CoMoVi: Co-Generation of 3D Human Motions and Realistic Videos
作者: Chengfeng Zhao, Jiazhi Shu, Yubo Zhao, Tianyu Huang, Jiahao Lu, Zekai Gu, Chengwei Ren, Zhiyang Dou, Qing Shuai, Yuan Liu
分类: cs.CV
发布日期: 2026-01-15
备注: Project Page: https://igl-hkust.github.io/CoMoVi/
💡 一句话要点
CoMoVi:提出协同生成框架,同步生成3D人体动作和逼真视频
关键词: 3D人体动作生成 视频生成 扩散模型 协同生成 交叉注意力 人体运动表示 视频扩散模型
📋 核心要点
- 现有方法难以有效利用3D人体动作和2D视频之间的内在联系,导致生成结果缺乏一致性和真实感。
- CoMoVi通过耦合两个视频扩散模型,在单个扩散去噪循环中同步生成3D人体动作和视频,实现相互促进。
- 实验结果表明,CoMoVi在3D人体运动和视频生成任务上均表现出色,验证了该方法的有效性。
📝 摘要(中文)
本文发现3D人体动作和2D人体视频的生成本质上是相互耦合的。3D动作提供了视频中合理性和一致性的结构先验,而预训练的视频模型为动作提供了强大的泛化能力,这使得耦合它们的生成过程成为必要。基于此,我们提出了CoMoVi,一个协同生成框架,它耦合了两个视频扩散模型(VDM),以在单个扩散去噪循环中同步生成3D人体动作和视频。为了实现这一点,我们首先提出了一种有效的2D人体运动表示,它可以继承预训练VDM的强大先验。然后,我们设计了一个双分支扩散模型,通过相互特征交互和3D-2D交叉注意力来耦合人体运动和视频生成过程。此外,我们整理了CoMoVi数据集,这是一个大规模的真实世界人体视频数据集,带有文本和运动注释,涵盖了多样且具有挑战性的人体运动。大量的实验证明了我们的方法在3D人体运动和视频生成任务中的有效性。
🔬 方法详解
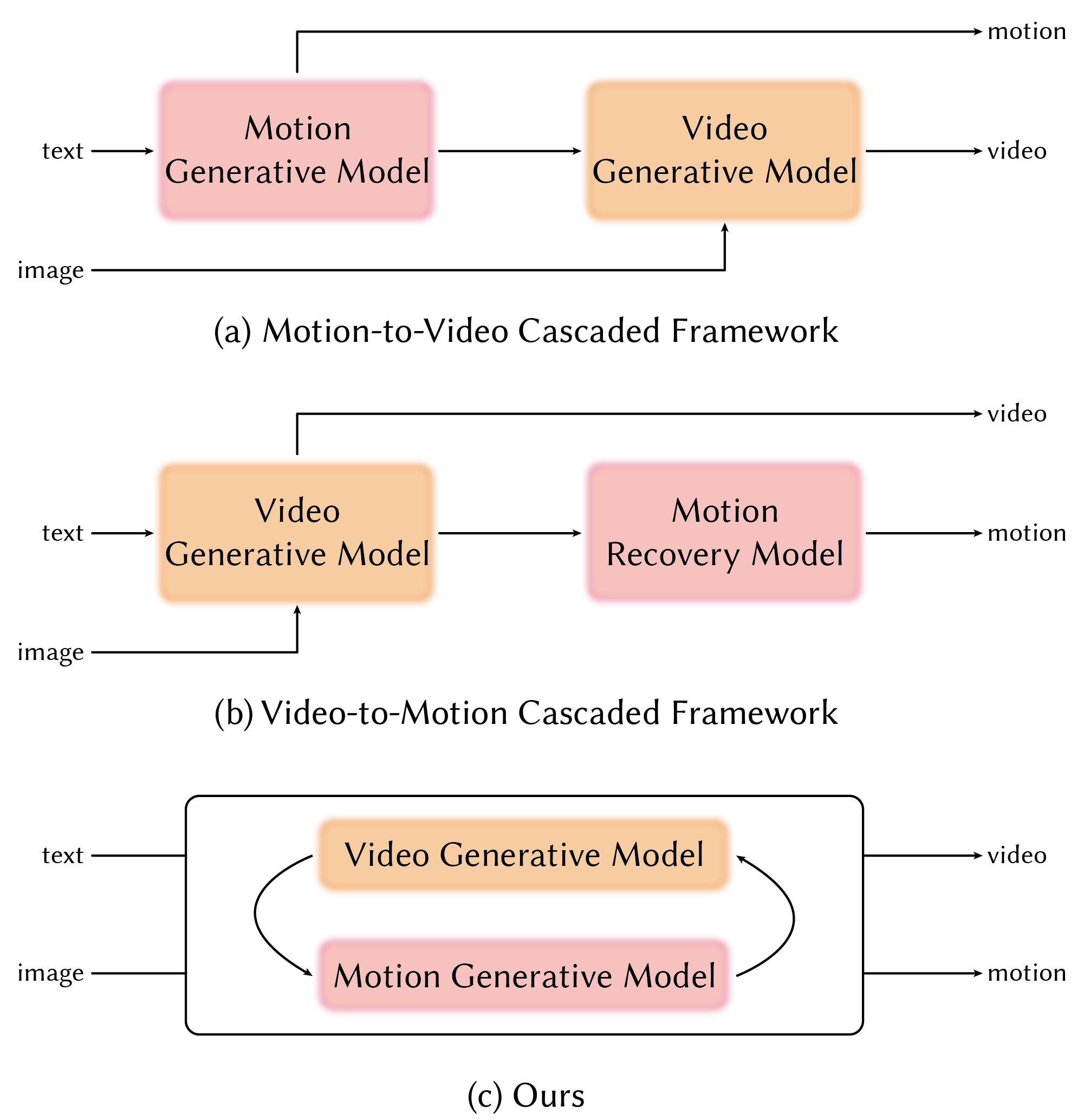
问题定义:现有方法在生成3D人体动作和逼真视频时,通常将两者视为独立的任务,忽略了它们之间的内在联系。这种分离导致生成的视频可能与3D动作不一致,或者生成的3D动作缺乏真实感。因此,如何有效地利用3D动作和2D视频之间的耦合关系,生成高质量的3D人体动作和逼真视频是一个关键问题。
核心思路:CoMoVi的核心思路是协同生成3D人体动作和2D视频,通过耦合两个视频扩散模型(VDM),在单个扩散去噪循环中同步生成它们。这种协同生成的方式可以使3D动作提供视频的结构先验,而视频模型则为动作提供强大的泛化能力,从而提高生成结果的质量和一致性。
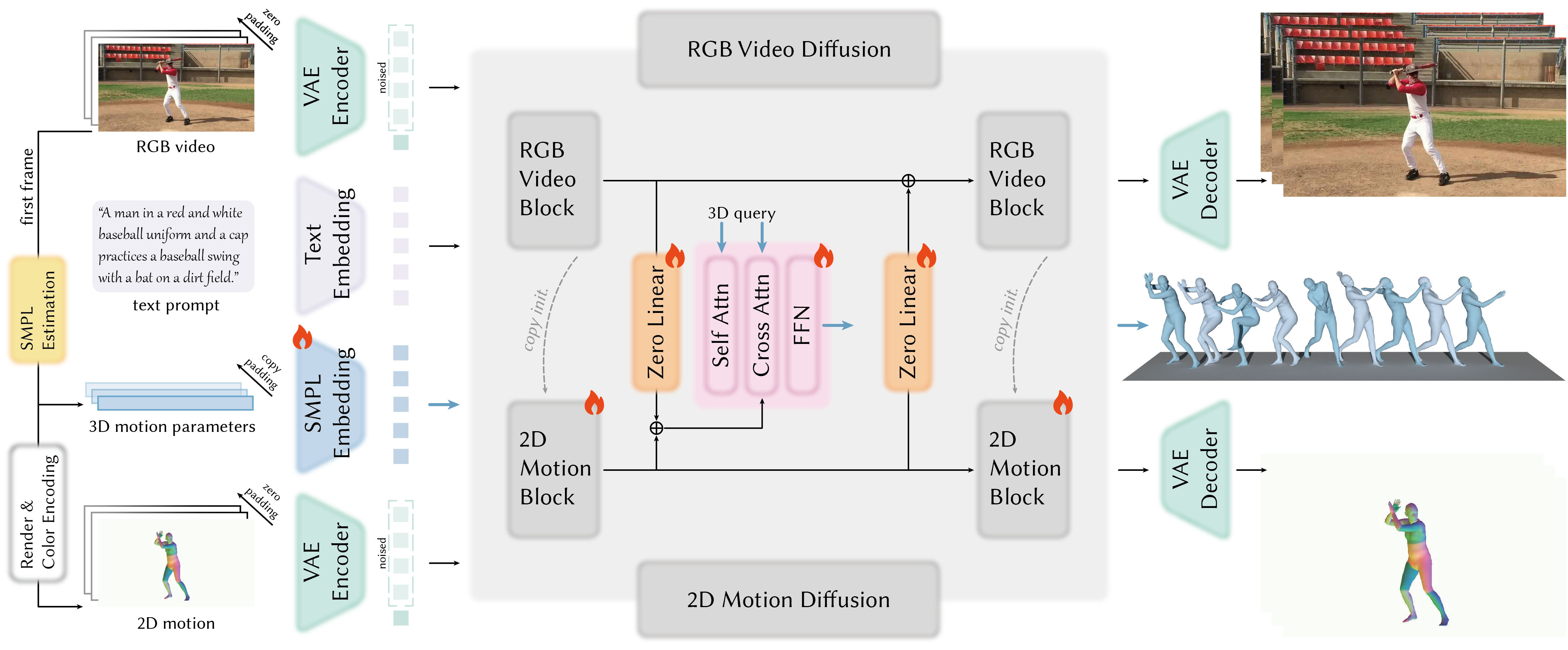
技术框架:CoMoVi采用双分支扩散模型,一个分支负责生成3D人体动作,另一个分支负责生成2D视频。这两个分支通过相互特征交互和3D-2D交叉注意力机制进行耦合。具体来说,3D动作分支将3D运动信息传递给视频分支,以指导视频的生成;而视频分支则将视频信息传递给3D动作分支,以提高动作的真实感。整个框架在一个扩散去噪循环中进行迭代,逐步生成高质量的3D人体动作和逼真视频。
关键创新:CoMoVi的关键创新在于提出了一个协同生成框架,该框架能够有效地耦合3D人体动作和2D视频的生成过程。与现有方法相比,CoMoVi能够更好地利用3D动作和2D视频之间的内在联系,从而生成更逼真、更一致的结果。此外,CoMoVi还提出了一种有效的2D人体运动表示,可以继承预训练VDM的强大先验。
关键设计:CoMoVi的关键设计包括:1) 采用双分支扩散模型,分别负责3D动作和2D视频的生成;2) 使用相互特征交互和3D-2D交叉注意力机制,实现两个分支之间的耦合;3) 提出一种有效的2D人体运动表示,以继承预训练VDM的强大先验;4) 构建大规模真实世界人体视频数据集CoMoVi Dataset,用于训练和评估模型。具体的参数设置、损失函数和网络结构等技术细节在论文中有详细描述,这里不再赘述。
🖼️ 关键图片
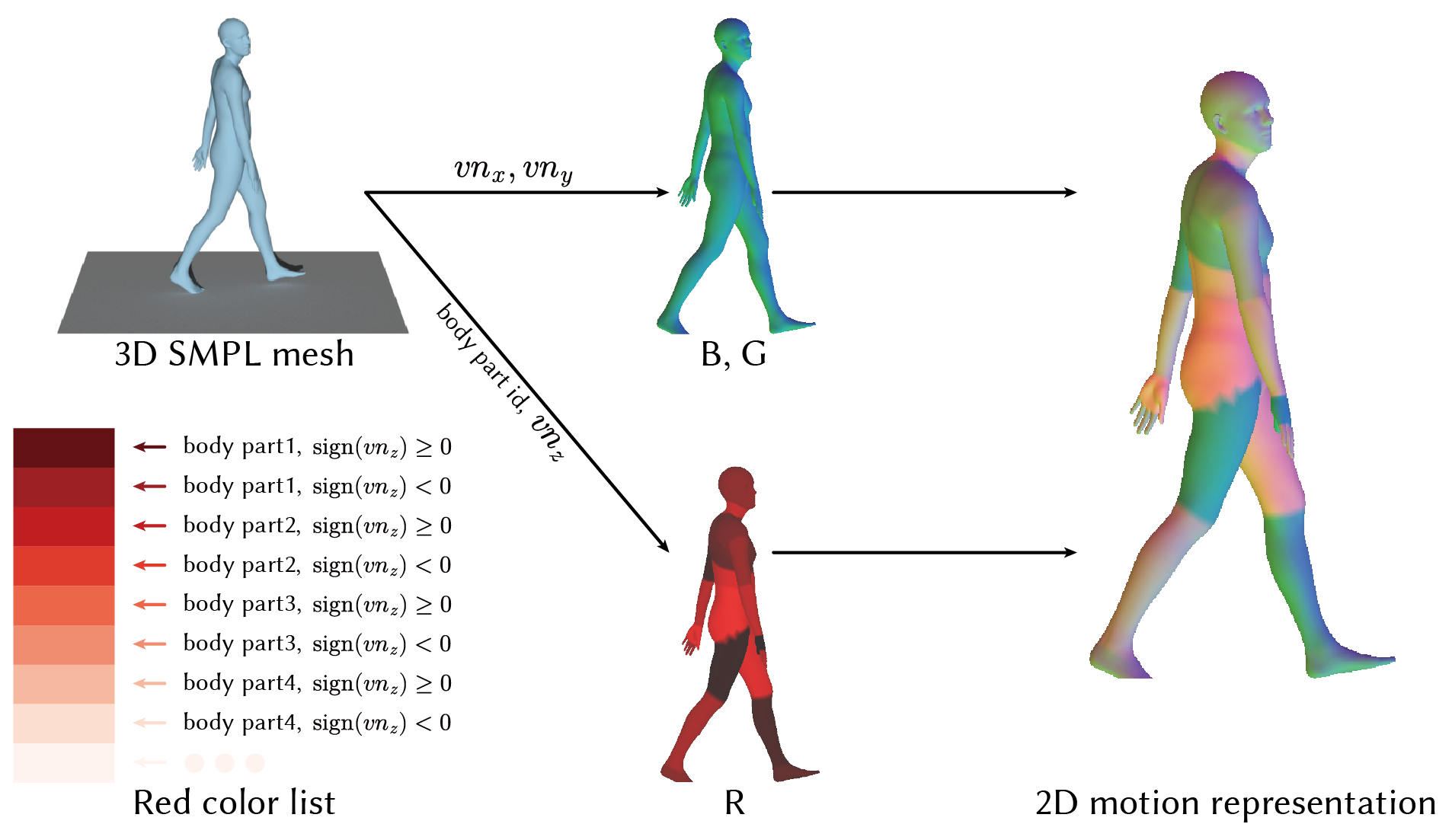
📊 实验亮点
实验结果表明,CoMoVi在3D人体运动和视频生成任务上均取得了显著的性能提升。与现有方法相比,CoMoVi生成的3D人体动作更加真实自然,生成的视频更加逼真流畅。具体的数据指标和对比结果在论文中有详细展示,例如在运动质量和视频真实度方面,CoMoVi均优于其他基线方法。
🎯 应用场景
CoMoVi具有广泛的应用前景,例如虚拟现实、游戏开发、电影制作、体育分析等领域。它可以用于生成逼真的人体动画,创建沉浸式的虚拟体验,以及进行人体运动分析和预测。此外,CoMoVi还可以应用于自动驾驶领域,用于生成逼真的人体行为视频,以训练自动驾驶系统。
📄 摘要(原文)
In this paper, we find that the generation of 3D human motions and 2D human videos is intrinsically coupled. 3D motions provide the structural prior for plausibility and consistency in videos, while pre-trained video models offer strong generalization capabilities for motions, which necessitate coupling their generation processes. Based on this, we present CoMoVi, a co-generative framework that couples two video diffusion models (VDMs) to generate 3D human motions and videos synchronously within a single diffusion denoising loop. To achieve this, we first propose an effective 2D human motion representation that can inherit the powerful prior of pre-trained VDMs. Then, we design a dual-branch diffusion model to couple human motion and video generation process with mutual feature interaction and 3D-2D cross attentions. Moreover, we curate CoMoVi Dataset, a large-scale real-world human video dataset with text and motion annotations, covering diverse and challenging human motions. Extensive experiments demonstrate the effectiveness of our method in both 3D human motion and video generation tasks.