PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models
作者: Qiyuan Zhang, Biao Gong, Shuai Tan, Zheng Zhang, Yujun Shen, Xing Zhu, Yuyuan Li, Kelu Yao, Chunhua Shen, Changqing Zou
分类: cs.CV
发布日期: 2026-01-16
💡 一句话要点
提出PhysRVG,通过物理感知强化学习提升视频生成模型中刚体运动的真实性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频生成 强化学习 物理引擎 刚体运动 物理仿真
📋 核心要点
- 现有基于Transformer的视频生成模型在处理刚体运动等物理现象时存在明显不足,忽略了物体刚性这一经典力学概念。
- 论文提出物理感知的强化学习范式PhysRVG,将物理碰撞规则直接融入高维空间,确保物理知识的严格应用,而非作为优化过程中的条件。
- 通过构建新的基准测试PhysRVGBench,并进行大量实验,验证了所提出方法在提升视频生成模型物理真实性方面的有效性。
📝 摘要(中文)
本文针对基于Transformer的视频生成模型在模拟真实视觉效果时忽略物理原理的问题,特别是刚体运动方面的不足,提出了一个物理感知的强化学习范式PhysRVG。该范式直接在高维空间中强制执行物理碰撞规则,确保物理知识被严格应用。进一步,扩展该范式到一个统一的框架,称为Mimicry-Discovery Cycle (MDcycle),允许模型在充分微调的同时,完全保留利用物理反馈的能力。为了验证该方法,作者构建了新的基准测试PhysRVGBench,并通过大量的定性和定量实验评估了其有效性。
🔬 方法详解
问题定义:现有基于Transformer的视频生成模型,虽然在像素级别全局去噪方面表现出色,但忽略了物理原理,尤其是在刚体运动的建模上。即使数学上完全正确的物理约束,在模型优化过程中也被视为次优解,限制了生成视频的物理真实性。
核心思路:核心在于将物理规则直接融入到视频生成模型的训练过程中,而不是仅仅依赖于数据驱动的学习。通过强化学习的方式,让模型能够根据物理反馈进行调整,从而生成更符合物理规律的视频。这样设计的目的是为了克服现有方法将物理约束视为优化条件的局限性,确保物理知识被严格应用。
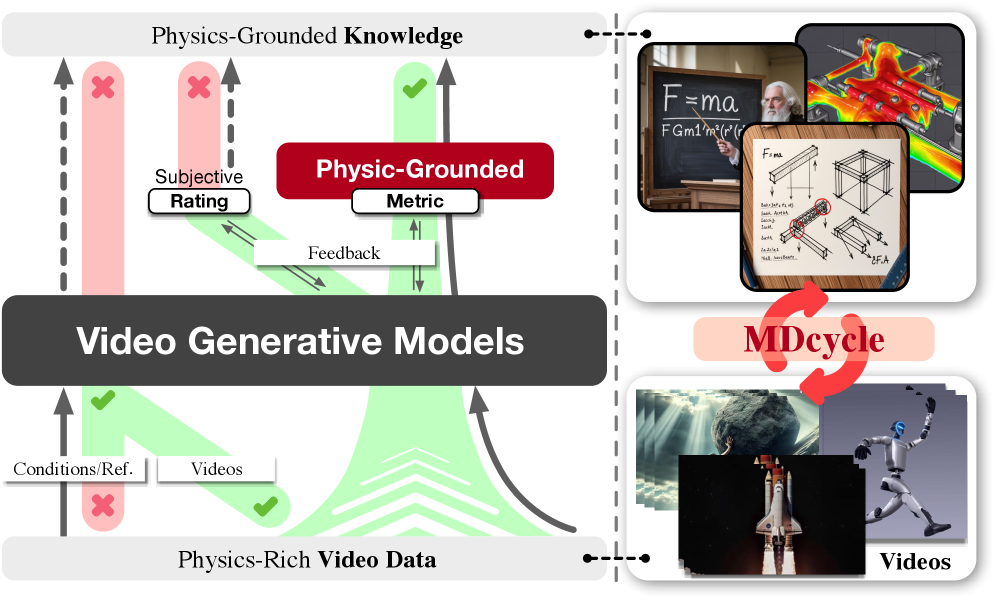
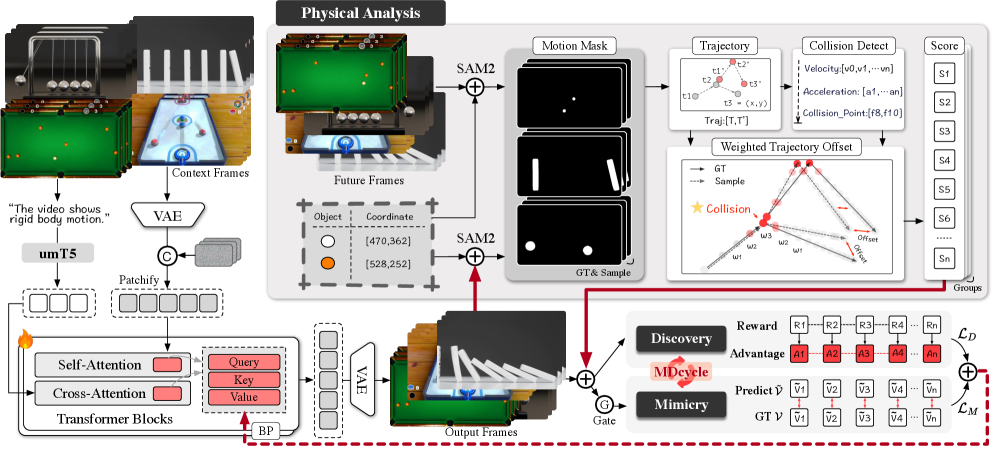
技术框架:论文提出了一个统一的框架,称为Mimicry-Discovery Cycle (MDcycle)。该框架包含两个主要阶段:模仿(Mimicry)和发现(Discovery)。在模仿阶段,模型学习现有视频数据的分布;在发现阶段,模型通过强化学习探索符合物理规则的新的视频生成方式。PhysRVG作为强化学习模块,负责根据物理引擎的反馈信号调整生成策略。
关键创新:最重要的创新点在于将物理引擎与强化学习相结合,直接在高维像素空间中对视频生成模型进行物理约束。这与传统方法将物理规则作为后处理或约束条件的方式有本质区别。通过这种方式,模型能够真正理解并利用物理知识,从而生成更真实的视频。
关键设计:PhysRVG使用强化学习算法(具体算法未知)来训练视频生成模型。奖励函数的设计至关重要,需要能够准确反映视频的物理真实性。例如,可以根据物体碰撞后的速度、角度等物理量来设计奖励函数。此外,MDcycle框架中的模仿和发现阶段需要进行合理的平衡,以避免模型过度拟合现有数据或过度探索不符合实际的物理规则。具体的网络结构和参数设置在论文中可能有所描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
论文构建了新的基准测试PhysRVGBench,用于评估视频生成模型在物理真实性方面的表现。通过实验证明,所提出的PhysRVG方法在PhysRVGBench上取得了显著的提升,能够生成更符合物理规律的视频。具体的性能数据和提升幅度在论文中应该有详细的描述,但此处未知。
🎯 应用场景
该研究成果可应用于游戏开发、电影特效、机器人仿真等领域。通过生成更真实的物理交互视频,可以提升游戏和电影的沉浸感,并为机器人提供更可靠的训练数据。此外,该方法还可以用于虚拟现实和增强现实等领域,创造更逼真的虚拟环境。
📄 摘要(原文)
Physical principles are fundamental to realistic visual simulation, but remain a significant oversight in transformer-based video generation. This gap highlights a critical limitation in rendering rigid body motion, a core tenet of classical mechanics. While computer graphics and physics-based simulators can easily model such collisions using Newton formulas, modern pretrain-finetune paradigms discard the concept of object rigidity during pixel-level global denoising. Even perfectly correct mathematical constraints are treated as suboptimal solutions (i.e., conditions) during model optimization in post-training, fundamentally limiting the physical realism of generated videos. Motivated by these considerations, we introduce, for the first time, a physics-aware reinforcement learning paradigm for video generation models that enforces physical collision rules directly in high-dimensional spaces, ensuring the physics knowledge is strictly applied rather than treated as conditions. Subsequently, we extend this paradigm to a unified framework, termed Mimicry-Discovery Cycle (MDcycle), which allows substantial fine-tuning while fully preserving the model's ability to leverage physics-grounded feedback. To validate our approach, we construct new benchmark PhysRVGBench and perform extensive qualitative and quantitative experiments to thoroughly assess its effectiveness.