Map2Thought: Explicit 3D Spatial Reasoning via Metric Cognitive Maps
作者: Xiangjun Gao, Zhensong Zhang, Dave Zhenyu Chen, Songcen Xu, Long Quan, Eduardo Pérez-Pellitero, Youngkyoon Jang
分类: cs.CV, cs.AI
发布日期: 2026-01-16
💡 一句话要点
提出Map2Thought框架,通过度量认知地图实现3D视觉语言模型中显式的空间推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉语言模型 空间推理 认知地图 可解释性 几何理解
📋 核心要点
- 现有3D视觉语言模型缺乏显式空间推理能力,难以解释其决策过程,限制了其在复杂场景中的应用。
- Map2Thought框架通过构建度量认知地图,结合离散关系推理和连续几何理解,实现显式的、可解释的空间推理。
- 实验表明,Map2Thought在VSI-Bench数据集上优于现有方法,并且在少量数据监督下也能取得接近全监督的性能。
📝 摘要(中文)
本文提出Map2Thought框架,旨在为3D视觉语言模型(VLM)提供显式且可解释的空间推理能力。该框架基于两个关键组件:度量认知地图(Metric-CogMap)和认知链式思考(Cog-CoT)。Metric-CogMap通过整合用于关系推理的离散网格和用于精确几何理解的连续度量尺度表示,提供统一的空间表示。在Metric-CogMap的基础上,Cog-CoT通过确定性操作执行显式的几何推理,包括向量运算、边界框距离和遮挡感知的表观顺序线索,从而产生基于3D结构的可解释推理轨迹。实验结果表明,Map2Thought能够实现可解释的3D理解,仅使用一半的监督数据即可达到59.9%的准确率,与使用完整数据集训练的60.9%的基线模型非常接近。在VSI-Bench数据集上,分别在10%、25%和50%的训练子集下,Map2Thought始终优于最先进的方法,分别提升了5.3%、4.8%和4.0%。
🔬 方法详解
问题定义:现有3D视觉语言模型在进行空间推理时,缺乏明确的空间表示和推理过程,导致模型难以解释其决策依据,并且在复杂场景下的泛化能力受限。模型难以有效利用3D场景中的几何信息和空间关系,从而影响了其对场景的理解和推理能力。
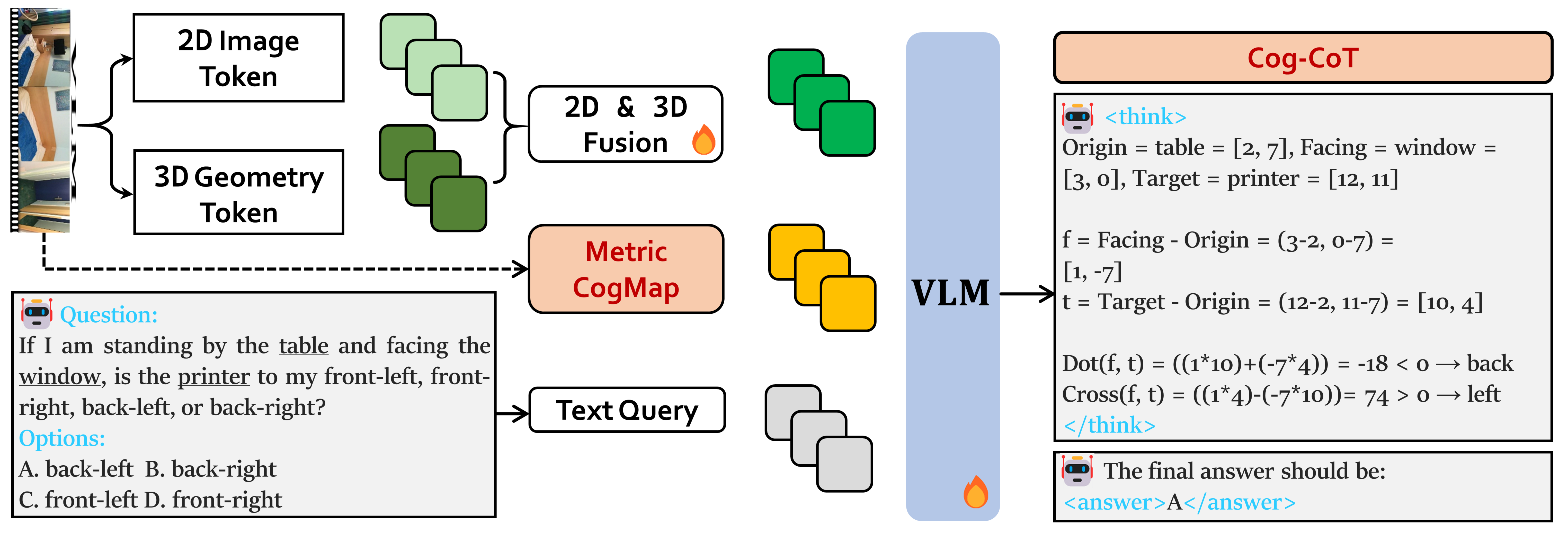
核心思路:Map2Thought的核心思路是构建一个显式的、可解释的3D空间表示,即度量认知地图(Metric-CogMap)。该地图结合了离散网格和连续度量尺度表示,从而能够同时进行关系推理和精确的几何理解。在此基础上,通过认知链式思考(Cog-CoT)进行显式的几何推理,模拟人类的思考过程,从而提高模型的可解释性和推理能力。
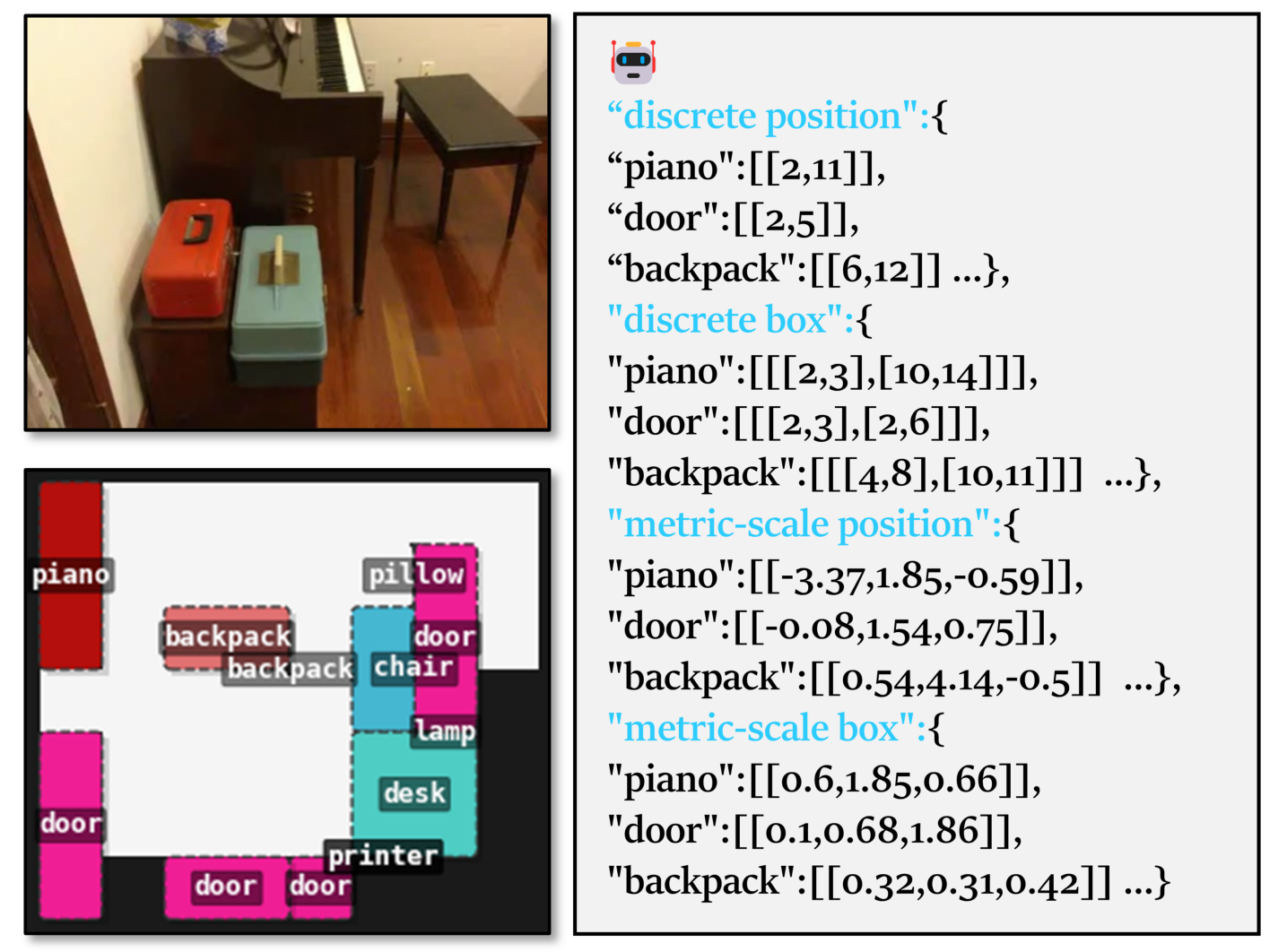
技术框架:Map2Thought框架主要包含两个核心模块:Metric-CogMap和Cog-CoT。首先,Metric-CogMap将3D场景表示为一个混合的离散-连续空间。离散部分使用网格表示,用于关系推理;连续部分使用度量尺度表示,用于精确的几何理解。然后,Cog-CoT模块在Metric-CogMap的基础上,通过一系列确定性的操作进行几何推理,包括向量运算、边界框距离计算和遮挡感知的表观顺序判断。这些操作产生可解释的推理轨迹,从而使模型的决策过程更加透明。
关键创新:Map2Thought的关键创新在于提出了Metric-CogMap,它将离散和连续的空间表示结合起来,从而能够同时进行关系推理和精确的几何理解。此外,Cog-CoT模块通过确定性的操作进行推理,使得模型的决策过程更加可解释。与现有方法相比,Map2Thought能够提供更显式、更可解释的3D空间推理能力。
关键设计:Metric-CogMap的网格大小是一个关键参数,它决定了离散表示的精度。连续表示则使用3D坐标来表示物体的位置和大小。Cog-CoT模块中的操作包括向量运算(例如,计算两个物体之间的方向向量)、边界框距离计算(例如,计算两个物体之间的距离)和遮挡感知的表观顺序判断(例如,判断哪个物体遮挡了另一个物体)。这些操作都是确定性的,并且可以产生可解释的推理轨迹。损失函数的设计未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Map2Thought在VSI-Bench数据集上取得了显著的性能提升。在仅使用一半的监督数据的情况下,Map2Thought达到了59.9%的准确率,与使用完整数据集训练的基线模型(60.9%)非常接近。在10%、25%和50%的训练子集下,Map2Thought分别优于最先进的方法5.3%、4.8%和4.0%。这些结果表明,Map2Thought具有很强的泛化能力和数据效率。
🎯 应用场景
Map2Thought框架具有广泛的应用前景,例如机器人导航、场景理解、虚拟现实和增强现实等领域。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在场景理解方面,Map2Thought可以提供更详细、更可解释的场景描述,从而帮助人们更好地理解场景的内容和结构。此外,该框架还可以应用于虚拟现实和增强现实,从而提供更逼真、更沉浸式的用户体验。
📄 摘要(原文)
We propose Map2Thought, a framework that enables explicit and interpretable spatial reasoning for 3D VLMs. The framework is grounded in two key components: Metric Cognitive Map (Metric-CogMap) and Cognitive Chain-of-Thought (Cog-CoT). Metric-CogMap provides a unified spatial representation by integrating a discrete grid for relational reasoning with a continuous, metric-scale representation for precise geometric understanding. Building upon the Metric-CogMap, Cog-CoT performs explicit geometric reasoning through deterministic operations, including vector operations, bounding-box distances, and occlusion-aware appearance order cues, producing interpretable inference traces grounded in 3D structure. Experimental results show that Map2Thought enables explainable 3D understanding, achieving 59.9% accuracy using only half the supervision, closely matching the 60.9% baseline trained with the full dataset. It consistently outperforms state-of-the-art methods by 5.3%, 4.8%, and 4.0% under 10%, 25%, and 50% training subsets, respectively, on the VSI-Bench.