SAMannot: A Memory-Efficient, Local, Open-source Framework for Interactive Video Instance Segmentation based on SAM2
作者: Gergely Dinya, András Gelencsér, Krisztina Kupán, Clemens Küpper, Kristóf Karacs, Anna Gelencsér-Horváth
分类: cs.CV
发布日期: 2026-01-16
💡 一句话要点
SAMannot:基于SAM2的内存高效、本地化交互式视频实例分割框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频实例分割 人机交互 Segment Anything Model 开源框架 动物行为分析
📋 核心要点
- 现有视频分割研究面临手动标注工作量大、商业平台成本高昂和云服务存在隐私风险等问题。
- SAMannot通过集成SAM2,并优化计算流程,构建本地化、内存高效的人机交互视频分割框架。
- 该框架在动物行为跟踪和标准视频分割数据集上验证,证明其在成本、隐私和效率方面的优势。
📝 摘要(中文)
本文提出SAMannot,一个开源、本地化的框架,将Segment Anything Model 2 (SAM2)集成到人机协作的工作流程中,用于精确的视频分割。为了解决基础模型的高资源需求,该框架修改了SAM2的依赖项,并实现了一个处理层,最大限度地减少计算开销并最大化吞吐量,从而确保高度响应的用户界面。关键特性包括持久的实例身份管理、带有屏障帧的自动“锁定和细化”工作流程,以及基于掩码骨架化的自动提示机制。SAMannot有助于生成研究就绪的YOLO和PNG格式数据集以及结构化的交互日志。通过动物行为跟踪用例以及LVOS和DAVIS基准数据集的子集验证,该工具为复杂的视频注释任务提供了一种可扩展、私有且经济高效的替代方案,优于商业平台。
🔬 方法详解
问题定义:视频实例分割旨在对视频中的每个对象进行像素级别的分割,并保持对象身份的连续性。现有方法要么依赖于耗时的人工标注,要么依赖于昂贵的商业平台,或者存在隐私风险的云服务。这些痛点限制了研究人员在视频分析领域的探索。
核心思路:SAMannot的核心思路是利用预训练的SAM2模型强大的分割能力,结合人机交互的方式,降低人工标注的工作量,同时保证分割精度。通过优化SAM2的计算流程,使其能够在本地高效运行,解决了资源需求高的问题。
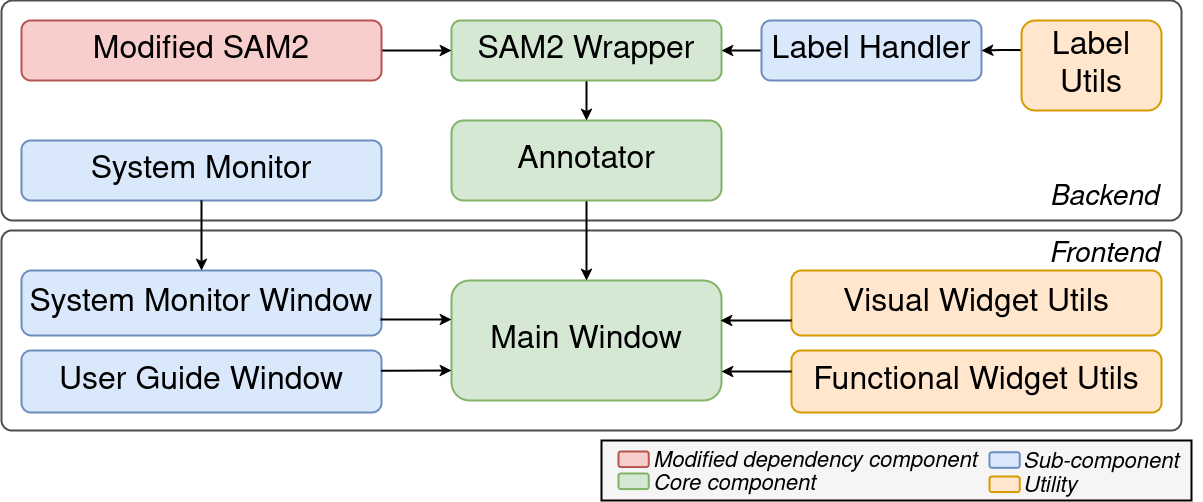
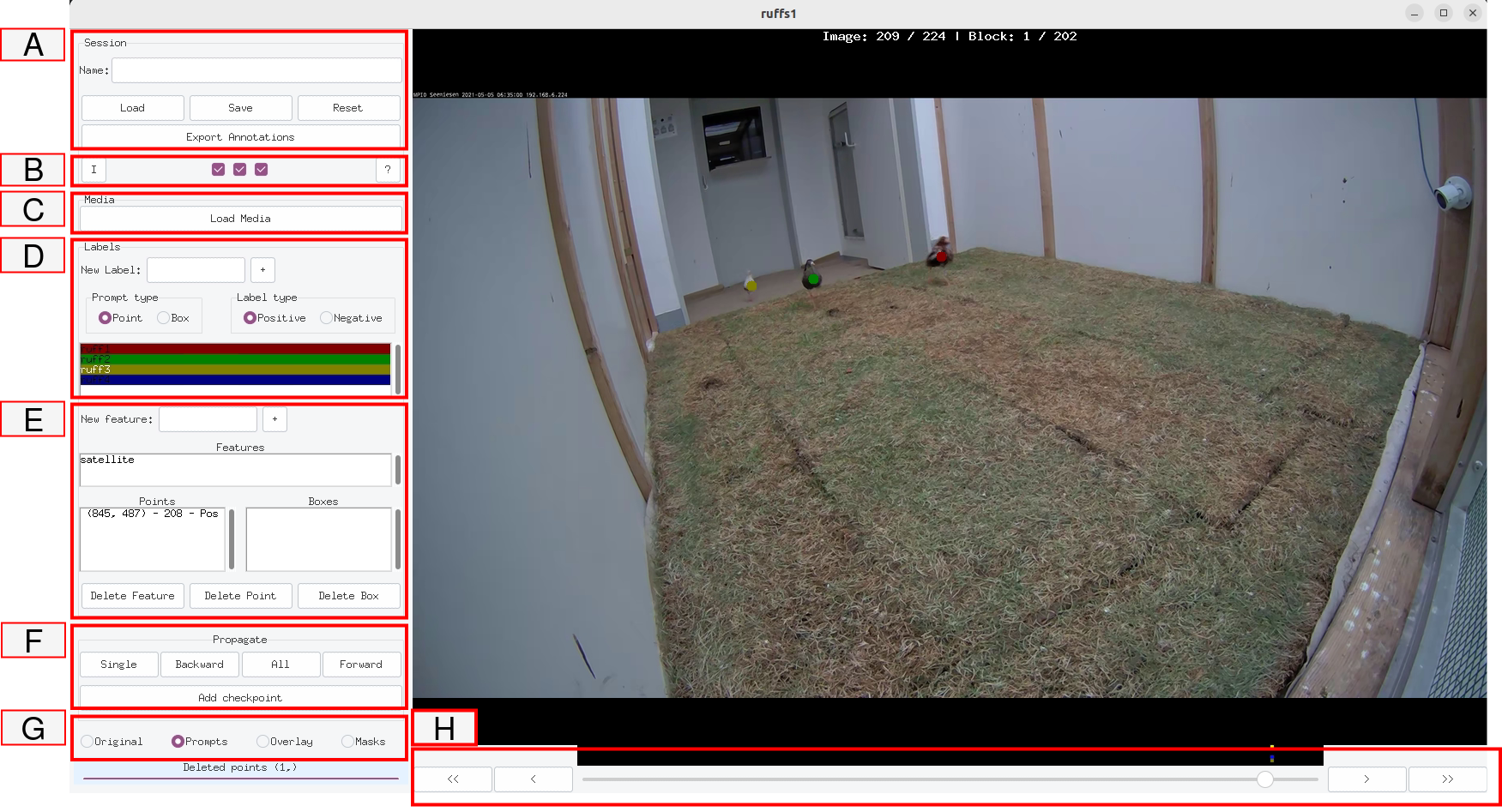
技术框架:SAMannot框架主要包含以下几个模块:1) SAM2集成模块:将SAM2模型集成到框架中,作为分割的基础。2) 计算优化模块:修改SAM2的依赖项,并实现处理层,减少计算开销,提高吞吐量。3) 人机交互界面:提供友好的用户界面,方便用户进行交互式标注。4) 实例身份管理模块:维护视频中每个对象的身份信息,保证分割结果的连续性。5) 自动提示模块:基于掩码骨架化技术,自动生成提示信息,减少人工干预。6) 数据导出模块:支持YOLO和PNG格式的数据导出,方便后续研究使用。
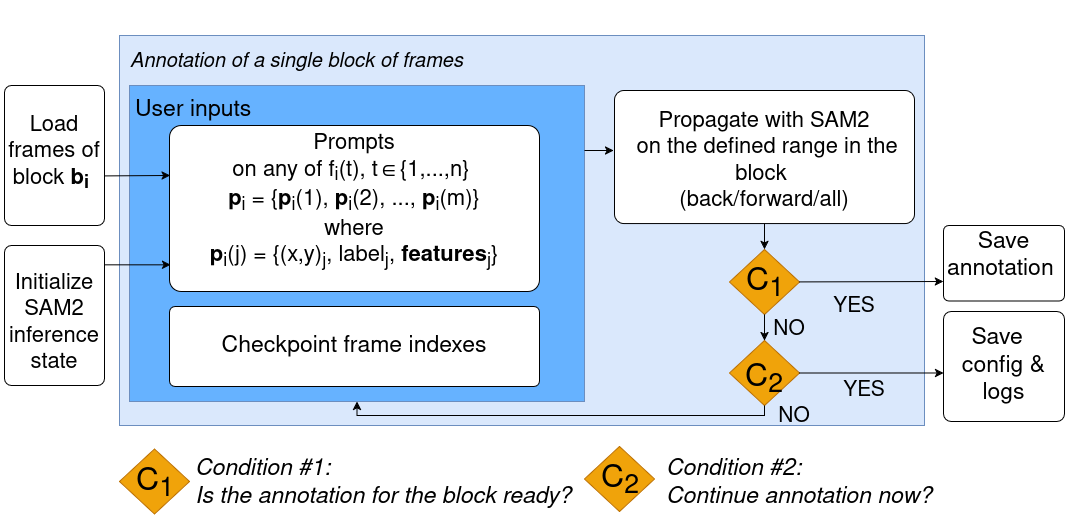
关键创新:SAMannot的关键创新在于:1) 内存高效的SAM2集成:通过优化计算流程,降低了SAM2的资源需求,使其能够在本地高效运行。2) 自动“锁定和细化”工作流程:通过屏障帧,实现自动化的分割和细化,减少人工干预。3) 基于掩码骨架化的自动提示机制:利用掩码的骨架信息,自动生成提示,提高了分割效率。
关键设计:SAMannot的关键设计包括:1) 优化的SAM2依赖项:具体优化细节未知。2) 屏障帧的设置:用于自动“锁定和细化”工作流程,具体设置方法未知。3) 掩码骨架化的具体算法:用于自动提示,具体算法细节未知。
🖼️ 关键图片
📊 实验亮点
论文通过动物行为跟踪用例以及LVOS和DAVIS基准数据集的子集验证了SAMannot的有效性。实验结果表明,SAMannot能够以较低的成本和较高的效率生成高质量的视频分割数据集,为研究人员提供了一种可行的替代方案。
🎯 应用场景
SAMannot可应用于动物行为分析、医学影像分析、自动驾驶等多个领域。它能够帮助研究人员高效地生成高质量的视频分割数据集,加速相关领域的研究进展。该框架的本地化部署和开源特性,也降低了使用门槛,促进了视频分割技术在更广泛范围内的应用。
📄 摘要(原文)
Current research workflows for precise video segmentation are often forced into a compromise between labor-intensive manual curation, costly commercial platforms, and/or privacy-compromising cloud-based services. The demand for high-fidelity video instance segmentation in research is often hindered by the bottleneck of manual annotation and the privacy concerns of cloud-based tools. We present SAMannot, an open-source, local framework that integrates the Segment Anything Model 2 (SAM2) into a human-in-the-loop workflow. To address the high resource requirements of foundation models, we modified the SAM2 dependency and implemented a processing layer that minimizes computational overhead and maximizes throughput, ensuring a highly responsive user interface. Key features include persistent instance identity management, an automated ``lock-and-refine'' workflow with barrier frames, and a mask-skeletonization-based auto-prompting mechanism. SAMannot facilitates the generation of research-ready datasets in YOLO and PNG formats alongside structured interaction logs. Verified through animal behavior tracking use-cases and subsets of the LVOS and DAVIS benchmark datasets, the tool provides a scalable, private, and cost-effective alternative to commercial platforms for complex video annotation tasks.