See Less, Drive Better: Generalizable End-to-End Autonomous Driving via Foundation Models Stochastic Patch Selection
作者: Amir Mallak, Erfan Aasi, Shiva Sreeram, Tsun-Hsuan Wang, Daniela Rus, Alaa Maalouf
分类: cs.CV, cs.LG, cs.RO
发布日期: 2026-01-15
💡 一句话要点
提出基于随机patch选择的通用端到端自动驾驶方法,提升泛化性和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 泛化能力 随机Patch选择 基础模型 分布外鲁棒性
📋 核心要点
- 现有端到端自动驾驶方法在分布外场景泛化性差,原因在于基础模型提取的特征存在冗余信息,导致策略过拟合。
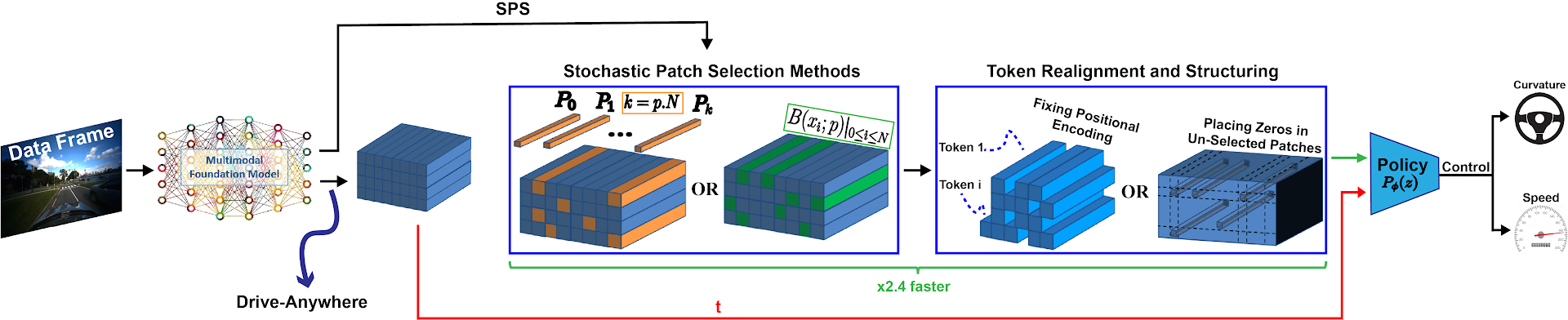
- 论文提出随机Patch选择(SPS)方法,通过随机屏蔽部分patch特征,使策略学习对不同patch组合具有不变性的特征。
- 实验表明,SPS方法在多个分布外场景中显著提升了自动驾驶策略的鲁棒性和泛化性,并成功迁移到真实车辆。
📝 摘要(中文)
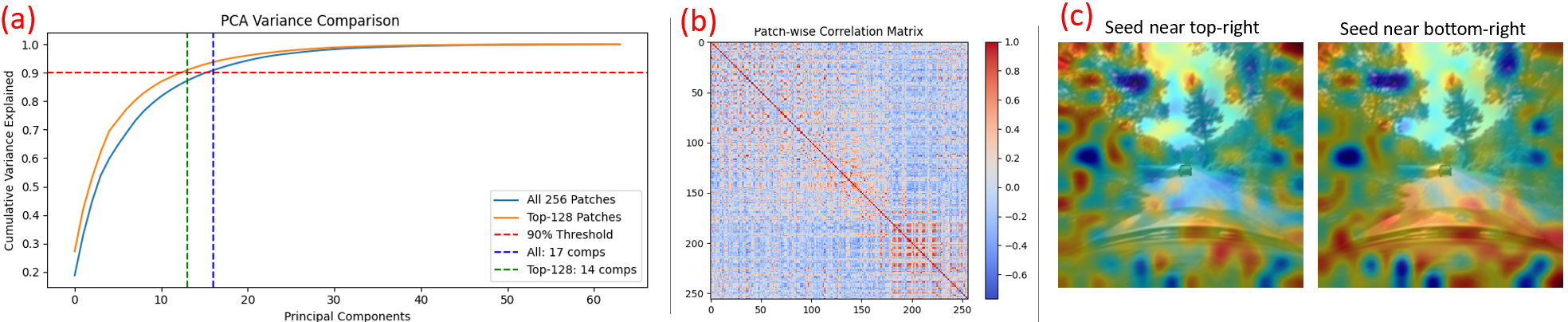
端到端自动驾驶的最新进展表明,在从基础模型中提取的patch对齐特征上训练的策略,能更好地泛化到分布外(OOD)场景。我们假设,由于自注意力机制,每个patch特征隐式地嵌入/包含来自所有其他patch的信息,这些信息以不同的方式和强度表示,从而导致这些描述符高度冗余。我们通过PCA和跨patch相似性来量化这种(BLIP2)特征的冗余性:90%的方差由17/64个主成分捕获,并且普遍存在很强的token间相关性。在这些重叠信息上进行训练会导致策略过度拟合虚假相关性,从而损害OOD鲁棒性。我们提出随机Patch选择(SPS),这是一种简单而有效的方法,用于学习更鲁棒、更通用和更高效的策略。对于每一帧,SPS随机屏蔽一部分patch描述符,不将其馈送到策略模型,同时保留剩余patch的空间布局。因此,策略获得了场景的不同随机但完整的视图:每个随机的patch子集都像世界的一个不同的、但仍然合理的、连贯的投影。因此,策略基于对哪些特定token存活下来是不变的特征做出决策。大量的实验证实,在所有OOD场景中,我们的方法都优于最先进水平(SOTA),在闭环模拟中实现了6.2%的平均改进,高达20.4%,同时速度提高了2.4倍。我们对掩蔽率和patch特征重组进行了消融研究,训练和评估了9个系统,其中8个超过了之前的SOTA。最后,我们表明,相同的学习策略可以转移到真实的物理车辆上,而无需任何调整。
🔬 方法详解
问题定义:现有端到端自动驾驶方法依赖于从预训练基础模型提取的视觉特征。这些特征虽然强大,但由于自注意力机制,不同patch之间存在高度冗余的信息。这种冗余导致策略模型容易过拟合训练数据中的虚假相关性,从而在面对新的、分布外的场景时表现不佳。因此,需要一种方法来降低特征冗余,提高策略模型的泛化能力。
核心思路:论文的核心思路是通过随机屏蔽一部分patch特征,迫使策略模型学习对剩余patch组合具有不变性的特征。这种随机性可以看作是一种数据增强,使模型能够从不同的视角观察同一场景,从而提高其鲁棒性。同时,减少输入特征的数量也有助于提高计算效率。
技术框架:SPS方法可以集成到现有的端到端自动驾驶框架中。其主要流程如下:1) 从图像中提取patch特征(例如使用BLIP2)。2) 对于每一帧图像,随机选择一部分patch特征进行保留,其余进行屏蔽。3) 将保留的patch特征输入到策略模型中,进行驾驶决策。4) 使用标准的强化学习算法(例如PPO)训练策略模型。
关键创新:SPS方法的关键创新在于其简单性和有效性。通过随机屏蔽patch特征,它能够有效地降低特征冗余,提高策略模型的泛化能力,而无需对基础模型或策略模型进行复杂的修改。此外,SPS方法还具有很高的计算效率,因为它减少了输入特征的数量。
关键设计:SPS方法的关键设计包括:1) 掩蔽率:控制随机屏蔽的patch特征的比例。论文通过实验确定了最佳的掩蔽率范围。2) patch特征重组:研究了不同的patch特征组织方式对性能的影响。3) 策略模型:可以使用各种不同的策略模型,例如MLP或Transformer。4) 损失函数:使用标准的强化学习损失函数,例如PPO损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SPS方法在多个分布外场景中显著优于现有最先进方法,平均提升6.2%,在闭环模拟中最高提升20.4%,同时速度提升2.4倍。消融实验表明,不同的掩蔽率和patch特征重组方式都会影响性能,但大多数配置都能超过现有SOTA。更重要的是,该方法训练的策略可以直接迁移到真实车辆上,无需任何额外的微调,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,尤其是在复杂、多变的环境中,例如城市道路、恶劣天气等。通过提高自动驾驶系统的泛化能力,可以减少对大量特定场景数据的依赖,降低开发和维护成本。此外,该方法还可以应用于其他机器人领域,例如无人机、移动机器人等,提高其在未知环境中的适应能力。
📄 摘要(原文)
Recent advances in end-to-end autonomous driving show that policies trained on patch-aligned features extracted from foundation models generalize better to Out-of-Distribution (OOD). We hypothesize that due to the self-attention mechanism, each patch feature implicitly embeds/contains information from all other patches, represented in a different way and intensity, making these descriptors highly redundant. We quantify redundancy in such (BLIP2) features via PCA and cross-patch similarity: $90$% of variance is captured by $17/64$ principal components, and strong inter-token correlations are pervasive. Training on such overlapping information leads the policy to overfit spurious correlations, hurting OOD robustness. We present Stochastic-Patch-Selection (SPS), a simple yet effective approach for learning policies that are more robust, generalizable, and efficient. For every frame, SPS randomly masks a fraction of patch descriptors, not feeding them to the policy model, while preserving the spatial layout of the remaining patches. Thus, the policy is provided with different stochastic but complete views of the (same) scene: every random subset of patches acts like a different, yet still sensible, coherent projection of the world. The policy thus bases its decisions on features that are invariant to which specific tokens survive. Extensive experiments confirm that across all OOD scenarios, our method outperforms the state of the art (SOTA), achieving a $6.2$% average improvement and up to $20.4$% in closed-loop simulations, while being $2.4\times$ faster. We conduct ablations over masking rates and patch-feature reorganization, training and evaluating 9 systems, with 8 of them surpassing prior SOTA. Finally, we show that the same learned policy transfers to a physical, real-world car without any tuning.