Think-Clip-Sample: Slow-Fast Frame Selection for Video Understanding
作者: Wenhui Tan, Ruihua Song, Jiaze Li, Jianzhong Ju, Zhenbo Luo
分类: cs.CV, cs.AI
发布日期: 2026-01-16
备注: Accepted by ICASSP2026
💡 一句话要点
提出Think-Clip-Sample以解决长视频理解中的帧选择问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态大型语言模型 帧选择 视频分析 慢快采样
📋 核心要点
- 现有的多模态大型语言模型在处理长视频时面临计算限制和帧选择不佳的问题,导致性能不足。
- 论文提出的Think-Clip-Sample框架通过多查询推理和剪辑级慢快采样,优化了长视频的理解过程。
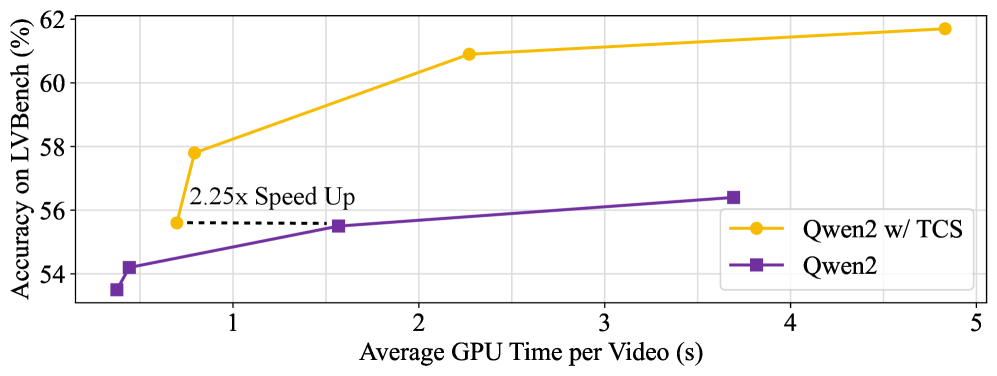
- 实验结果显示,TCS在不同模型上均提升了准确率,最高可达6.9%,且推理时间减少了50%。
📝 摘要(中文)
近年来,多模态大型语言模型(MLLMs)的进展显著推动了视频理解的发展。然而,它们在长视频上的表现仍受到计算限制和帧选择不佳的制约。本文提出了Think-Clip-Sample(TCS),一个无训练框架,通过两个关键组件增强长视频理解:一是多查询推理,生成多个查询以捕捉问题和视频的互补方面;二是剪辑级慢快采样,自适应平衡密集局部细节和稀疏全局上下文。在MLVU、LongVideoBench和VideoMME上的广泛实验表明,TCS在不同的MLLMs上始终提高性能,准确率提升高达6.9%,并且在推理时间成本上减少50%,突显了TCS在长视频理解中的效率和有效性。
🔬 方法详解
问题定义:本文旨在解决长视频理解中的帧选择问题,现有方法在处理长视频时由于计算资源限制和帧选择不当,导致性能下降。
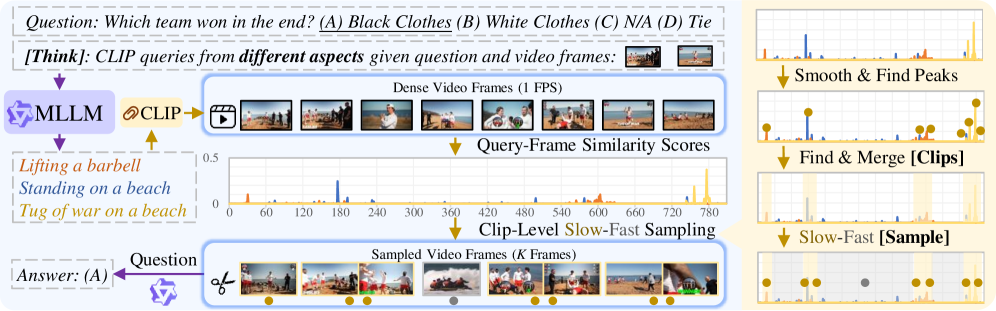
核心思路:提出的Think-Clip-Sample框架通过多查询推理和剪辑级慢快采样,旨在有效捕捉视频中的关键信息,同时平衡局部细节与全局上下文。
技术框架:TCS框架包含两个主要模块:多查询推理模块生成多个查询以捕捉视频和问题的互补信息;剪辑级慢快采样模块则根据视频内容自适应选择关键帧。
关键创新:TCS的核心创新在于其无训练的设计理念,通过多查询推理和慢快采样的结合,显著提升了长视频理解的效率和准确性,与现有方法相比,减少了推理时间并提高了性能。
关键设计:在设计中,TCS采用了自适应的采样策略,确保在保持信息完整性的同时,降低计算负担。具体的参数设置和损失函数设计尚未详细披露,可能为未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TCS在不同的多模态大型语言模型上均实现了性能提升,准确率最高提升6.9%,同时推理时间成本减少50%,展现了其在长视频理解中的优越性。
🎯 应用场景
该研究的潜在应用领域包括视频监控、在线教育、影视内容分析等,能够帮助系统更高效地理解和处理长视频内容。未来,TCS框架可能在多模态学习和视频分析领域产生深远影响,推动相关技术的进步。
📄 摘要(原文)
Recent progress in multi-modal large language models (MLLMs) has significantly advanced video understanding. However, their performance on long-form videos remains limited by computational constraints and suboptimal frame selection. We present Think-Clip-Sample (TCS), a training-free framework that enhances long video understanding through two key components: (i) Multi-Query Reasoning, which generates multiple queries to capture complementary aspects of the question and video; and (ii) Clip-level Slow-Fast Sampling, which adaptively balances dense local details and sparse global context. Extensive experiments on MLVU, LongVideoBench, and VideoMME demonstrate that TCS consistently improves performance across different MLLMs, boosting up to 6.9% accuracy, and is capable of achieving comparable accuracy with 50% fewer inference time cost, highlighting both efficiency and efficacy of TCS on long video understanding.