Moaw: Unleashing Motion Awareness for Video Diffusion Models
作者: Tianqi Zhang, Ziyi Wang, Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Zhengyang Huang, Jie Zhou, Jiwen Lu
分类: cs.CV
发布日期: 2026-01-19
💡 一句话要点
Moaw:释放视频扩散模型的运动感知能力,实现零样本运动迁移
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频扩散模型 运动感知 运动迁移 零样本学习 视频生成
📋 核心要点
- 现有视频扩散模型在运动理解方面潜力未被充分挖掘,缺乏有效的训练方法来增强其运动感知能力。
- Moaw框架通过有监督训练,将视频扩散模型从视频生成转变为视频密集跟踪,从而提升运动感知能力。
- Moaw框架实现了零样本运动迁移,无需额外适配器,为统一和可控的视频学习框架奠定基础。
📝 摘要(中文)
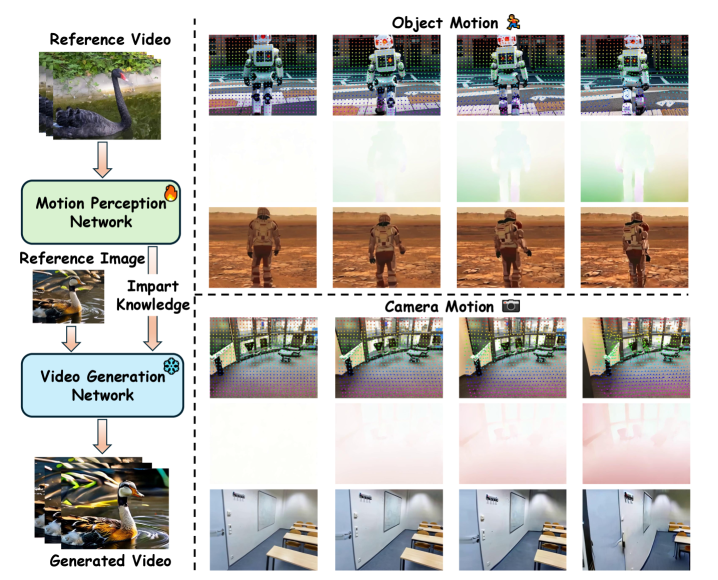
视频扩散模型在大型数据集上训练后,自然地捕获了跨帧共享特征的对应关系。最近的研究利用这一特性,在零样本设置中实现了光流预测和跟踪等任务。受此启发,我们研究了有监督训练是否能更充分地利用视频扩散模型的跟踪能力。为此,我们提出了Moaw,一个释放视频扩散模型运动感知能力的框架,并利用它来促进运动迁移。具体来说,我们训练了一个用于运动感知的扩散模型,将其模态从图像到视频生成转变为视频到密集跟踪。然后,我们构建了一个运动标记数据集,以识别编码最强运动信息的特征,并将它们注入到结构相同的视频生成模型中。由于两个网络之间的同质性,这些特征可以自然地以零样本方式适应,从而无需额外的适配器即可实现运动迁移。我们的工作为桥接生成建模和运动理解提供了一种新的范例,为更统一和可控的视频学习框架铺平了道路。
🔬 方法详解
问题定义:现有视频扩散模型虽然具备一定的运动感知能力,但主要集中在生成任务上,缺乏针对运动理解的专门训练,导致其在运动相关任务上的性能受限。现有方法通常需要额外的适配器或微调才能实现运动迁移,增加了复杂性和计算成本。
核心思路:Moaw的核心思路是将视频扩散模型训练成一个运动感知器,使其能够准确地预测视频帧之间的密集运动信息。然后,将学习到的运动特征迁移到视频生成模型中,从而增强生成模型对运动的理解和控制能力。这种方法利用了扩散模型在特征空间中的平滑性和可迁移性。
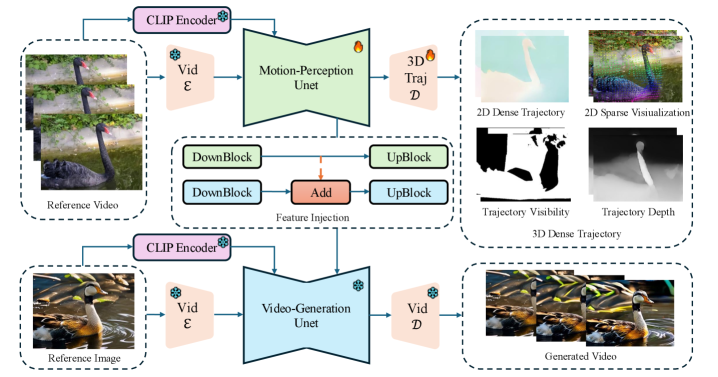
技术框架:Moaw框架包含两个主要阶段:1) 运动感知训练阶段:训练一个视频扩散模型,使其能够根据输入的视频帧预测密集光流。该模型以视频帧作为输入,输出预测的光流场。2) 运动特征注入阶段:将运动感知模型学习到的运动特征注入到结构相同的视频生成模型中。具体来说,将运动感知模型的中间层特征图复制到视频生成模型的对应层。
关键创新:Moaw的关键创新在于:1) 将视频扩散模型用于运动感知任务,并进行有监督训练,显著提升了模型的运动理解能力。2) 提出了一种零样本运动迁移方法,无需额外的适配器或微调,即可将运动特征从运动感知模型迁移到视频生成模型。
关键设计:在运动感知训练阶段,使用L1损失函数来衡量预测光流和真实光流之间的差异。在运动特征注入阶段,选择合适的中间层特征图进行迁移,以平衡运动信息的丰富性和特征的泛化能力。两个模型采用相同的网络结构,以保证特征的可迁移性。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了Moaw框架的有效性。实验结果表明,Moaw框架能够显著提升视频生成模型在运动相关任务上的性能,例如运动迁移和动作编辑。与现有方法相比,Moaw框架在零样本设置下取得了更优的结果,证明了其在运动感知和迁移方面的优势。
🎯 应用场景
Moaw框架具有广泛的应用前景,例如视频编辑、动作迁移、视频增强、以及虚拟现实和增强现实等领域。它可以用于创建更逼真、更可控的视频内容,并为视频理解和生成任务提供更强大的工具。该研究为开发更智能、更灵活的视频处理系统奠定了基础。
📄 摘要(原文)
Video diffusion models, trained on large-scale datasets, naturally capture correspondences of shared features across frames. Recent works have exploited this property for tasks such as optical flow prediction and tracking in a zero-shot setting. Motivated by these findings, we investigate whether supervised training can more fully harness the tracking capability of video diffusion models. To this end, we propose Moaw, a framework that unleashes motion awareness for video diffusion models and leverages it to facilitate motion transfer. Specifically, we train a diffusion model for motion perception, shifting its modality from image-to-video generation to video-to-dense-tracking. We then construct a motion-labeled dataset to identify features that encode the strongest motion information, and inject them into a structurally identical video generation model. Owing to the homogeneity between the two networks, these features can be naturally adapted in a zero-shot manner, enabling motion transfer without additional adapters. Our work provides a new paradigm for bridging generative modeling and motion understanding, paving the way for more unified and controllable video learning frameworks.