DC-VLAQ: Query-Residual Aggregation for Robust Visual Place Recognition
作者: Hanyu Zhu, Zhihao Zhan, Yuhang Ming, Liang Li, Dibo Hou, Javier Civera, Wanzeng Kong
分类: cs.CV, cs.RO
发布日期: 2026-01-19
备注: 10 pages, 4 figures, 5 tables
💡 一句话要点
提出DC-VLAQ,通过查询残差聚合实现鲁棒的视觉定位识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位识别 全局特征聚合 视觉基础模型 残差学习 查询聚合
📋 核心要点
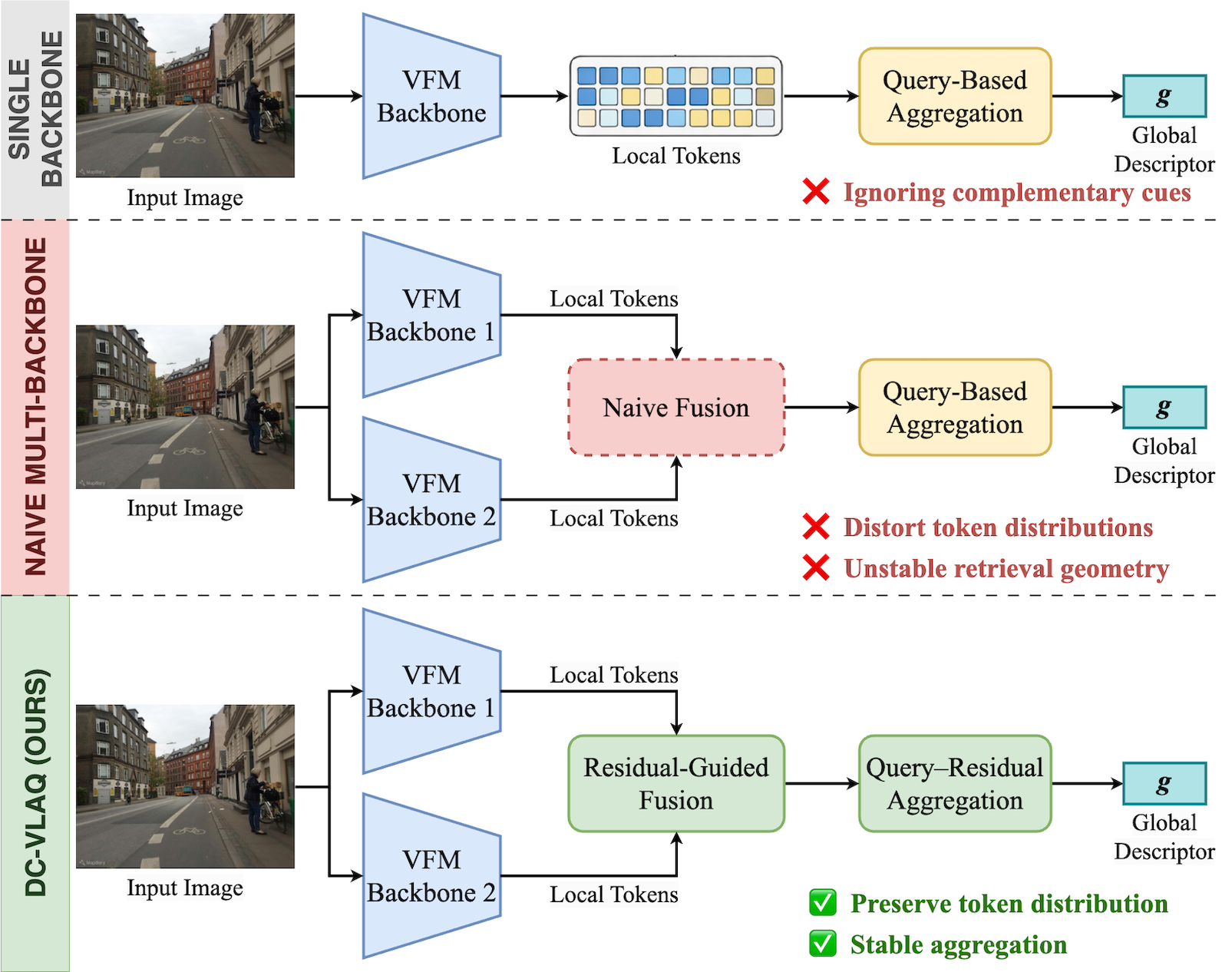
- 现有VPR方法依赖单一视觉基础模型,忽略了不同模型提供的互补信息,导致全局表示在复杂场景下鲁棒性不足。
- 提出DC-VLAQ框架,通过残差引导的互补模型融合和局部聚合查询向量(VLAQ)聚合,提升全局表示的稳定性和区分性。
- 在多个VPR基准测试中,DC-VLAQ显著优于现有方法,尤其在领域偏移和长期外观变化等挑战性场景下表现突出。
📝 摘要(中文)
视觉定位识别(VPR)的核心挑战之一是学习一种鲁棒的全局表示,使其在视角变化、光照变化和严重的领域偏移下仍具有区分性。虽然视觉基础模型(VFMs)提供了强大的局部特征,但现有方法大多依赖于单一模型,忽略了不同VFMs提供的互补线索。然而,利用这种互补信息不可避免地会改变token分布,这对现有的基于查询的全局聚合方案的稳定性提出了挑战。为了解决这些挑战,我们提出了一种以表示为中心的框架DC-VLAQ,该框架集成了互补VFMs的融合和鲁棒的全局聚合。具体来说,我们首先引入了一种轻量级的残差引导互补融合,它将表示锚定在DINOv2特征空间中,同时通过学习到的残差校正注入来自CLIP的互补语义。此外,我们提出了局部聚合查询向量(VLAQ),这是一种查询-残差全局聚合方案,它通过局部tokens对可学习查询的残差响应进行编码,从而提高稳定性和保留细粒度的区分线索。在标准VPR基准(包括Pitts30k、Tokyo24/7、MSLS、Nordland、SPED和AmsterTime)上的大量实验表明,DC-VLAQ始终优于强大的基线,并实现了最先进的性能,尤其是在具有挑战性的领域偏移和长期外观变化下。
🔬 方法详解
问题定义:视觉定位识别(VPR)旨在确定查询图像在已知环境中的位置。现有方法通常依赖单一视觉基础模型提取特征,但不同模型具有不同的优势,简单地组合这些模型会导致token分布不稳定,影响全局表示的鲁棒性。此外,现有全局聚合方法难以在保持稳定性的同时,有效利用细粒度的区分性线索。
核心思路:DC-VLAQ的核心思路是融合互补的视觉基础模型,同时保持token分布的稳定性,并设计一种能够有效聚合局部特征并保留细粒度信息的全局聚合方案。通过残差学习的方式融合不同模型的特征,避免直接拼接导致的分布偏移。利用查询-残差聚合,将局部特征编码为对可学习查询的残差响应,从而提高稳定性和区分性。
技术框架:DC-VLAQ框架主要包含两个阶段:互补视觉基础模型融合和全局特征聚合。首先,利用残差引导的互补融合模块,将DINOv2和CLIP的特征进行融合,其中DINOv2提供稳定的特征空间,CLIP提供互补的语义信息。然后,通过局部聚合查询向量(VLAQ)模块,将融合后的局部特征聚合为全局表示。VLAQ模块使用一组可学习的查询向量,计算每个局部特征对这些查询的残差响应,并将这些响应聚合为全局特征。
关键创新:DC-VLAQ的关键创新在于残差引导的互补模型融合和查询-残差全局聚合。残差融合避免了直接拼接不同模型特征导致的分布偏移,提高了特征的稳定性。查询-残差聚合将局部特征编码为对可学习查询的残差响应,能够有效保留细粒度的区分性信息,并提高聚合的鲁棒性。
关键设计:残差融合模块使用一个轻量级的网络学习CLIP特征到DINOv2特征的残差映射,并将该残差加到DINOv2特征上。VLAQ模块使用一组可学习的查询向量,通过计算局部特征与查询向量之间的相似度,得到残差响应。相似度计算采用余弦相似度,并使用softmax函数进行归一化。最终的全局特征是残差响应的加权和。
🖼️ 关键图片

📊 实验亮点
DC-VLAQ在多个VPR基准测试中取得了state-of-the-art的性能。例如,在Tokyo24/7数据集上,DC-VLAQ相比于现有最佳方法提升了5%以上的Recall@1。在具有挑战性的领域偏移数据集SPED和AmsterTime上,DC-VLAQ的性能提升更为显著,表明其具有更强的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。通过提升视觉定位的鲁棒性和准确性,可以提高自动驾驶车辆在复杂环境下的定位精度,增强机器人在未知环境中的导航能力,并为增强现实应用提供更稳定的定位基础。该研究对于提升智能系统的环境感知能力具有重要意义。
📄 摘要(原文)
One of the central challenges in visual place recognition (VPR) is learning a robust global representation that remains discriminative under large viewpoint changes, illumination variations, and severe domain shifts. While visual foundation models (VFMs) provide strong local features, most existing methods rely on a single model, overlooking the complementary cues offered by different VFMs. However, exploiting such complementary information inevitably alters token distributions, which challenges the stability of existing query-based global aggregation schemes. To address these challenges, we propose DC-VLAQ, a representation-centric framework that integrates the fusion of complementary VFMs and robust global aggregation. Specifically, we first introduce a lightweight residual-guided complementary fusion that anchors representations in the DINOv2 feature space while injecting complementary semantics from CLIP through a learned residual correction. In addition, we propose the Vector of Local Aggregated Queries (VLAQ), a query--residual global aggregation scheme that encodes local tokens by their residual responses to learnable queries, resulting in improved stability and the preservation of fine-grained discriminative cues. Extensive experiments on standard VPR benchmarks, including Pitts30k, Tokyo24/7, MSLS, Nordland, SPED, and AmsterTime, demonstrate that DC-VLAQ consistently outperforms strong baselines and achieves state-of-the-art performance, particularly under challenging domain shifts and long-term appearance changes.