Fusing in 3D: Free-Viewpoint Fusion Rendering with a 3D Infrared-Visible Scene Representation
作者: Chao Yang, Deshui Miao, Chao Tian, Guoqing Zhu, Yameng Gu, Zhenyu He
分类: cs.CV, cs.CG
发布日期: 2026-01-19
💡 一句话要点
提出基于3D红外-可见光场景表示的自由视角融合渲染方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 红外可见光融合 3D场景重建 高斯表示 跨模态调整 自由视角渲染
📋 核心要点
- 现有2D红外-可见光图像融合方法缺乏对场景的全面理解,导致关键信息丢失。
- 提出红外-可见光高斯融合(IVGF)框架,从多模态2D输入重建场景几何结构并渲染融合图像。
- 引入跨模态调整(CMA)模块和融合损失,解决跨模态冲突并保留各模态的关键特征。
📝 摘要(中文)
红外-可见光图像融合旨在将红外和可见光信息整合到单个融合图像中。现有的2D融合方法侧重于融合来自固定相机视角的图像,忽略了对复杂场景的全面理解,导致场景关键信息的丢失。为了解决这个局限性,我们提出了一种新颖的红外-可见光高斯融合(IVGF)框架,该框架从多模态2D输入重建场景几何结构,并能够直接渲染融合图像。具体来说,我们提出了一个跨模态调整(CMA)模块,该模块调节高斯函数的透明度,以解决跨模态冲突问题。此外,为了保留来自两种模态的独特特征,我们引入了一种融合损失,该损失指导CMA的优化,从而确保融合图像保留每种模态的关键特征。全面的定性和定量实验证明了该方法的有效性。
🔬 方法详解
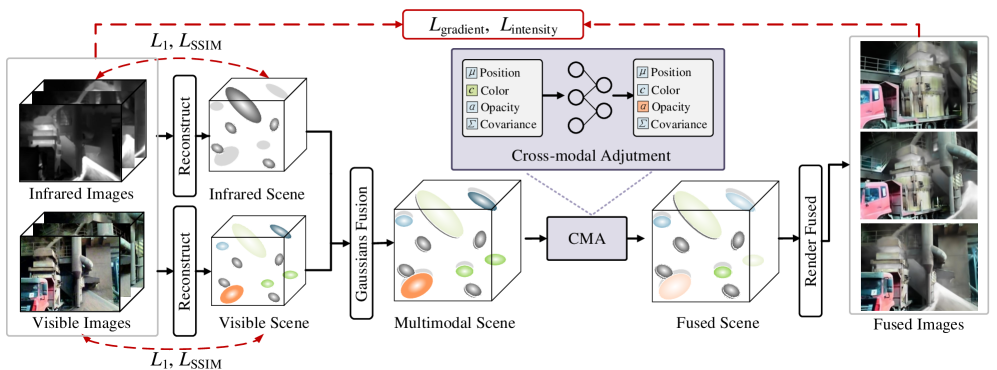
问题定义:现有红外-可见光图像融合方法主要集中在2D图像的融合,忽略了场景的3D几何信息,导致在复杂场景下融合效果不佳,且无法实现自由视角的渲染。这些方法通常依赖于固定视角的图像,无法充分利用多视角信息,导致关键信息的丢失。因此,需要一种能够理解场景3D结构并支持自由视角渲染的融合方法。
核心思路:论文的核心思路是利用3D高斯表示来建模红外和可见光场景,并在此基础上进行融合。通过将2D图像重建为3D场景,可以更好地理解场景的几何结构和多视角信息,从而实现更准确、更全面的融合。此外,通过直接在3D空间中进行融合,可以实现自由视角的渲染,从而提供更灵活的应用。
技术框架:该方法主要包含以下几个阶段:1) 多模态2D图像输入:输入红外和可见光图像。2) 3D场景重建:利用多视角图像重建3D高斯场景表示。3) 跨模态调整(CMA):通过CMA模块调节高斯函数的透明度,解决跨模态冲突。4) 融合损失优化:利用融合损失指导CMA的优化,保留各模态的关键特征。5) 自由视角渲染:从任意视角渲染融合图像。
关键创新:该方法最重要的技术创新点在于提出了基于3D高斯表示的红外-可见光融合框架,并引入了跨模态调整(CMA)模块和融合损失。与现有方法相比,该方法能够更好地理解场景的3D结构,解决跨模态冲突,并保留各模态的关键特征,从而实现更准确、更全面的融合。此外,该方法还支持自由视角的渲染,提供了更灵活的应用。
关键设计:CMA模块的设计是关键。它通过学习一个权重来调整每个高斯分量的透明度,从而解决红外和可见光信息之间的冲突。融合损失的设计也至关重要,它由多个损失项组成,包括内容损失、梯度损失和结构相似性损失,用于指导CMA的优化,确保融合图像保留各模态的关键特征。具体的参数设置和网络结构细节在论文中有详细描述,但摘要中未提供。
🖼️ 关键图片


📊 实验亮点
论文通过定性和定量实验验证了所提出方法的有效性。实验结果表明,该方法在融合图像的质量和信息保留方面优于现有的2D融合方法。具体的性能数据和对比基线在摘要中未提供,但强调了该方法在解决跨模态冲突和保留各模态特征方面的优势。
🎯 应用场景
该研究成果可应用于安防监控、自动驾驶、夜视成像、搜救行动等领域。通过融合红外和可见光信息,可以提高在恶劣光照条件下的目标检测和识别能力,增强环境感知能力,从而提升系统的可靠性和安全性。未来,该技术有望在智能交通、智慧城市等领域发挥重要作用。
📄 摘要(原文)
Infrared-visible image fusion aims to integrate infrared and visible information into a single fused image. Existing 2D fusion methods focus on fusing images from fixed camera viewpoints, neglecting a comprehensive understanding of complex scenarios, which results in the loss of critical information about the scene. To address this limitation, we propose a novel Infrared-Visible Gaussian Fusion (IVGF) framework, which reconstructs scene geometry from multimodal 2D inputs and enables direct rendering of fused images. Specifically, we propose a cross-modal adjustment (CMA) module that modulates the opacity of Gaussians to solve the problem of cross-modal conflicts. Moreover, to preserve the distinctive features from both modalities, we introduce a fusion loss that guides the optimization of CMA, thus ensuring that the fused image retains the critical characteristics of each modality. Comprehensive qualitative and quantitative experiments demonstrate the effectiveness of the proposed method.