Spatial-VLN: Zero-Shot Vision-and-Language Navigation With Explicit Spatial Perception and Exploration
作者: Lu Yue, Yue Fan, Shiwei Lian, Yu Zhao, Jiaxin Yu, Liang Xie, Feitian Zhang
分类: cs.CV, eess.SY
发布日期: 2026-01-19
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Spatial-VLN:利用显式空间感知和探索实现零样本视觉语言导航
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 零样本学习 空间感知 主动探索 大型语言模型 机器人导航 Sim2Real
📋 核心要点
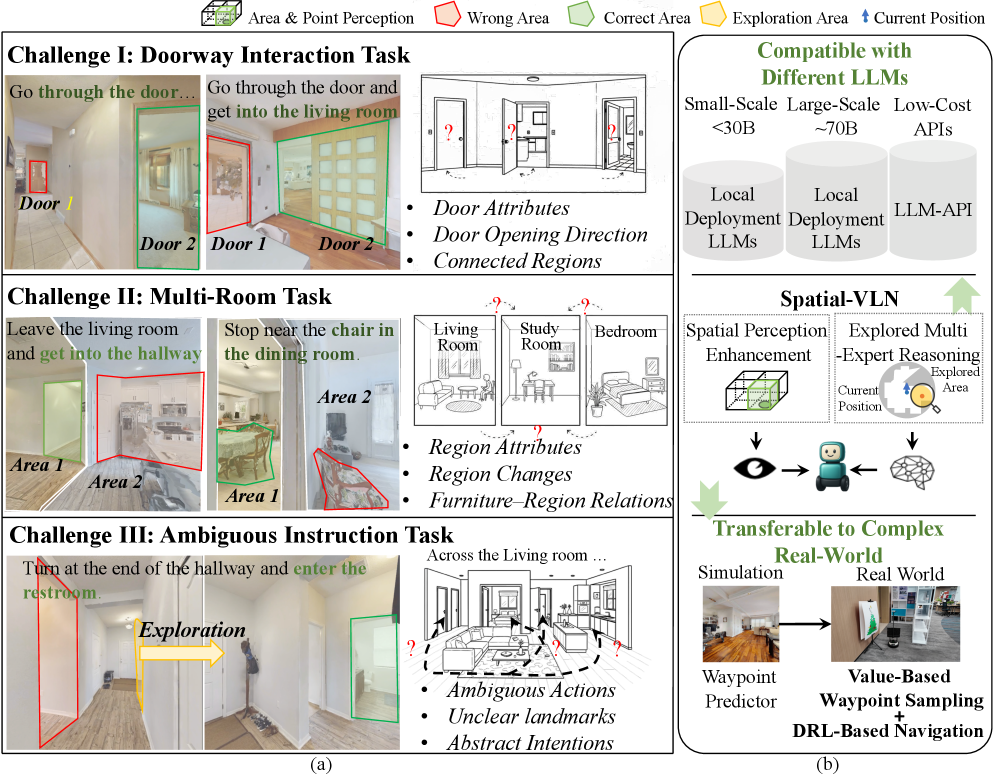
- 现有零样本视觉语言导航方法在复杂环境中空间感知不足,尤其是在门交互、多房间导航和模糊指令执行方面。
- Spatial-VLN通过空间感知增强模块和探索式多专家推理模块,提升空间感知能力,解决专家预测差异。
- 实验表明,Spatial-VLN在VLN-CE上取得了SOTA性能,并通过Sim2Real实验验证了其在真实世界中的泛化性和鲁棒性。
📝 摘要(中文)
本文提出Spatial-VLN,一个基于感知引导的探索框架,旨在克服复杂连续环境中零样本视觉语言导航(VLN)代理在空间感知上的不足。现有方法在门交互、多房间导航和模糊指令执行等空间挑战中表现不佳。Spatial-VLN包含两个主要模块:空间感知增强(SPE)模块,它整合了全景滤波和专门的门和区域专家,以产生空间连贯、跨视图一致的感知表示;探索式多专家推理(EMR)模块,它使用并行的LLM专家来处理航点级别的语义和区域级别的空间转换。当专家预测出现差异时,会激活查询和探索机制,促使代理主动探测关键区域并解决感知模糊。在VLN-CE上的实验表明,Spatial-VLN仅使用低成本LLM即可实现最先进的性能。此外,为了验证实际应用性,引入了一种基于价值的航点采样策略,有效地弥合了Sim2Real差距。广泛的真实世界评估证实了该框架在复杂环境中具有卓越的泛化性和鲁棒性。
🔬 方法详解
问题定义:现有零样本视觉语言导航(VLN)代理,特别是那些依赖大型语言模型(LLM)的代理,在泛化能力方面表现出色,但在复杂连续环境中,由于空间感知不足,导致在门交互、多房间导航和模糊指令执行等任务中失败率较高。现有方法难以有效地整合多视角的空间信息,并缺乏主动探索机制来解决感知歧义。
核心思路:Spatial-VLN的核心思路是通过显式的空间感知和主动探索来弥补现有方法的不足。它通过整合全景滤波和领域专家来增强空间感知,并利用多专家推理和查询-探索机制来解决感知歧义。这种设计旨在使代理能够更好地理解环境的空间结构,并主动地探索未知的区域,从而提高导航的成功率。
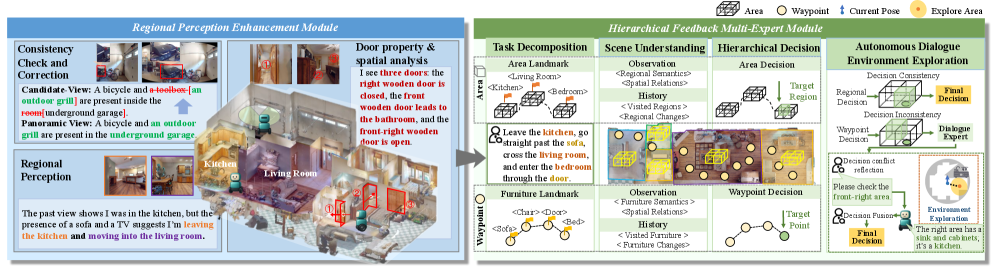
技术框架:Spatial-VLN框架包含两个主要模块:空间感知增强(SPE)模块和探索式多专家推理(EMR)模块。SPE模块负责生成空间连贯、跨视图一致的感知表示,它通过全景滤波来整合多视角的空间信息,并使用专门的门和区域专家来识别关键的空间特征。EMR模块则利用并行的LLM专家来处理航点级别的语义和区域级别的空间转换,当专家预测出现差异时,会激活查询和探索机制,促使代理主动探测关键区域并解决感知模糊。
关键创新:Spatial-VLN的关键创新在于其显式的空间感知和主动探索机制。与现有方法相比,它更加注重对环境空间结构的理解,并能够主动地探索未知的区域,从而更好地解决感知歧义。此外,该框架还引入了一种基于价值的航点采样策略,有效地弥合了Sim2Real差距。
关键设计:SPE模块中的全景滤波采用了一种加权平均的方法来整合多视角的空间信息,权重可以根据视角的质量和相关性进行调整。门和区域专家则采用了卷积神经网络(CNN)来提取图像中的空间特征,并使用softmax函数来预测门或区域的类型。EMR模块中的LLM专家可以采用不同的模型结构和训练目标,以适应不同的任务需求。查询和探索机制则采用了一种基于信息增益的策略来选择需要探索的区域。
🖼️ 关键图片

📊 实验亮点
Spatial-VLN在VLN-CE数据集上取得了最先进的性能,证明了其在复杂环境中的有效性。此外,通过Sim2Real实验,验证了该框架在真实世界中的泛化性和鲁棒性。实验结果表明,Spatial-VLN能够显著提高零样本VLN代理的导航成功率,并有效地解决感知歧义问题。
🎯 应用场景
Spatial-VLN的研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。该技术能够提升机器人在复杂环境中的自主导航能力,使其能够更好地理解和执行人类指令,具有广泛的应用前景和实际价值。未来,该技术有望进一步发展,实现更高级别的自主性和智能化。
📄 摘要(原文)
Zero-shot Vision-and-Language Navigation (VLN) agents leveraging Large Language Models (LLMs) excel in generalization but suffer from insufficient spatial perception. Focusing on complex continuous environments, we categorize key perceptual bottlenecks into three spatial challenges: door interaction,multi-room navigation, and ambiguous instruction execution, where existing methods consistently suffer high failure rates. We present Spatial-VLN, a perception-guided exploration framework designed to overcome these challenges. The framework consists of two main modules. The Spatial Perception Enhancement (SPE) module integrates panoramic filtering with specialized door and region experts to produce spatially coherent, cross-view consistent perceptual representations. Building on this foundation, our Explored Multi-expert Reasoning (EMR) module uses parallel LLM experts to address waypoint-level semantics and region-level spatial transitions. When discrepancies arise between expert predictions, a query-and-explore mechanism is activated, prompting the agent to actively probe critical areas and resolve perceptual ambiguities. Experiments on VLN-CE demonstrate that Spatial VLN achieves state-of-the-art performance using only low-cost LLMs. Furthermore, to validate real-world applicability, we introduce a value-based waypoint sampling strategy that effectively bridges the Sim2Real gap. Extensive real-world evaluations confirm that our framework delivers superior generalization and robustness in complex environments. Our codes and videos are available at https://yueluhhxx.github.io/Spatial-VLN-web/.