Action100M: A Large-scale Video Action Dataset
作者: Delong Chen, Tejaswi Kasarla, Yejin Bang, Mustafa Shukor, Willy Chung, Jade Yu, Allen Bolourchi, Theo Moutakanni, Pascale Fung
分类: cs.CV
发布日期: 2026-01-15
💡 一句话要点
提出Action100M大规模视频动作数据集,促进视频理解和世界建模研究。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频动作识别 大规模数据集 自监督学习 视频理解 世界建模
📋 核心要点
- 现有视频动作数据集规模有限,难以支持开放词汇和复杂场景下的动作理解。
- 论文提出Action100M数据集,利用全自动流程从互联网视频中提取并标注大规模动作片段。
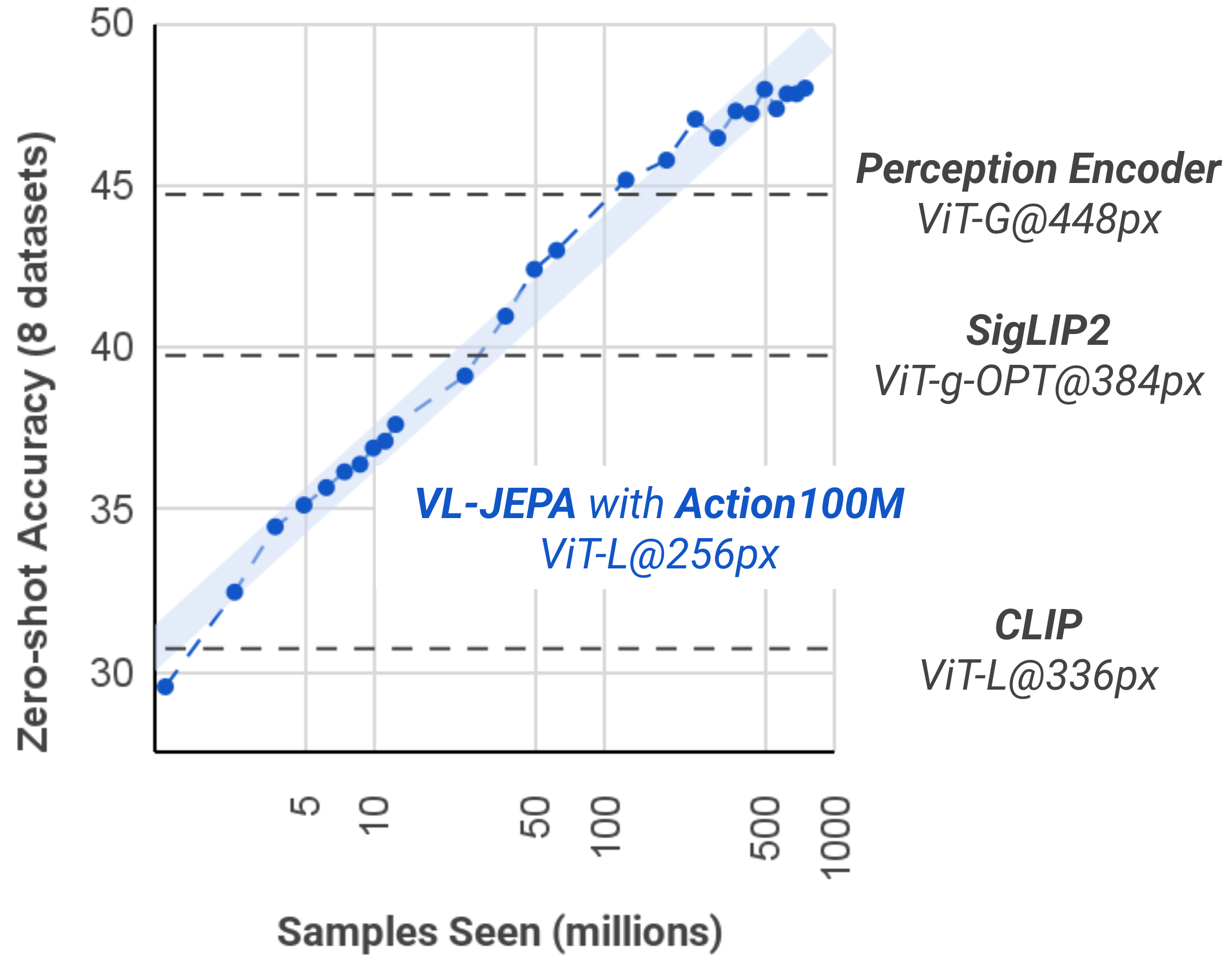
- 实验表明,在Action100M上训练的模型在多个动作识别基准测试中表现出强大的零样本性能。
📝 摘要(中文)
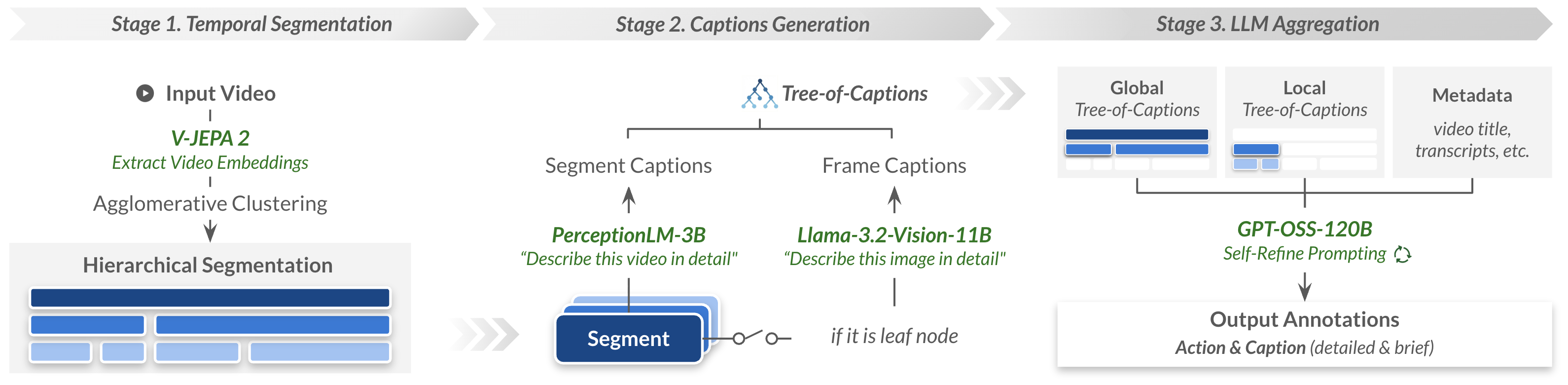
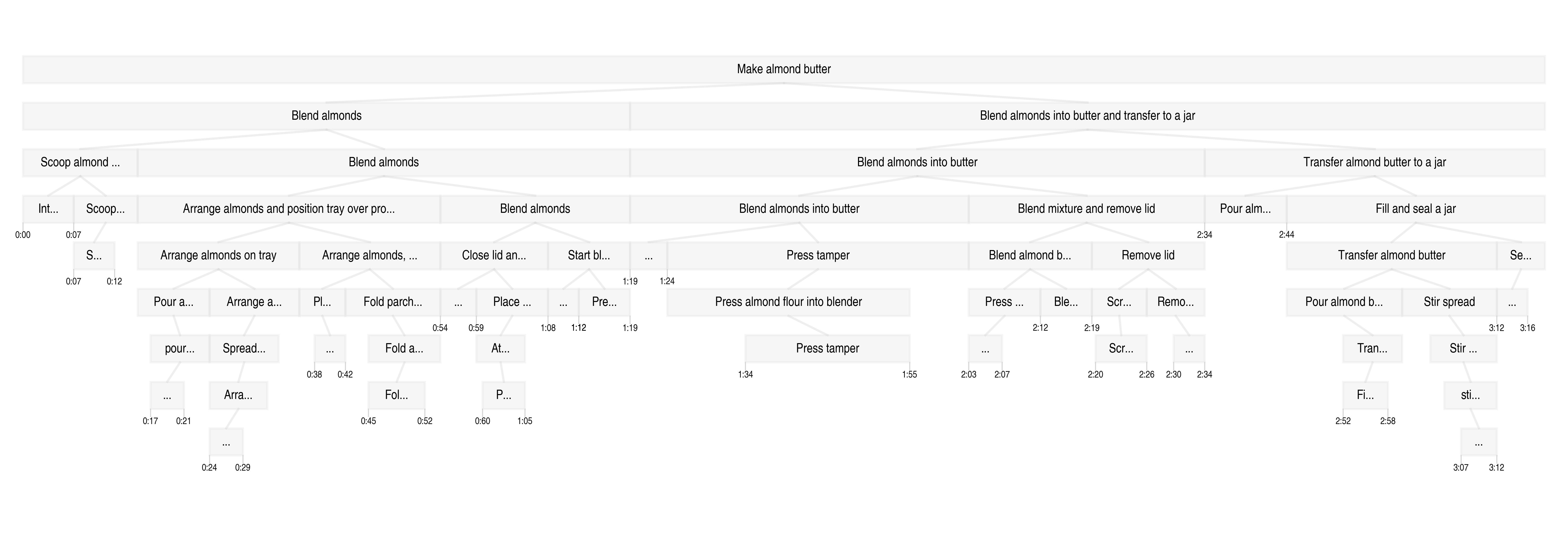
本文介绍Action100M,一个大规模数据集,由120万个互联网教学视频(总时长14.6年)构建而成,包含约1亿个时间局部化的片段,具有开放词汇的动作监督和丰富的字幕。Action100M通过全自动流程生成,该流程包括:(i) 使用V-JEPA 2嵌入进行分层时间分割,(ii) 生成组织为字幕树的多级帧和片段字幕,以及 (iii) 在多轮自精炼程序下,使用推理模型(GPT-OSS-120B)聚合证据,以输出结构化注释(简短/详细的动作、演员、简短/详细的字幕)。在Action100M上训练VL-JEPA展示了持续的数据规模改进,并在各种动作识别基准测试中表现出强大的零样本性能,从而将Action100M确立为视频理解和世界建模中可扩展研究的新基础。
🔬 方法详解
问题定义:现有视频动作数据集在规模、开放词汇和标注质量方面存在不足,限制了模型在复杂场景下的泛化能力。特别是,缺乏能够支持开放词汇动作识别和世界建模的大规模数据集。
核心思路:论文的核心思路是利用互联网上的教学视频资源,通过全自动化的流程生成大规模、高质量的视频动作数据集。通过分层时间分割、多级字幕生成和自精炼推理,实现对视频片段的精确标注。
技术框架:Action100M的生成流程主要包含三个阶段:(1) 使用V-JEPA 2嵌入进行分层时间分割,将视频分割成具有语义意义的片段。(2) 生成多级帧和片段字幕,构建字幕树,提供丰富的上下文信息。(3) 使用GPT-OSS-120B等大型语言模型进行多轮自精炼,聚合证据,输出结构化的动作、演员和字幕注释。
关键创新:该方法最大的创新在于其全自动化的数据生成流程,能够高效地从海量互联网视频中提取并标注高质量的动作片段。自精炼过程利用大型语言模型的推理能力,显著提升了标注的准确性和一致性。
关键设计:V-JEPA 2嵌入用于视频分割,能够捕捉视频中的时间依赖关系。字幕树结构能够提供多层次的上下文信息,有助于动作理解。GPT-OSS-120B等大型语言模型用于自精炼,能够利用其强大的语言理解和推理能力,提升标注质量。多轮自精炼过程通过迭代优化,逐步提升标注的准确性和一致性。
🖼️ 关键图片
📊 实验亮点
在Action100M上训练的VL-JEPA模型在多个动作识别基准测试中表现出强大的零样本性能,证明了该数据集的有效性。实验结果表明,随着数据规模的增加,模型的性能持续提升,表明Action100M为可扩展的视频理解研究奠定了基础。
🎯 应用场景
Action100M数据集可广泛应用于视频理解、机器人学习、人机交互等领域。例如,可以用于训练能够识别和理解复杂动作的智能体,提升机器人在真实世界中的操作能力。此外,该数据集还可以促进视频内容分析、智能监控等应用的发展。
📄 摘要(原文)
Inferring physical actions from visual observations is a fundamental capability for advancing machine intelligence in the physical world. Achieving this requires large-scale, open-vocabulary video action datasets that span broad domains. We introduce Action100M, a large-scale dataset constructed from 1.2M Internet instructional videos (14.6 years of duration), yielding O(100 million) temporally localized segments with open-vocabulary action supervision and rich captions. Action100M is generated by a fully automated pipeline that (i) performs hierarchical temporal segmentation using V-JEPA 2 embeddings, (ii) produces multi-level frame and segment captions organized as a Tree-of-Captions, and (iii) aggregates evidence with a reasoning model (GPT-OSS-120B) under a multi-round Self-Refine procedure to output structured annotations (brief/detailed action, actor, brief/detailed caption). Training VL-JEPA on Action100M demonstrates consistent data-scaling improvements and strong zero-shot performance across diverse action recognition benchmarks, establishing Action100M as a new foundation for scalable research in video understanding and world modeling.