MMedExpert-R1: Strengthening Multimodal Medical Reasoning via Domain-Specific Adaptation and Clinical Guideline Reinforcement
作者: Meidan Ding, Jipeng Zhang, Wenxuan Wang, Haiqin Zhong, Xiaoling Luo, Wenting Chen, Linlin Shen
分类: cs.CV
发布日期: 2026-01-16
💡 一句话要点
MMedExpert-R1:通过领域自适应和临床指南强化提升多模态医学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学视觉-语言模型 多模态推理 领域自适应 临床指南强化 强化学习
📋 核心要点
- 现有医学视觉-语言模型在复杂临床推理方面存在不足,缺乏足够的深度推理数据和多专科对齐能力。
- 提出MMedExpert-R1,通过领域特定自适应和临床指南强化,提升模型在多模态医学推理方面的性能。
- 实验结果表明,MMedExpert-R1在MedXpert-MM和OmniMedVQA数据集上取得了显著的性能提升,达到SOTA水平。
📝 摘要(中文)
医学视觉-语言模型(MedVLMs)在感知任务上表现出色,但在现实场景中所需的复杂临床推理方面存在困难。虽然强化学习(RL)已被用于增强推理能力,但现有方法面临关键不匹配:深度推理数据的稀缺、多专科对齐的冷启动限制,以及标准RL算法无法建模临床推理的多样性。我们提出了MMedExpert-R1,一种新颖的推理MedVLM,通过领域特定自适应和临床指南强化来解决这些挑战。我们构建了MMedExpert,一个高质量的数据集,包含四个专科的10K样本,具有逐步推理轨迹。我们的领域特定自适应(DSA)创建了专科特定的LoRA模块,以提供多样化的初始化,而基于指南的优势(GBA)显式地建模了不同的临床推理视角,以与现实世界的诊断策略对齐。冲突感知能力集成然后将这些专业专家合并到一个统一的代理中,确保强大的多专科对齐。综合实验证明了最先进的性能,我们的7B模型在MedXpert-MM上实现了27.50,在OmniMedVQA上实现了83.03,为可靠的多模态医学推理系统奠定了坚实的基础。
🔬 方法详解
问题定义:医学视觉-语言模型(MedVLMs)在感知任务上表现良好,但在实际临床场景中进行复杂推理时面临挑战。现有方法缺乏足够的深度推理数据,难以进行多专科对齐,并且标准强化学习算法无法捕捉临床推理的多样性。这些问题限制了MedVLMs在实际医疗应用中的潜力。
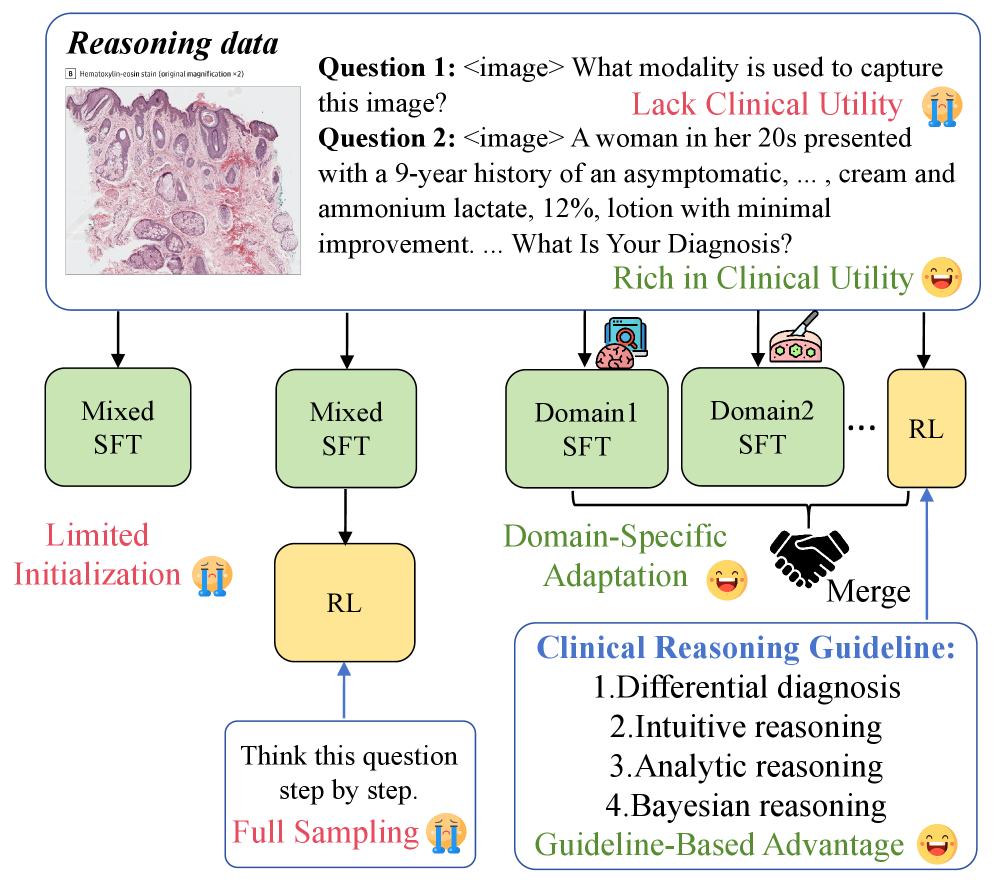
核心思路:MMedExpert-R1的核心思路是通过领域特定自适应和临床指南强化来提升MedVLMs的推理能力。领域特定自适应通过创建专科特定的LoRA模块,为模型提供多样化的初始化,从而解决冷启动问题。临床指南强化则通过显式建模不同的临床推理视角,使模型能够更好地与现实世界的诊断策略对齐。
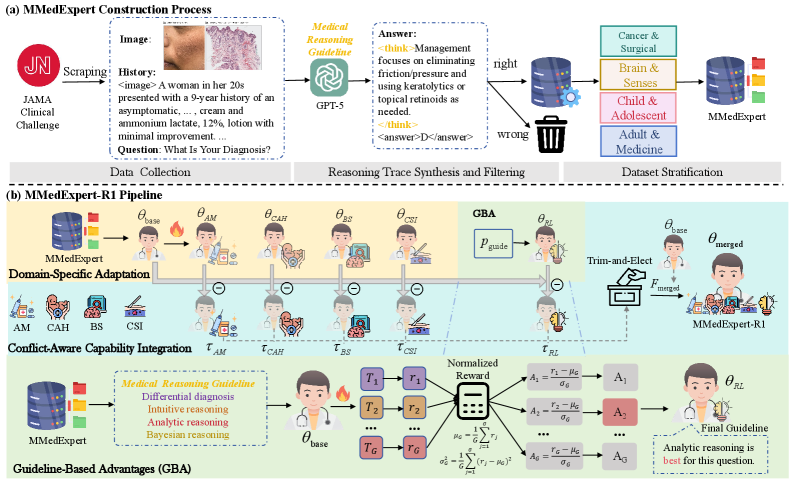
技术框架:MMedExpert-R1的整体框架包含三个主要模块:领域特定自适应(DSA)、基于指南的优势(GBA)和冲突感知能力集成。DSA模块负责创建专科特定的LoRA模块,GBA模块负责建模不同的临床推理视角,冲突感知能力集成模块则负责将这些专业专家合并到一个统一的代理中,确保强大的多专科对齐。
关键创新:MMedExpert-R1的关键创新在于结合了领域特定自适应和临床指南强化,从而解决了现有方法在深度推理数据稀缺、多专科对齐和临床推理多样性建模方面的问题。通过DSA和GBA模块,模型能够更好地适应不同专科的特点,并学习到更加符合实际临床推理策略的知识。
关键设计:MMedExpert-R1的关键设计包括:(1)构建高质量的MMedExpert数据集,包含四个专科的10K样本,具有逐步推理轨迹;(2)使用LoRA模块进行领域特定自适应,降低训练成本;(3)设计基于指南的优势函数,显式建模不同的临床推理视角;(4)采用冲突感知能力集成方法,将不同专科的专家模型合并到一个统一的代理中。
🖼️ 关键图片
📊 实验亮点
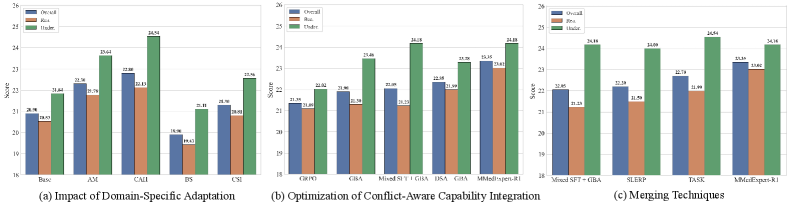
MMedExpert-R1在MedXpert-MM数据集上取得了27.50的成绩,在OmniMedVQA数据集上取得了83.03的成绩,均达到了SOTA水平。这些结果表明,该方法能够显著提升MedVLMs在多模态医学推理方面的性能,为构建可靠的智能医疗系统奠定了坚实的基础。
🎯 应用场景
MMedExpert-R1具有广泛的应用前景,可以用于辅助医生进行诊断、制定治疗方案、提供医学教育等。该研究成果有助于提高医疗服务的质量和效率,并为未来的智能医疗系统奠定基础。此外,该方法也可以推广到其他需要复杂推理的领域,例如金融、法律等。
📄 摘要(原文)
Medical Vision-Language Models (MedVLMs) excel at perception tasks but struggle with complex clinical reasoning required in real-world scenarios. While reinforcement learning (RL) has been explored to enhance reasoning capabilities, existing approaches face critical mismatches: the scarcity of deep reasoning data, cold-start limits multi-specialty alignment, and standard RL algorithms fail to model clinical reasoning diversity. We propose MMedExpert-R1, a novel reasoning MedVLM that addresses these challenges through domain-specific adaptation and clinical guideline reinforcement. We construct MMedExpert, a high-quality dataset of 10K samples across four specialties with step-by-step reasoning traces. Our Domain-Specific Adaptation (DSA) creates specialty-specific LoRA modules to provide diverse initialization, while Guideline-Based Advantages (GBA) explicitly models different clinical reasoning perspectives to align with real-world diagnostic strategies. Conflict-Aware Capability Integration then merges these specialized experts into a unified agent, ensuring robust multi-specialty alignment. Comprehensive experiments demonstrate state-of-the-art performance, with our 7B model achieving 27.50 on MedXpert-MM and 83.03 on OmniMedVQA, establishing a robust foundation for reliable multimodal medical reasoning systems.