X-Distill: Cross-Architecture Vision Distillation for Visuomotor Learning
作者: Maanping Shao, Feihong Zhang, Gu Zhang, Baiye Cheng, Zhengrong Xue, Huazhe Xu
分类: cs.CV, cs.AI
发布日期: 2026-01-16
💡 一句话要点
X-Distill:面向机器人视觉运动学习的跨架构视觉知识蒸馏
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 视觉运动学习 知识蒸馏 跨架构学习 数据高效学习
📋 核心要点
- 机器人视觉运动策略依赖大型预训练ViT,但其数据需求在机器人学习中构成挑战,而小型CNN更易优化。
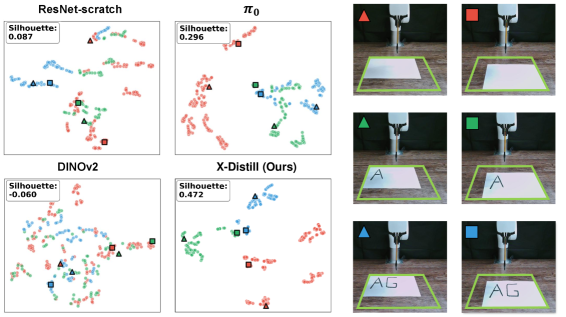
- X-Distill通过离线跨架构知识蒸馏,将大型DINOv2的视觉表征迁移到小型ResNet-18,赋予其强大的视觉先验。
- 实验表明,X-Distill在模拟和真实机器人任务中,性能超越了从头训练的ResNet、微调的DINOv2以及其他先进方法。
📝 摘要(中文)
本文提出了一种名为X-Distill的简单而高效的方法,旨在协同利用不同视觉架构的优势,解决机器人视觉运动学习中数据稀缺的问题。该方法采用离线跨架构知识蒸馏,将大型预训练DINOv2教师模型的丰富视觉表征迁移到紧凑的ResNet-18学生模型上,并在通用ImageNet数据集上进行蒸馏。随后,将具备强大视觉先验的蒸馏编码器与扩散策略头在目标操作任务上进行联合微调。在34个模拟基准测试和5个具有挑战性的真实世界任务中进行的大量实验表明,该方法始终优于配备从头训练的ResNet或微调的DINOv2编码器的策略。值得注意的是,X-Distill也超越了利用特权点云观测的3D编码器或更大的视觉语言模型。该工作强调了一种简单、基础扎实的蒸馏策略在实现数据高效机器人操作方面的有效性。
🔬 方法详解
问题定义:机器人视觉运动学习通常需要大量的训练数据,而实际机器人应用场景往往面临数据稀缺的问题。大型预训练的Vision Transformer (ViT)虽然具有强大的泛化能力,但其数据需求难以满足。另一方面,结构紧凑的CNN虽然更容易优化,但其性能可能不如ViT。因此,如何在数据有限的情况下,充分利用不同架构的优势,提升机器人视觉运动学习的性能是一个关键问题。
核心思路:X-Distill的核心思路是通过知识蒸馏,将大型预训练ViT(DINOv2)的知识迁移到小型CNN(ResNet-18)上。这样,ResNet-18就可以获得ViT的强大视觉表征能力,同时保持其结构紧凑、易于优化的优点。通过这种方式,可以在数据有限的情况下,提升机器人视觉运动学习的性能。
技术框架:X-Distill的技术框架主要包含两个阶段:离线知识蒸馏阶段和在线策略学习阶段。在离线知识蒸馏阶段,使用大型预训练的DINOv2作为教师模型,ResNet-18作为学生模型,在ImageNet数据集上进行知识蒸馏。在在线策略学习阶段,将蒸馏后的ResNet-18编码器与扩散策略头进行联合微调,以适应特定的机器人操作任务。
关键创新:X-Distill的关键创新在于其跨架构的知识蒸馏方法。与传统的知识蒸馏方法不同,X-Distill将知识从ViT迁移到CNN,充分利用了两种架构的优势。此外,X-Distill还采用了离线蒸馏和在线微调相结合的策略,进一步提升了性能。
关键设计:在离线知识蒸馏阶段,使用DINOv2的视觉特征作为教师信号,ResNet-18学习模仿这些特征。损失函数包括特征匹配损失和分类损失。在线策略学习阶段,将蒸馏后的ResNet-18与扩散策略头进行联合微调,使用强化学习算法优化策略。具体的参数设置和网络结构根据不同的任务进行调整。
🖼️ 关键图片

📊 实验亮点
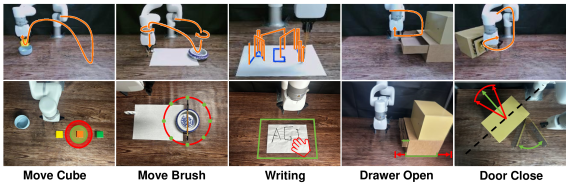
X-Distill在34个模拟基准测试和5个真实世界任务中均取得了显著的性能提升。例如,在真实世界任务中,X-Distill超越了从头训练的ResNet、微调的DINOv2以及利用特权点云观测的3D编码器。此外,X-Distill还超越了更大的视觉语言模型,证明了其在数据高效机器人操作方面的有效性。
🎯 应用场景
X-Distill在机器人操作、自动驾驶、智能制造等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更精确、更高效的操作。此外,X-Distill还可以应用于数据增强、模型压缩等领域,提升模型的性能和效率。未来,X-Distill有望成为机器人视觉运动学习领域的重要技术。
📄 摘要(原文)
Visuomotor policies often leverage large pre-trained Vision Transformers (ViTs) for their powerful generalization capabilities. However, their significant data requirements present a major challenge in the data-scarce context of most robotic learning settings, where compact CNNs with strong inductive biases can be more easily optimized. To address this trade-off, we introduce X-Distill, a simple yet highly effective method that synergizes the strengths of both architectures. Our approach involves an offline, cross-architecture knowledge distillation, transferring the rich visual representations of a large, frozen DINOv2 teacher to a compact ResNet-18 student on the general-purpose ImageNet dataset. This distilled encoder, now endowed with powerful visual priors, is then jointly fine-tuned with a diffusion policy head on the target manipulation tasks. Extensive experiments on $34$ simulated benchmarks and $5$ challenging real-world tasks demonstrate that our method consistently outperforms policies equipped with from-scratch ResNet or fine-tuned DINOv2 encoders. Notably, X-Distill also surpasses 3D encoders that utilize privileged point cloud observations or much larger Vision-Language Models. Our work highlights the efficacy of a simple, well-founded distillation strategy for achieving state-of-the-art performance in data-efficient robotic manipulation.