Fine-Grained Human Pose Editing Assessment via Layer-Selective MLLMs
作者: Ningyu Sun, Zhaolin Cai, Zitong Xu, Peihang Chen, Huiyu Duan, Yichao Yan, Xiongkuo Min, Xiaokang Yang
分类: cs.CV
发布日期: 2026-01-15
💡 一句话要点
提出基于层选择多模态大语言模型的细粒度人体姿态编辑评估方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体姿态编辑 多模态大语言模型 层选择 质量评估 真实性检测 AIGC LoRA微调
📋 核心要点
- 现有姿态编辑评估方法缺乏对姿态特定不一致性的细粒度洞察,无法有效区分真实性和质量。
- 利用层选择多模态大语言模型,通过对比LoRA微调和层敏感性分析,优化姿态评估特征层。
- 提出的框架在真实性检测和多维度质量回归上表现出色,有效连接了取证检测和质量评估。
📝 摘要(中文)
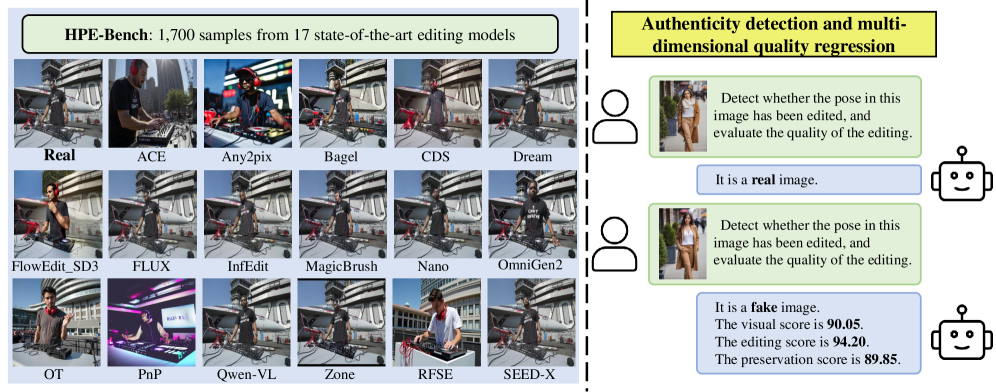
本文针对文本引导的人体姿态编辑中存在的结构异常和生成伪影问题,以及现有评估指标无法提供姿态特定不一致性的细粒度洞察的问题,提出了HPE-Bench基准测试集,包含来自17个最先进编辑模型的1700个标准化样本,提供真实性标签和多维度质量评分。此外,本文还提出了一个基于层选择多模态大语言模型(MLLM)的统一框架。通过对比LoRA微调和一种新颖的层敏感性分析(LSA)机制,该框架能够识别用于姿态评估的最佳特征层,并在真实性检测和多维度质量回归方面均取得了优异的性能,有效弥合了取证检测和质量评估之间的差距。
🔬 方法详解
问题定义:文本引导的人体姿态编辑容易产生结构异常和生成伪影,现有的评估指标通常将真实性检测与质量评估孤立开来,无法提供针对特定姿态不一致性的细粒度分析,难以指导模型的改进。
核心思路:利用多模态大语言模型(MLLM)强大的理解和推理能力,结合图像和文本信息,对编辑后的人体姿态进行综合评估。通过选择合适的特征层,使MLLM能够更有效地捕捉姿态相关的细粒度信息,从而提高评估的准确性和可靠性。
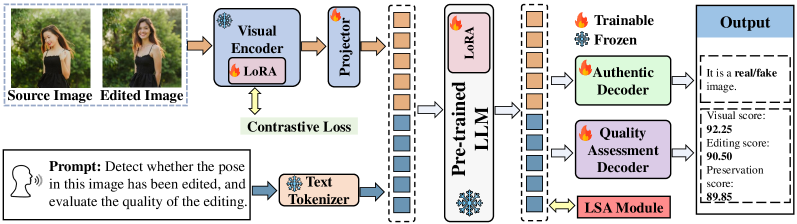
技术框架:该框架主要包含以下几个阶段:1) 数据准备:使用HPE-Bench基准测试集,包含真实性标签和多维度质量评分。2) 特征提取:使用预训练的视觉模型提取图像特征。3) 层选择:通过层敏感性分析(LSA)确定用于姿态评估的最佳特征层。4) MLLM微调:使用对比LoRA微调策略,训练MLLM进行真实性检测和质量回归。5) 评估:使用训练好的MLLM对编辑后的人体姿态进行评估。
关键创新:该方法的核心创新在于:1) 提出了HPE-Bench基准测试集,为姿态编辑评估提供了标准化的数据和评估指标。2) 提出了层敏感性分析(LSA)机制,能够自动选择用于姿态评估的最佳特征层,从而提高评估的准确性。3) 使用对比LoRA微调策略,有效地训练MLLM进行姿态评估。与现有方法相比,该方法能够提供更细粒度、更准确的姿态编辑评估结果。
关键设计:层敏感性分析(LSA)通过计算不同特征层对评估任务的贡献度,选择贡献度最高的层作为最佳特征层。对比LoRA微调策略通过构建正负样本对,训练MLLM区分真实和伪造的姿态编辑结果,并回归多维度质量评分。具体的损失函数包括对比损失和回归损失。网络结构方面,采用了预训练的视觉模型(如CLIP)和MLLM(如LLaVA)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在HPE-Bench基准测试集上取得了显著的性能提升。在真实性检测方面,该方法优于现有的取证检测方法。在多维度质量回归方面,该方法能够更准确地预测姿态编辑图像的质量评分,与人工评估结果更加一致。具体的数据指标需要在论文中查找。
🎯 应用场景
该研究成果可应用于AIGC领域,例如提升文本引导图像编辑的质量控制,辅助生成更逼真、符合预期的姿态编辑图像。此外,该方法还可用于评估和改进现有的姿态编辑模型,推动相关技术的发展。未来,该方法有望扩展到其他图像编辑任务的评估中,例如人脸编辑、物体编辑等。
📄 摘要(原文)
Text-guided human pose editing has gained significant traction in AIGC applications. However,it remains plagued by structural anomalies and generative artifacts. Existing evaluation metrics often isolate authenticity detection from quality assessment, failing to provide fine-grained insights into pose-specific inconsistencies. To address these limitations, we introduce HPE-Bench, a specialized benchmark comprising 1,700 standardized samples from 17 state-of-the-art editing models, offering both authenticity labels and multi-dimensional quality scores. Furthermore, we propose a unified framework based on layer-selective multimodal large language models (MLLMs). By employing contrastive LoRA tuning and a novel layer sensitivity analysis (LSA) mechanism, we identify the optimal feature layer for pose evaluation. Our framework achieves superior performance in both authenticity detection and multi-dimensional quality regression, effectively bridging the gap between forensic detection and quality assessment.