Inference-time Physics Alignment of Video Generative Models with Latent World Models
作者: Jianhao Yuan, Xiaofeng Zhang, Felix Friedrich, Nicolas Beltran-Velez, Melissa Hall, Reyhane Askari-Hemmat, Xiaochuang Han, Nicolas Ballas, Michal Drozdzal, Adriana Romero-Soriano
分类: cs.CV
发布日期: 2026-01-15
备注: 22 pages, 10 figures
💡 一句话要点
提出WMReward,通过推理时物理对齐提升视频生成模型的物理合理性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频生成 物理合理性 潜在世界模型 推理时优化 奖励函数
📋 核心要点
- 现有视频生成模型常违反物理定律,限制了应用,部分原因是次优的推理策略。
- 提出WMReward,利用潜在世界模型的物理先验作为奖励,引导去噪轨迹搜索,提升物理合理性。
- 在多个生成任务中显著提升物理合理性,并在PhysicsIQ Challenge中超越现有技术7.42%。
📝 摘要(中文)
先进的视频生成模型在视觉内容生成方面表现出色,但常常违反基本的物理定律,限制了它们的实用性。虽然一些人认为这是由于预训练阶段对物理知识理解不足,但我们发现物理合理性的缺失也源于次优的推理策略。因此,我们引入了WMReward,并将提高视频生成的物理合理性视为一个推理时对齐问题。具体而言,我们利用潜在世界模型(此处为VJEPA-2)强大的物理先验作为奖励,搜索和引导多个候选去噪轨迹,从而通过扩展测试时计算来获得更好的生成性能。实验结果表明,我们的方法在图像条件、多帧条件和文本条件生成设置下,显著提高了物理合理性,并通过人类偏好研究得到了验证。值得注意的是,在ICCV 2025 Perception Test PhysicsIQ Challenge中,我们获得了62.64%的最终得分,赢得第一名,并超过了之前的最先进水平7.42%。我们的工作证明了使用潜在世界模型来提高视频生成的物理合理性的可行性,超越了特定的实例化或参数化。
🔬 方法详解
问题定义:现有视频生成模型虽然能生成高质量的视觉内容,但经常违反基本的物理定律,例如物体运动不符合重力规律、碰撞后行为不合理等。这限制了它们在需要物理合理性的应用场景中的使用。现有的方法通常侧重于在预训练阶段提升模型对物理世界的理解,但忽略了推理阶段的优化。
核心思路:论文的核心思路是将视频生成的物理合理性问题视为一个推理时对齐问题。通过利用一个预训练的潜在世界模型(LWM)作为物理先验,在推理阶段对视频生成模型的输出进行引导,使其更符合物理规律。具体来说,LWM被用作一个奖励函数,用于评估不同生成轨迹的物理合理性,并选择或调整生成结果。
技术框架:整体框架包含以下几个主要模块:1) 视频生成模型:用于生成初始的视频片段。2) 潜在世界模型(LWM):用于评估视频片段的物理合理性,并提供奖励信号。3) 搜索和引导模块:基于LWM的奖励信号,搜索多个候选的去噪轨迹,并选择或调整生成结果,使其更符合物理规律。该框架在推理阶段运行,不需要重新训练视频生成模型。
关键创新:最重要的技术创新点在于将潜在世界模型引入到视频生成的推理过程中,并将其用作奖励函数来引导生成过程。这使得可以在不改变视频生成模型本身的情况下,显著提高生成结果的物理合理性。与现有方法相比,该方法更加灵活,可以应用于不同的视频生成模型和不同的物理场景。
关键设计:论文使用了VJEPA-2作为潜在世界模型,并设计了一个基于搜索的优化算法来寻找最佳的去噪轨迹。具体来说,该算法首先生成多个候选的去噪轨迹,然后使用VJEPA-2评估每个轨迹的物理合理性,并选择奖励最高的轨迹作为最终的生成结果。此外,论文还设计了一些参数来控制搜索的范围和步长,以平衡生成质量和计算成本。
🖼️ 关键图片
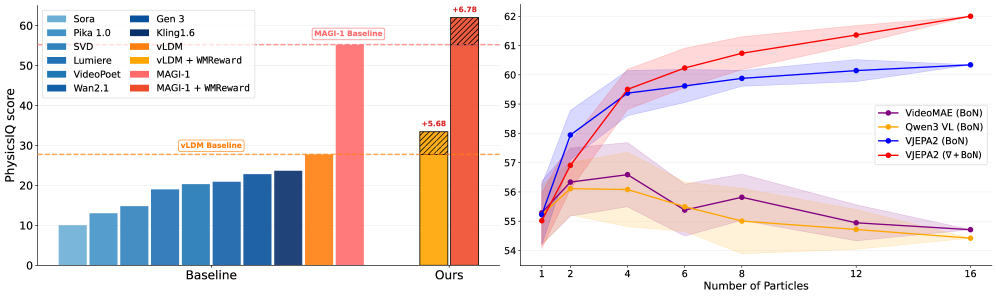

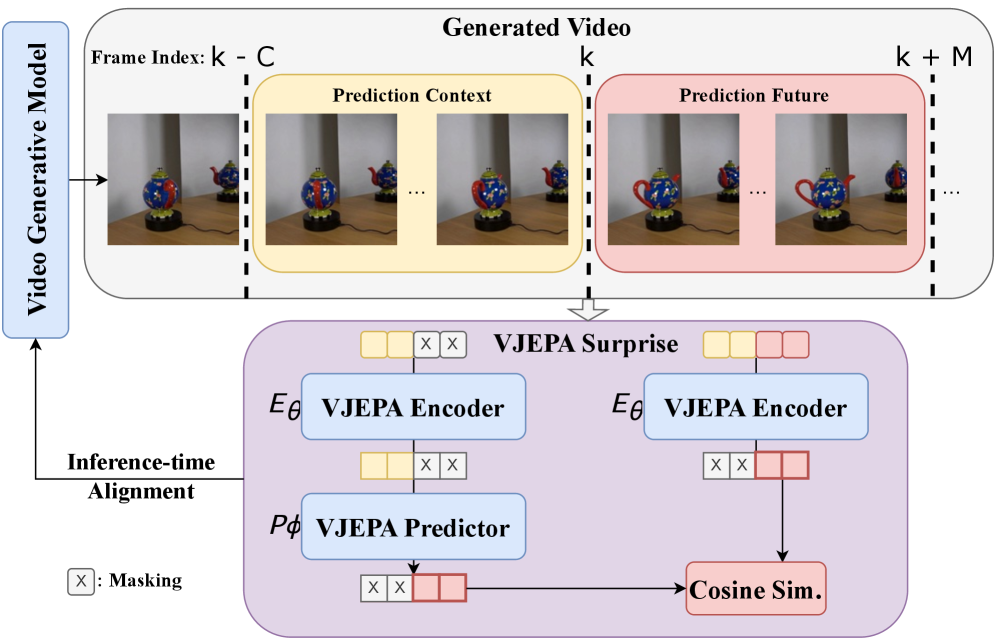
📊 实验亮点
实验结果表明,WMReward方法在图像条件、多帧条件和文本条件生成设置下,显著提高了视频生成的物理合理性。在ICCV 2025 Perception Test PhysicsIQ Challenge中,该方法获得了62.64%的最终得分,赢得第一名,并超过了之前的最先进水平7.42%。人类偏好研究也表明,该方法生成的视频在物理合理性方面更受用户青睐。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、游戏开发、机器人仿真等领域。通过提高生成视频的物理合理性,可以增强用户体验,提高仿真环境的真实性,并促进机器人对物理世界的理解和交互。未来,该方法有望应用于自动驾驶、智能监控等更复杂的场景。
📄 摘要(原文)
State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.