Generative Scenario Rollouts for End-to-End Autonomous Driving
作者: Rajeev Yasarla, Deepti Hegde, Shizhong Han, Hsin-Pai Cheng, Yunxiao Shi, Meysam Sadeghigooghari, Shweta Mahajan, Apratim Bhattacharyya, Litian Liu, Risheek Garrepalli, Thomas Svantesson, Fatih Porikli, Hong Cai
分类: cs.CV
发布日期: 2026-01-16
💡 一句话要点
提出GeRo框架,通过生成式场景展开提升端到端自动驾驶性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端到端自动驾驶 视觉-语言-动作模型 生成式模型 场景展开 自回归生成
📋 核心要点
- 现有端到端自动驾驶VLA模型主要依赖模仿学习,未能充分发挥其生成潜力,限制了长时程推理和场景理解。
- GeRo框架通过自回归方式,生成语言相关的未来交通场景,并结合rollout一致性损失,提升规划和生成的文本对齐。
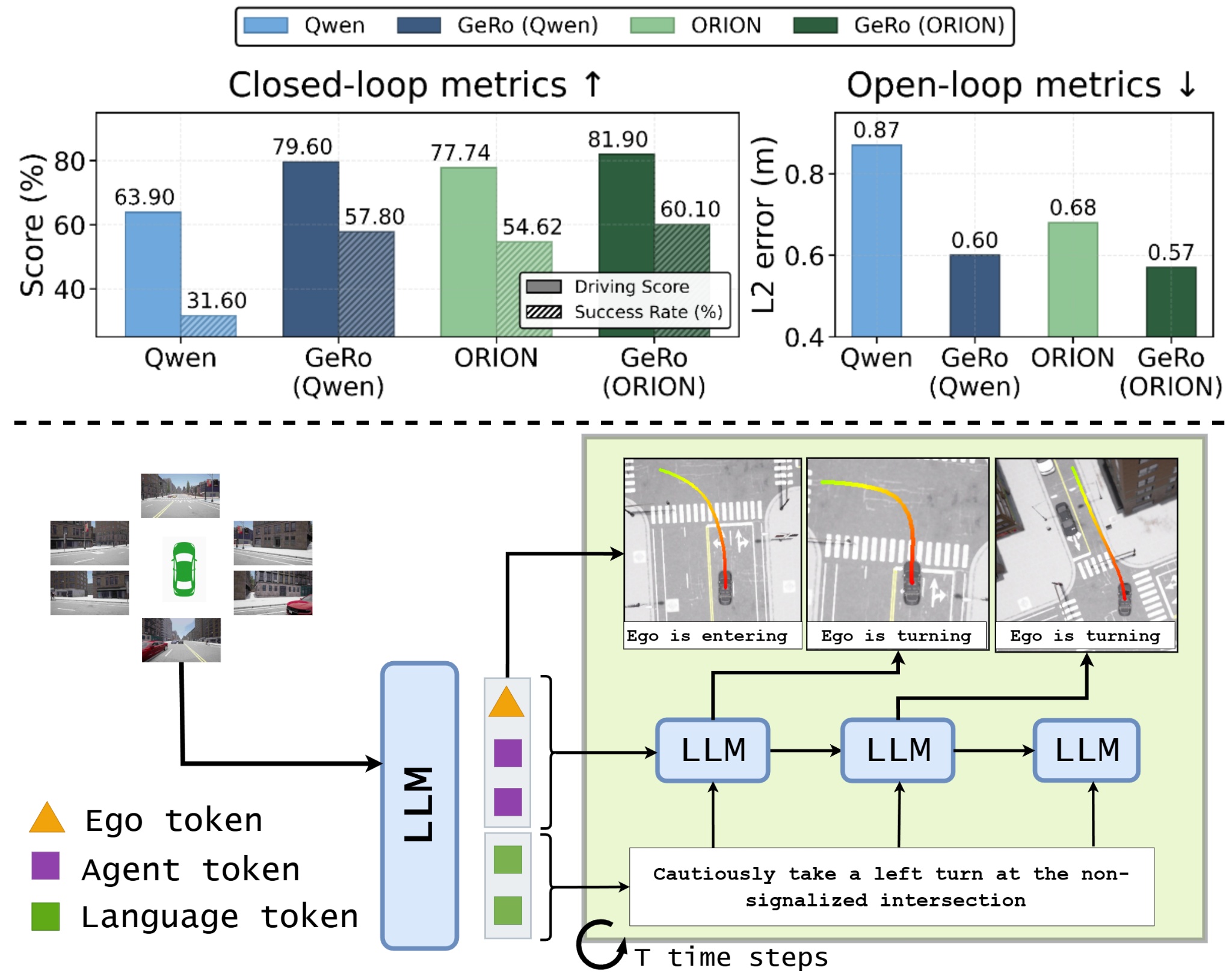
- 实验表明,GeRo在驾驶分数和成功率上显著提升,并展现出强大的零样本鲁棒性,验证了生成式推理的有效性。
📝 摘要(中文)
视觉-语言-动作(VLA)模型正成为端到端自动驾驶系统中高效的规划模型。然而,目前的工作主要依赖于来自稀疏轨迹标注的模仿学习,并且未能充分利用它们作为生成模型的潜力。我们提出了生成式场景展开(GeRo),一个VLA模型的即插即用框架,它通过自回归展开策略联合执行规划和生成语言相关的未来交通场景。首先,训练一个VLA模型,在规划、运动和语言任务的监督下,将自我车辆和智能体动态编码为潜在token,从而促进文本对齐的生成。接下来,GeRo执行语言条件下的自回归生成。给定多视角图像、场景描述和自我动作问题,它生成未来的潜在token和文本响应,以指导长时程展开。使用ground truth或伪标签的展开一致性损失稳定预测,减轻漂移并保持文本-动作对齐。这种设计使GeRo能够执行时间上一致的、语言相关的展开,从而支持长时程推理和多智能体规划。在Bench2Drive上,GeRo的驾驶分数和成功率分别提高了+15.7和+26.2。通过将强化学习与生成式展开相结合,GeRo实现了最先进的闭环和开环性能,展示了强大的零样本鲁棒性。这些结果突出了生成式、语言条件推理作为更安全、更可解释的端到端自动驾驶基础的希望。
🔬 方法详解
问题定义:现有端到端自动驾驶系统,特别是基于视觉-语言-动作(VLA)模型的系统,主要依赖于模仿学习,即直接从人类驾驶员的轨迹数据中学习。这种方法的痛点在于,它无法充分利用VLA模型作为生成模型的潜力,难以进行长时程的规划和推理,并且对未见过的新场景泛化能力较弱。此外,模仿学习难以保证生成场景与语言描述的一致性。
核心思路:GeRo的核心思路是将VLA模型视为一个生成模型,通过自回归的方式生成未来场景的展开(rollout)。给定当前场景的视觉信息和语言描述,模型预测未来的状态和动作,并重复这个过程来模拟未来的演变。这种生成式的方法能够更好地利用VLA模型的潜力,进行长时程的规划和推理,并提高对新场景的泛化能力。同时,通过语言条件生成,保证了生成场景与语言描述的一致性。
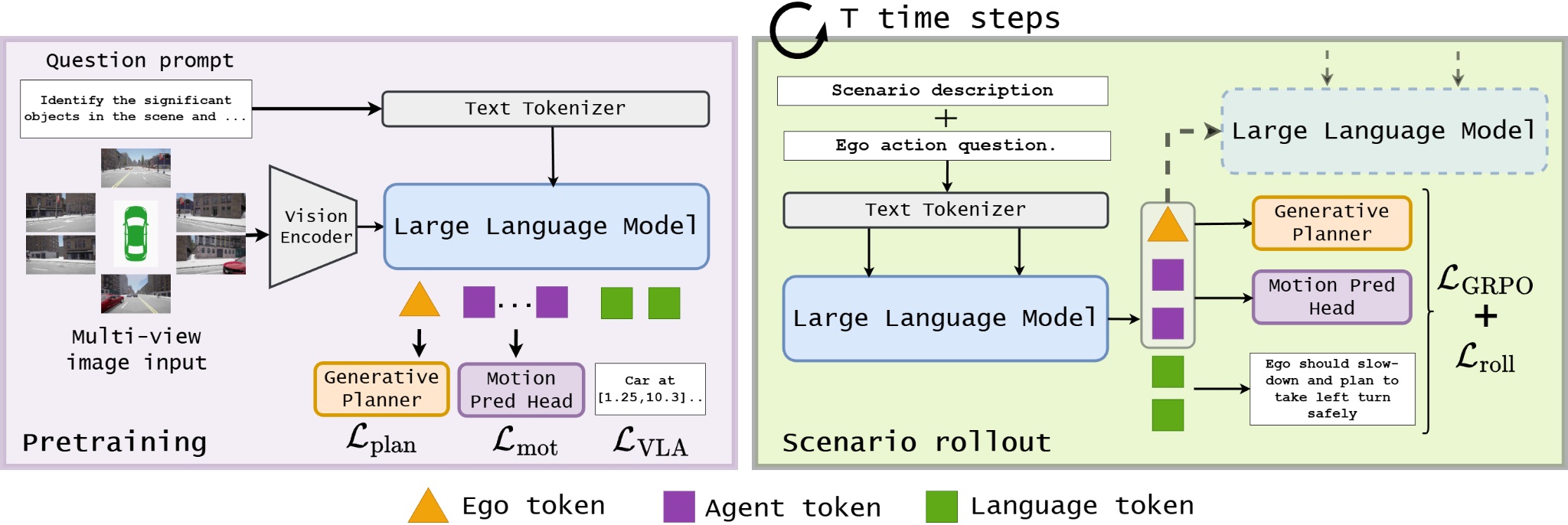
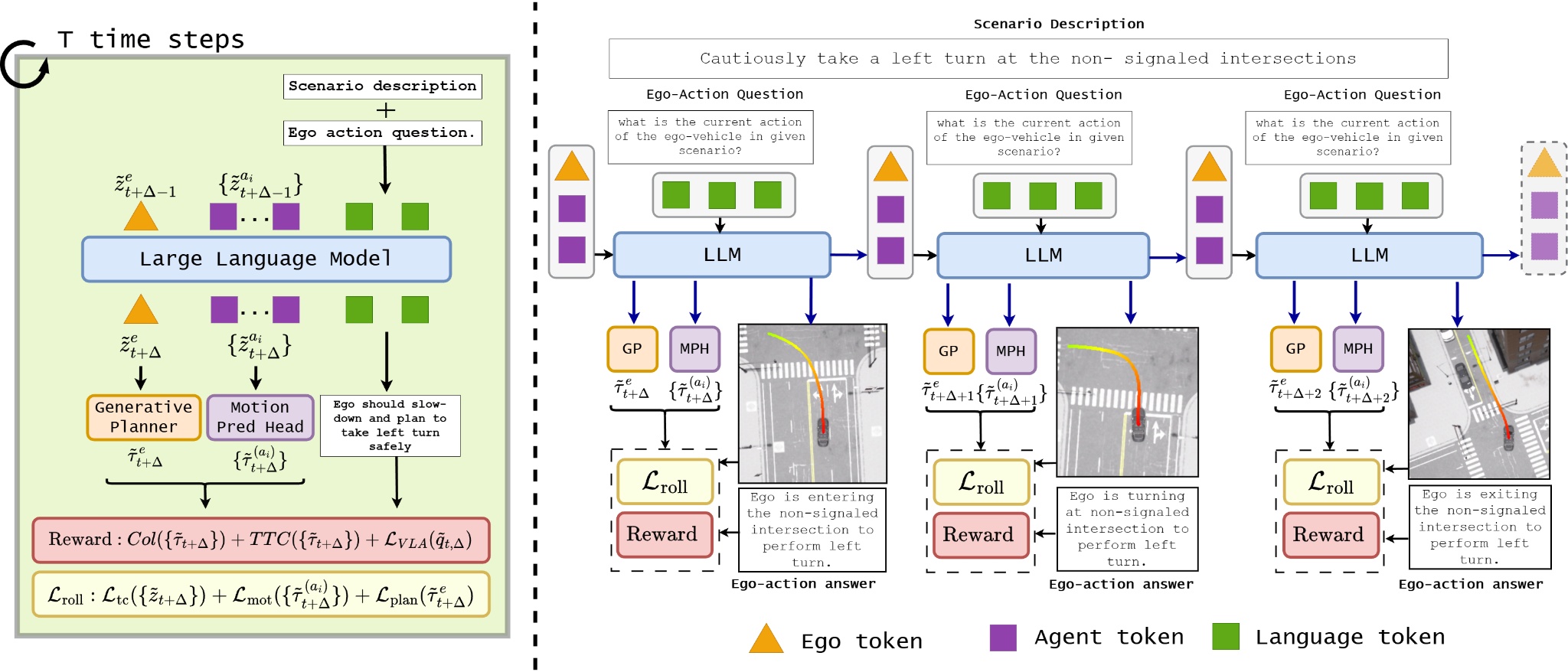
技术框架:GeRo框架包含以下主要模块:1) VLA模型训练:使用规划、运动和语言任务的监督信号,训练VLA模型将自我车辆和智能体的动态编码为潜在token。2) 语言条件自回归生成:给定多视角图像、场景描述和自我动作问题,VLA模型生成未来的潜在token和文本响应。3) Rollout一致性损失:使用ground truth或伪标签,通过rollout一致性损失来稳定预测,减轻漂移并保持文本-动作对齐。
关键创新:GeRo最重要的技术创新点在于其生成式场景展开(Generative Scenario Rollouts)的思想。与传统的模仿学习方法不同,GeRo不是简单地模仿人类驾驶员的行为,而是通过生成未来的场景来指导规划。这种方法能够更好地利用VLA模型的潜力,进行长时程的推理和规划,并提高对新场景的泛化能力。此外,rollout一致性损失也是一个重要的创新,它能够稳定预测,减轻漂移,并保持文本-动作对齐。
关键设计:GeRo的关键设计包括:1) VLA模型的选择:论文中使用的VLA模型是基于Transformer的架构,能够有效地处理视觉、语言和动作信息。2) 损失函数的设计:除了rollout一致性损失外,还使用了规划、运动和语言任务的监督信号来训练VLA模型。3) 自回归生成策略:通过自回归的方式生成未来的场景,能够进行长时程的规划和推理。4) 强化学习的集成:通过将强化学习与生成式展开相结合,进一步提升了模型的性能。
🖼️ 关键图片
📊 实验亮点
GeRo在Bench2Drive数据集上取得了显著的性能提升,驾驶分数提高了15.7,成功率提高了26.2。通过与强化学习相结合,GeRo实现了最先进的闭环和开环性能,并展现出强大的零样本鲁棒性。这些结果表明,GeRo框架在端到端自动驾驶领域具有巨大的潜力。
🎯 应用场景
GeRo框架可应用于自动驾驶系统的仿真测试、场景生成和决策规划。通过生成逼真的未来交通场景,可以更有效地评估自动驾驶系统的安全性和鲁棒性。此外,GeRo还可以用于训练自动驾驶系统,提高其在复杂和未知环境中的适应能力。该研究有望推动自动驾驶技术的进步,使其更加安全可靠。
📄 摘要(原文)
Vision-Language-Action (VLA) models are emerging as highly effective planning models for end-to-end autonomous driving systems. However, current works mostly rely on imitation learning from sparse trajectory annotations and under-utilize their potential as generative models. We propose Generative Scenario Rollouts (GeRo), a plug-and-play framework for VLA models that jointly performs planning and generation of language-grounded future traffic scenes through an autoregressive rollout strategy. First, a VLA model is trained to encode ego vehicle and agent dynamics into latent tokens under supervision from planning, motion, and language tasks, facilitating text-aligned generation. Next, GeRo performs language-conditioned autoregressive generation. Given multi-view images, a scenario description, and ego-action questions, it generates future latent tokens and textual responses to guide long-horizon rollouts. A rollout-consistency loss stabilizes predictions using ground truth or pseudo-labels, mitigating drift and preserving text-action alignment. This design enables GeRo to perform temporally consistent, language-grounded rollouts that support long-horizon reasoning and multi-agent planning. On Bench2Drive, GeRo improves driving score and success rate by +15.7 and +26.2, respectively. By integrating reinforcement learning with generative rollouts, GeRo achieves state-of-the-art closed-loop and open-loop performance, demonstrating strong zero-shot robustness. These results highlight the promise of generative, language-conditioned reasoning as a foundation for safer and more interpretable end-to-end autonomous driving.