SoLA-Vision: Fine-grained Layer-wise Linear Softmax Hybrid Attention
作者: Ruibang Li, Guan Luo, Yiwei Zhang, Jin Gao, Bing Li, Weiming Hu
分类: cs.CV
发布日期: 2026-01-16
备注: Preprint
💡 一句话要点
提出SoLA-Vision,一种细粒度层级线性-Softmax混合注意力视觉模型,提升高分辨率图像处理的效率与精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉Transformer 自注意力机制 线性注意力 Softmax注意力 混合注意力 高分辨率图像处理 图像分类
📋 核心要点
- 传统Softmax注意力计算复杂度高,难以应用于高分辨率图像,而线性注意力虽降低了复杂度,但可能损失建模能力。
- SoLA-Vision通过细粒度的层级混合策略,灵活地结合线性和Softmax注意力,在精度和效率之间取得平衡。
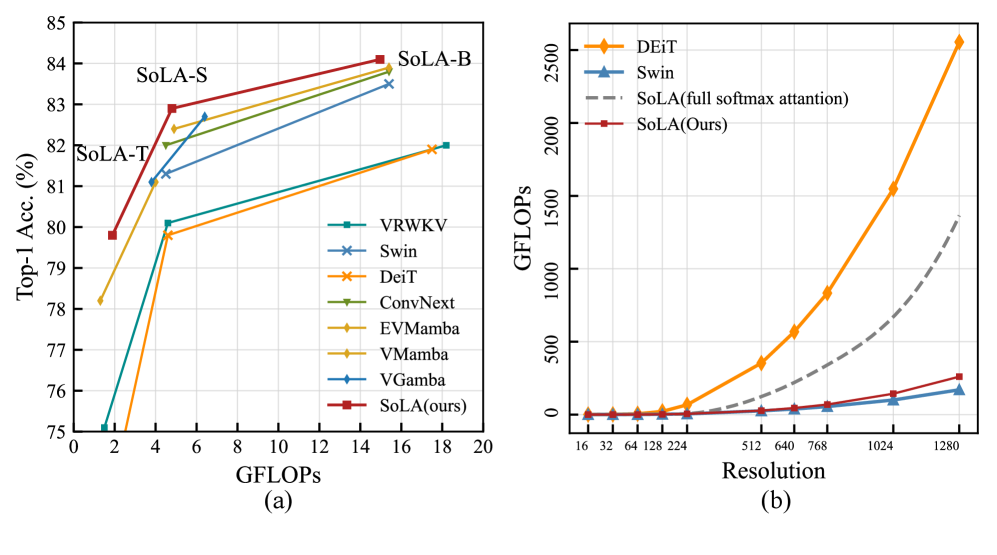
- 实验表明,SoLA-Vision在ImageNet-1K和密集预测任务上均优于纯线性及其他混合注意力模型,实现了性能提升。
📝 摘要(中文)
标准Softmax自注意力在视觉任务中表现出色,但其二次复杂度O(N^2)限制了其在高分辨率场景中的应用。线性注意力将复杂度降低到O(N),但其压缩的状态表示可能会损害建模能力和准确性。本文从层堆叠的角度对线性注意力和Softmax注意力在视觉表示学习中的差异进行了分析研究。进一步地,本文对线性注意力和Softmax注意力的层级混合模式进行了系统实验。结果表明,与刚性的块内混合设计相比,细粒度的层级混合可以在需要更少Softmax层的情况下匹配或超过性能。基于这些发现,本文提出SoLA-Vision(Softmax-Linear Attention Vision),一种灵活的层级混合注意力骨干网络,可以对线性和Softmax注意力的集成方式进行细粒度控制。通过策略性地插入少量全局Softmax层,SoLA-Vision在准确性和计算成本之间实现了强大的权衡。在ImageNet-1K上,SoLA-Vision优于纯线性和其他混合注意力模型。在密集预测任务中,它始终以相当大的优势超越了强大的基线。代码即将发布。
🔬 方法详解
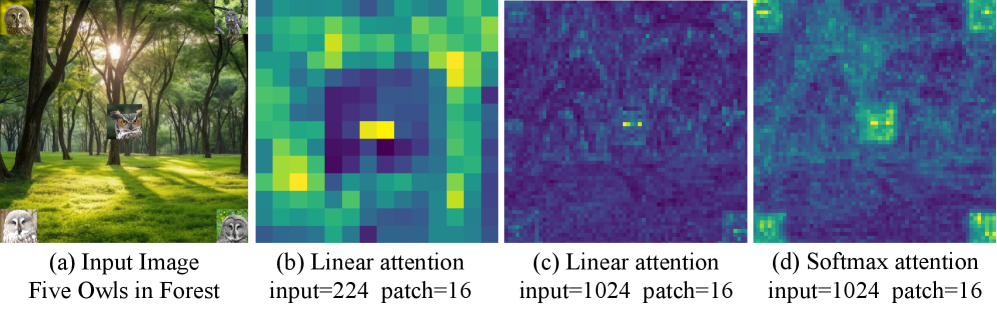
问题定义:现有视觉Transformer模型中的自注意力机制,特别是Softmax自注意力,在处理高分辨率图像时面临计算复杂度过高(O(N^2))的问题,其中N是像素数量。线性注意力虽然降低了计算复杂度(O(N)),但由于其压缩的状态表示,往往会牺牲模型的表达能力和精度。因此,如何在降低计算成本的同时,保持甚至提升模型的性能,是本文要解决的核心问题。
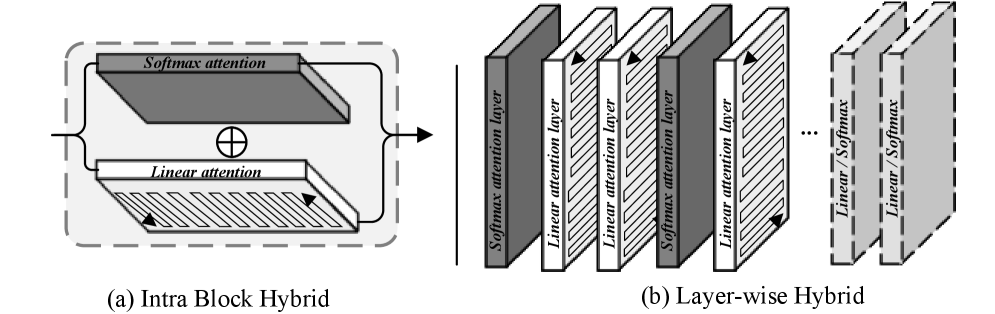
核心思路:本文的核心思路是探索一种细粒度的层级混合注意力机制,即在不同的网络层中灵活地选择使用线性注意力或Softmax注意力。通过分析两种注意力机制在不同层级的特性,并进行实验验证,找到最佳的混合模式,从而在计算成本和模型性能之间取得平衡。这种混合策略允许模型在需要全局信息交互的层使用Softmax注意力,而在对局部特征进行精细建模的层使用线性注意力,从而实现更高效的视觉表示学习。
技术框架:SoLA-Vision的整体架构是一个分层的Transformer结构,其中每个层可以选择使用线性注意力或Softmax注意力。具体来说,模型首先通过一个初始的卷积层或线性层进行特征提取,然后将提取的特征输入到一系列的Transformer层中。在每个Transformer层中,模型根据预先设定的混合策略,选择使用线性注意力或Softmax注意力进行特征交互。最后,模型通过一个输出层进行分类或回归预测。整个框架的关键在于如何设计和优化层级的混合策略,以实现最佳的性能和效率。
关键创新:SoLA-Vision的关键创新在于其细粒度的层级混合注意力机制。与以往的混合注意力方法不同,SoLA-Vision允许在不同的网络层中独立地选择使用线性注意力或Softmax注意力,而不是在同一个块内进行混合。这种细粒度的控制使得模型能够更灵活地适应不同的视觉任务和数据分布,从而实现更好的性能。此外,本文还通过实验验证了层级混合策略的有效性,并提出了一个基于性能和计算成本的混合策略优化方法。
关键设计:SoLA-Vision的关键设计包括以下几个方面:1) 层级混合策略:本文探索了多种层级混合策略,包括均匀混合、随机混合和基于性能的混合。最终,本文选择了一种基于性能的混合策略,即根据每个层级的性能指标(如准确率和损失值),动态地调整线性注意力和Softmax注意力的比例。2) 注意力头的数量:本文实验了不同的注意力头数量,发现适当增加注意力头的数量可以提高模型的性能。3) 损失函数:本文使用标准的交叉熵损失函数进行分类任务的训练,并使用均方误差损失函数进行回归任务的训练。4) 优化器:本文使用AdamW优化器进行模型训练,并设置了合适的学习率和权重衰减系数。
🖼️ 关键图片
📊 实验亮点
SoLA-Vision在ImageNet-1K图像分类任务上,超越了纯线性注意力模型和其他混合注意力模型,实现了更高的准确率。在密集预测任务中,SoLA-Vision也显著优于现有基线模型,展现了其强大的性能。具体性能数据将在代码发布后提供。
🎯 应用场景
SoLA-Vision具有广泛的应用前景,可应用于图像分类、目标检测、语义分割等多种视觉任务。其高效的计算特性使其特别适用于高分辨率图像处理,例如遥感图像分析、医学图像诊断和自动驾驶等领域。未来,SoLA-Vision有望成为一种通用的视觉骨干网络,推动计算机视觉技术的发展。
📄 摘要(原文)
Standard softmax self-attention excels in vision tasks but incurs quadratic complexity O(N^2), limiting high-resolution deployment. Linear attention reduces the cost to O(N), yet its compressed state representations can impair modeling capacity and accuracy. We present an analytical study that contrasts linear and softmax attention for visual representation learning from a layer-stacking perspective. We further conduct systematic experiments on layer-wise hybridization patterns of linear and softmax attention. Our results show that, compared with rigid intra-block hybrid designs, fine-grained layer-wise hybridization can match or surpass performance while requiring fewer softmax layers. Building on these findings, we propose SoLA-Vision (Softmax-Linear Attention Vision), a flexible layer-wise hybrid attention backbone that enables fine-grained control over how linear and softmax attention are integrated. By strategically inserting a small number of global softmax layers, SoLA-Vision achieves a strong trade-off between accuracy and computational cost. On ImageNet-1K, SoLA-Vision outperforms purely linear and other hybrid attention models. On dense prediction tasks, it consistently surpasses strong baselines by a considerable margin. Code will be released.