Unleashing the Capabilities of Large Vision-Language Models for Intelligent Perception of Roadside Infrastructure
作者: Luxuan Fu, Chong Liu, Bisheng Yang, Zhen Dong
分类: cs.CV
发布日期: 2026-01-15
💡 一句话要点
提出领域自适应框架,利用大视觉语言模型实现道路基础设施的智能感知。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉语言模型 道路基础设施 目标检测 属性识别 知识增强 领域自适应 检索增强生成
📋 核心要点
- 通用模型难以捕捉道路基础设施的细粒度属性和领域规则,导致性能不佳。
- 提出领域自适应框架,结合数据高效微调和知识驱动推理,提升VLM的感知能力。
- 在道路场景数据集上,检测性能达到58.9 mAP,属性识别准确率达到95.5%。
📝 摘要(中文)
城市道路基础设施的自动感知对于智慧城市管理至关重要,但通用模型通常难以捕捉必要的细粒度属性和领域规则。大型视觉语言模型(VLMs)虽然擅长开放世界的识别,但通常难以准确解释符合工程标准的复杂设施状态,导致在实际应用中性能不可靠。为了解决这个问题,我们提出了一个领域自适应框架,将VLMs转化为用于智能基础设施分析的专用代理。我们的方法集成了数据高效的微调策略和知识驱动的推理机制。具体来说,我们利用Grounding DINO上的开放词汇微调,以最小的监督稳健地定位各种资产,然后基于LoRA在Qwen-VL上进行自适应,以进行深度语义属性推理。为了减轻幻觉并强制执行专业合规性,我们引入了一个双模态检索增强生成(RAG)模块,该模块在推理过程中动态检索权威的行业标准和视觉范例。在一个全面的城市道路场景新数据集上进行评估,我们的框架实现了58.9 mAP的检测性能和95.5%的属性识别准确率,展示了一个用于智能基础设施监控的强大解决方案。
🔬 方法详解
问题定义:现有方法难以准确感知城市道路基础设施的细粒度属性,并且难以符合工程标准。通用视觉语言模型在开放世界识别方面表现良好,但在理解复杂设施状态和专业规则方面存在不足,导致实际应用中性能不可靠。
核心思路:将大型视觉语言模型(VLMs)转化为专门用于智能基础设施分析的代理。通过领域自适应微调和知识增强推理,使模型能够更好地理解和解释道路基础设施的复杂状态,并符合行业标准。
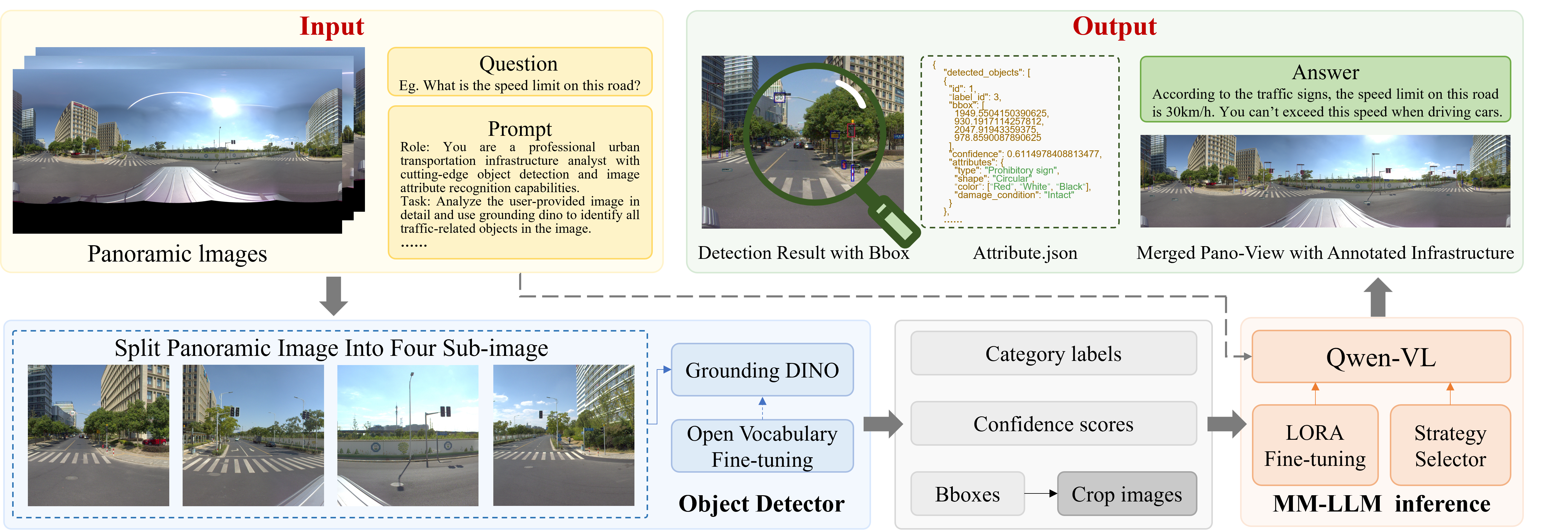
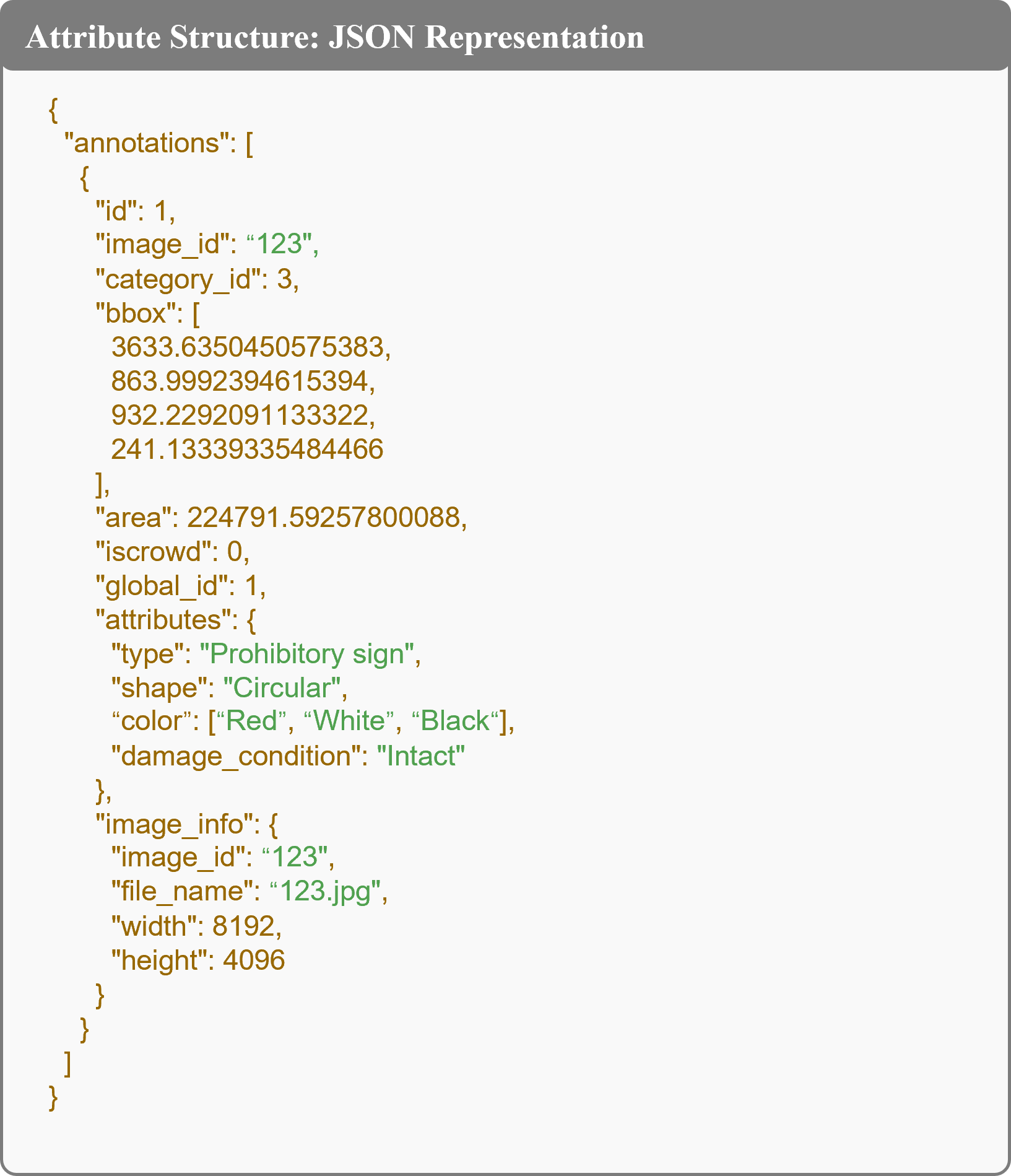
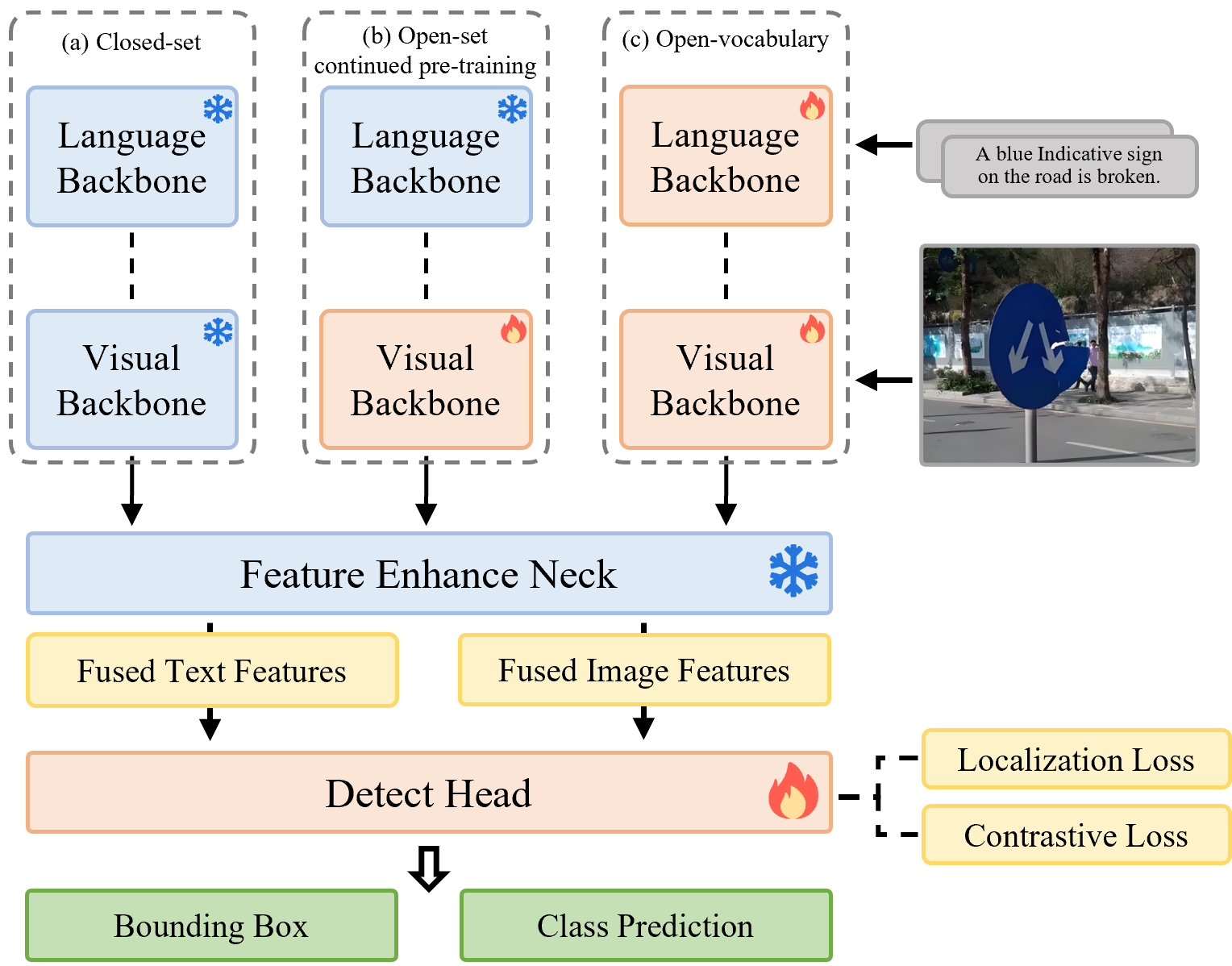
技术框架:该框架主要包含三个模块:1) 基于Grounding DINO的开放词汇目标检测,用于定位道路基础设施;2) 基于LoRA的Qwen-VL微调,用于进行深度语义属性推理;3) 双模态检索增强生成(RAG)模块,用于检索行业标准和视觉范例,以减轻幻觉并强制执行专业合规性。整体流程是先进行目标检测,然后进行属性推理,最后通过RAG模块进行知识增强。
关键创新:该方法的核心创新在于将数据高效的微调策略与知识驱动的推理机制相结合。通过开放词汇微调和LoRA自适应,模型能够以最小的监督学习到道路基础设施的细粒度特征。RAG模块的引入,使得模型能够在推理过程中动态地检索相关知识,从而提高推理的准确性和可靠性。
关键设计:Grounding DINO用于目标检测,采用开放词汇训练方式,能够检测各种道路基础设施。Qwen-VL使用LoRA进行微调,降低了计算成本和存储需求。RAG模块使用双模态检索,同时考虑文本和视觉信息,以提高检索的准确性。损失函数的设计可能包括目标检测损失、属性分类损失和知识一致性损失。
🖼️ 关键图片
📊 实验亮点
该框架在城市道路场景数据集上取得了显著的性能提升。目标检测性能达到58.9 mAP,属性识别准确率达到95.5%。实验结果表明,该方法能够有效地提高VLM在道路基础设施感知方面的准确性和可靠性,为实际应用奠定了基础。
🎯 应用场景
该研究成果可应用于智慧城市管理、自动驾驶、道路安全监测等领域。通过自动感知道路基础设施的状态,可以及时发现并处理安全隐患,提高道路维护效率,为自动驾驶车辆提供更准确的环境信息,从而提升城市交通的安全性和效率。
📄 摘要(原文)
Automated perception of urban roadside infrastructure is crucial for smart city management, yet general-purpose models often struggle to capture the necessary fine-grained attributes and domain rules. While Large Vision Language Models (VLMs) excel at open-world recognition, they often struggle to accurately interpret complex facility states in compliance with engineering standards, leading to unreliable performance in real-world applications. To address this, we propose a domain-adapted framework that transforms VLMs into specialized agents for intelligent infrastructure analysis. Our approach integrates a data-efficient fine-tuning strategy with a knowledge-grounded reasoning mechanism. Specifically, we leverage open-vocabulary fine-tuning on Grounding DINO to robustly localize diverse assets with minimal supervision, followed by LoRA-based adaptation on Qwen-VL for deep semantic attribute reasoning. To mitigate hallucinations and enforce professional compliance, we introduce a dual-modality Retrieval-Augmented Generation (RAG) module that dynamically retrieves authoritative industry standards and visual exemplars during inference. Evaluated on a comprehensive new dataset of urban roadside scenes, our framework achieves a detection performance of 58.9 mAP and an attribute recognition accuracy of 95.5%, demonstrating a robust solution for intelligent infrastructure monitoring.