RSATalker: Realistic Socially-Aware Talking Head Generation for Multi-Turn Conversation
作者: Peng Chen, Xiaobao Wei, Yi Yang, Naiming Yao, Hui Chen, Feng Tian
分类: cs.CV
发布日期: 2026-01-15
💡 一句话要点
提出RSATalker,用于支持多轮对话的逼真社交感知说话头生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 说话头生成 3D高斯溅射 社交感知 多轮对话 虚拟现实
📋 核心要点
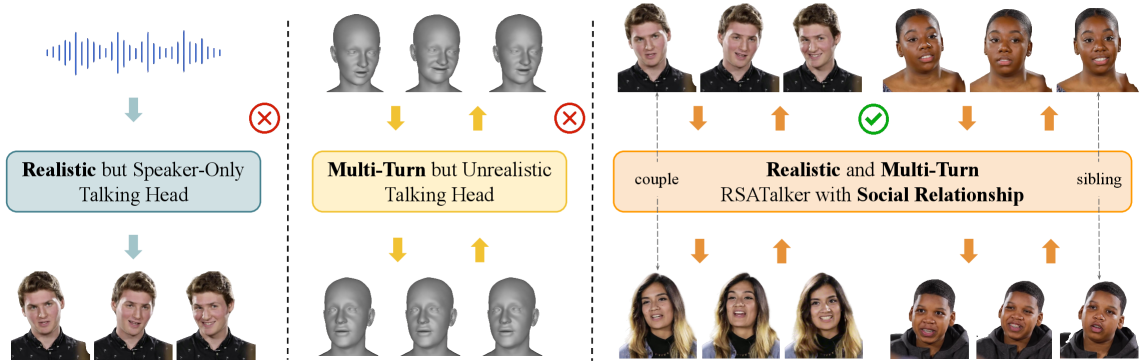
- 现有说话头生成方法在真实感、计算效率和社交感知方面存在不足,难以满足多轮对话场景的需求。
- RSATalker利用3D高斯溅射技术,结合网格驱动的面部运动和社交感知模块,实现逼真且具有社交意识的说话头生成。
- 实验结果表明,RSATalker在真实感和社交感知方面均优于现有技术,为多轮对话场景下的虚拟交互提供了新的解决方案。
📝 摘要(中文)
说话头生成在虚拟现实(VR)中变得越来越重要,尤其是在涉及多轮对话的社交场景中。现有方法面临显著的局限性:基于网格的3D方法可以对双人对话进行建模,但缺乏逼真的纹理;而基于大型模型的2D方法可以产生自然的外观,但计算成本过高。最近,基于3D高斯溅射(3DGS)的方法实现了高效和逼真的渲染,但仍然仅限于单人说话,忽略了社会关系。我们介绍了RSATalker,这是第一个利用3DGS进行逼真和社交感知说话头生成的框架,支持多轮对话。我们的方法首先从语音驱动基于网格的3D面部运动,然后将3D高斯绑定到网格面片以渲染高保真2D头像视频。为了捕捉人际动态,我们提出了一个社交感知模块,该模块通过可学习的查询机制将包括血缘和非血缘以及平等和不平等在内的社会关系编码为高级嵌入。我们设计了一个三阶段训练范式,并构建了带有语音-网格-图像三元组并标注了社会关系的RSATalker数据集。大量的实验表明,RSATalker在真实感和社交感知方面都达到了最先进的性能。代码和数据集将会发布。
🔬 方法详解
问题定义:现有说话头生成方法在多轮对话的社交场景中存在局限性。基于网格的3D方法缺乏逼真的纹理,基于大型模型的2D方法计算成本过高,而基于3DGS的方法忽略了社会关系,无法捕捉人际互动。
核心思路:RSATalker的核心思路是将3D高斯溅射技术与网格驱动的面部运动相结合,并引入社交感知模块,从而实现逼真、高效且具有社交意识的说话头生成。通过3DGS保证渲染效率和真实感,通过网格驱动保证面部运动的精确控制,通过社交感知模块捕捉人际互动。
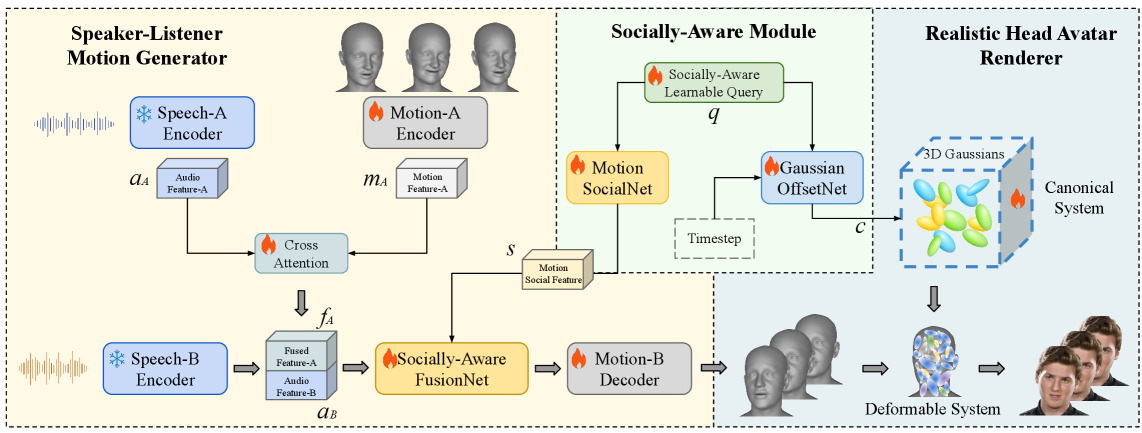
技术框架:RSATalker框架包含三个主要阶段:1) 从语音驱动基于网格的3D面部运动;2) 将3D高斯绑定到网格面片以进行渲染;3) 通过社交感知模块编码社会关系并影响说话头的行为。该框架使用三阶段训练范式进行训练,包括面部运动生成、高斯绑定和社交感知模块训练。
关键创新:RSATalker的关键创新在于:1) 首次将3DGS应用于社交感知的说话头生成,实现了逼真且高效的渲染;2) 提出了社交感知模块,能够将社会关系编码为高级嵌入,并影响说话头的行为,从而捕捉人际互动;3) 构建了RSATalker数据集,包含语音-网格-图像三元组,并标注了社会关系。
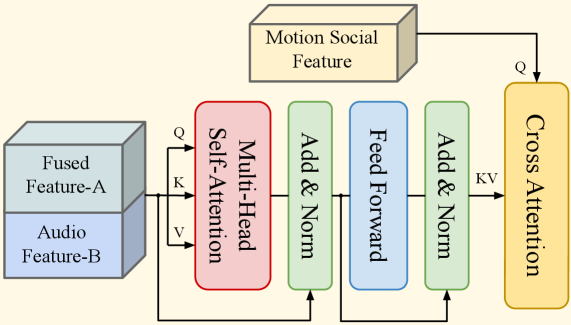
关键设计:社交感知模块使用可学习的查询机制,将社会关系(包括血缘和非血缘、平等和不平等)编码为高级嵌入。损失函数的设计考虑了真实感、面部运动的准确性和社交感知的效果。三阶段训练范式保证了各个模块的有效训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RSATalker在真实感和社交感知方面均优于现有技术。具体而言,RSATalker在主观评价指标(如用户满意度)和客观评价指标(如面部表情准确度)上均取得了显著提升。与现有方法相比,RSATalker能够生成更逼真、更具社交意识的说话头,从而提升用户的虚拟交互体验。
🎯 应用场景
RSATalker可应用于虚拟现实、在线教育、远程会议、虚拟助手等领域,实现更自然、更具社交性的虚拟交互体验。该技术有助于提升用户在虚拟环境中的沉浸感和参与度,促进人与人之间的有效沟通和协作,并为个性化虚拟形象定制提供新的可能性。
📄 摘要(原文)
Talking head generation is increasingly important in virtual reality (VR), especially for social scenarios involving multi-turn conversation. Existing approaches face notable limitations: mesh-based 3D methods can model dual-person dialogue but lack realistic textures, while large-model-based 2D methods produce natural appearances but incur prohibitive computational costs. Recently, 3D Gaussian Splatting (3DGS) based methods achieve efficient and realistic rendering but remain speaker-only and ignore social relationships. We introduce RSATalker, the first framework that leverages 3DGS for realistic and socially-aware talking head generation with support for multi-turn conversation. Our method first drives mesh-based 3D facial motion from speech, then binds 3D Gaussians to mesh facets to render high-fidelity 2D avatar videos. To capture interpersonal dynamics, we propose a socially-aware module that encodes social relationships, including blood and non-blood as well as equal and unequal, into high-level embeddings through a learnable query mechanism. We design a three-stage training paradigm and construct the RSATalker dataset with speech-mesh-image triplets annotated with social relationships. Extensive experiments demonstrate that RSATalker achieves state-of-the-art performance in both realism and social awareness. The code and dataset will be released.