: cs.CV, cs.CL
发布日期: 2026-01-19
💡 一句话要点
RetCLIP:提出检索增强的开放词汇全景分割方法,提升未见类别的分割性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇全景分割 检索增强 CLIP 未见类别分割 特征检索
📋 核心要点
- 现有全景分割模型泛化能力弱,难以有效分割训练集中未出现的类别。
- RetCLIP通过构建掩码分割特征数据库,利用检索增强来提升未见类别的分割性能。
- 实验表明,RetCLIP在ADE20k数据集上显著优于基线方法FC-CLIP,各项指标均有提升。
📝 摘要(中文)
本文提出了一种检索增强的全景分割方法RetCLIP,旨在提升开放词汇全景分割中未见类别的性能。该方法利用配对的图像-文本数据构建一个掩码分割特征数据库。在推理阶段,使用来自输入图像的掩码分割特征作为查询键,从数据库中检索相似的特征和相关的类别标签。基于查询特征和检索特征之间的相似性,为掩码分割分配分类得分。然后,将基于检索的分类得分与基于CLIP的得分相结合,生成最终输出。该方法在FC-CLIP的基础上进行改进,在COCO上训练,并在ADE20k数据集上取得了显著的性能提升,PQ指标提升4.5,mAP提升2.5,mIoU提升10.0。
🔬 方法详解
问题定义:开放词汇全景分割旨在根据用户输入的任意类别名称分割图像中的每个像素,但现有全景分割系统在特定数据集上训练后,通常难以很好地泛化到训练数据之外的未见类别。这限制了其在实际应用中的灵活性和通用性。
核心思路:RetCLIP的核心思路是利用检索增强来弥补模型对未见类别的认知不足。通过构建包含大量图像-文本对的特征数据库,模型可以在推理时检索与输入图像相似的已知类别信息,从而辅助判断未见类别的像素归属。这种方法借鉴了人类通过联想和类比来识别新事物的认知方式。
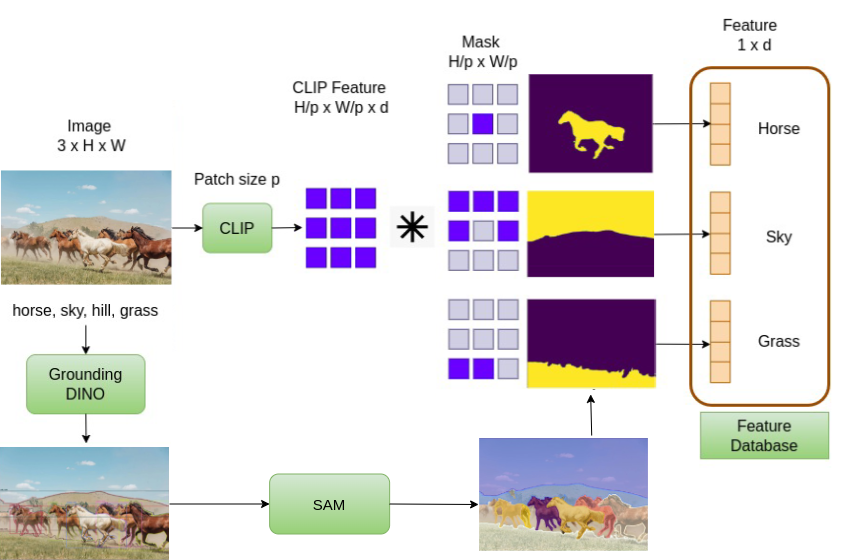
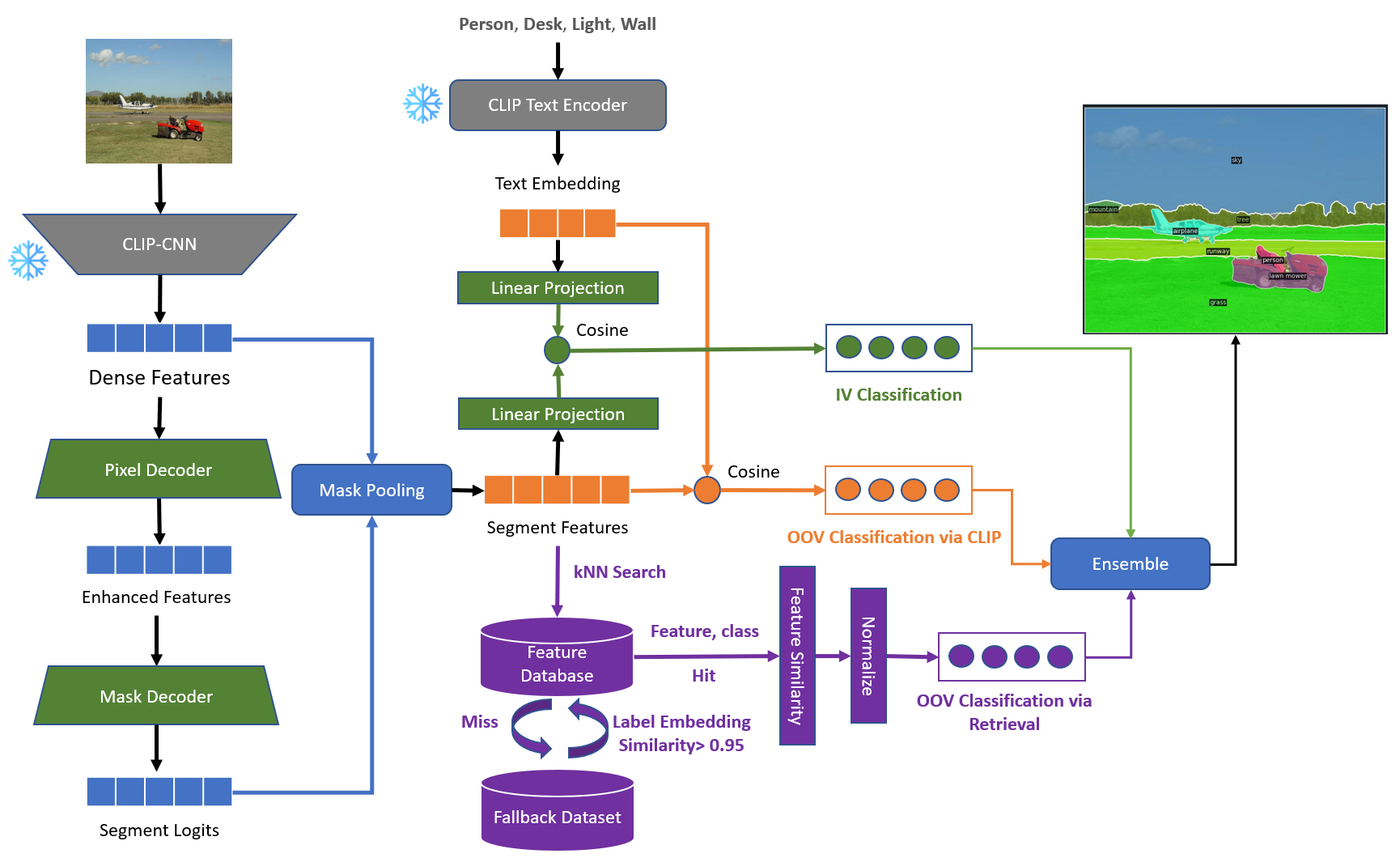
技术框架:RetCLIP的整体框架包括以下几个主要模块:1) 掩码分割特征提取:对输入图像进行分割,并提取每个分割区域的特征表示。2) 特征数据库构建:利用图像-文本对数据,提取分割区域的特征,并将其与对应的类别标签存储在数据库中。3) 检索模块:在推理时,使用输入图像的分割区域特征作为查询,从数据库中检索最相似的特征及其对应的类别标签。4) 分类得分融合:将检索得到的类别得分与CLIP模型预测的类别得分进行融合,得到最终的像素级分类结果。
关键创新:RetCLIP的关键创新在于将检索增强引入到开放词汇全景分割任务中。与传统的直接预测方法不同,RetCLIP通过检索相似的已知类别信息来辅助未见类别的分割,从而提高了模型的泛化能力。这种方法有效地利用了外部知识,弥补了模型自身训练数据的不足。
关键设计:RetCLIP的关键设计包括:1) 掩码分割特征的表示方式:如何有效地提取和表示分割区域的特征,使其能够准确地反映区域的语义信息。2) 特征数据库的构建策略:如何选择合适的图像-文本对数据,以及如何组织和存储特征,以便高效地进行检索。3) 检索算法的选择:如何选择合适的检索算法,以保证检索的准确性和效率。4) 分类得分的融合方式:如何将检索得到的类别得分与CLIP模型预测的类别得分进行有效地融合,以获得最佳的分割结果。具体参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
RetCLIP在ADE20k数据集上取得了显著的性能提升,PQ指标提升了4.5,mAP提升了2.5,mIoU提升了10.0。这些结果表明,RetCLIP能够有效地提升开放词汇全景分割中未见类别的分割性能,证明了检索增强方法的有效性。该方法在COCO数据集上进行训练,并在ADE20k数据集上进行测试,验证了其跨数据集的泛化能力。
🎯 应用场景
RetCLIP具有广泛的应用前景,例如智能安防、自动驾驶、医学图像分析等领域。它可以用于识别和分割图像中任意类别的物体,而无需重新训练模型。这使得它可以灵活地适应不同的应用场景,并降低了模型的部署成本。未来,RetCLIP可以进一步扩展到视频全景分割、3D场景理解等更复杂的任务中。
📄 摘要(原文)
Given an input image and set of class names, panoptic segmentation aims to label each pixel in an image with class labels and instance labels. In comparison, Open Vocabulary Panoptic Segmentation aims to facilitate the segmentation of arbitrary classes according to user input. The challenge is that a panoptic segmentation system trained on a particular dataset typically does not generalize well to unseen classes beyond the training data. In this work, we propose RetCLIP, a retrieval-augmented panoptic segmentation method that improves the performance of unseen classes. In particular, we construct a masked segment feature database using paired image-text data. At inference time, we use masked segment features from the input image as query keys to retrieve similar features and associated class labels from the database. Classification scores for the masked segment are assigned based on the similarity between query features and retrieved features. The retrieval-based classification scores are combined with CLIP-based scores to produce the final output. We incorporate our solution with a previous SOTA method (FC-CLIP). When trained on COCO, the proposed method demonstrates 30.9 PQ, 19.3 mAP, 44.0 mIoU on the ADE20k dataset, achieving +4.5 PQ, +2.5 mAP, +10.0 mIoU absolute improvement over the baseline.