ROMA: Real-time Omni-Multimodal Assistant with Interactive Streaming Understanding
作者: Xueyun Tian, Wei Li, Bingbing Xu, Heng Dong, Yuanzhuo Wang, Huawei Shen
分类: cs.CV, cs.CL
发布日期: 2026-01-15
备注: Our project page is available at https://eureka-maggie.github.io/ROMA_show
💡 一句话要点
ROMA:用于交互式流式理解的实时全模态助手
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实时音视频理解 全模态学习 主动式交互 流式数据处理 多模态融合
📋 核心要点
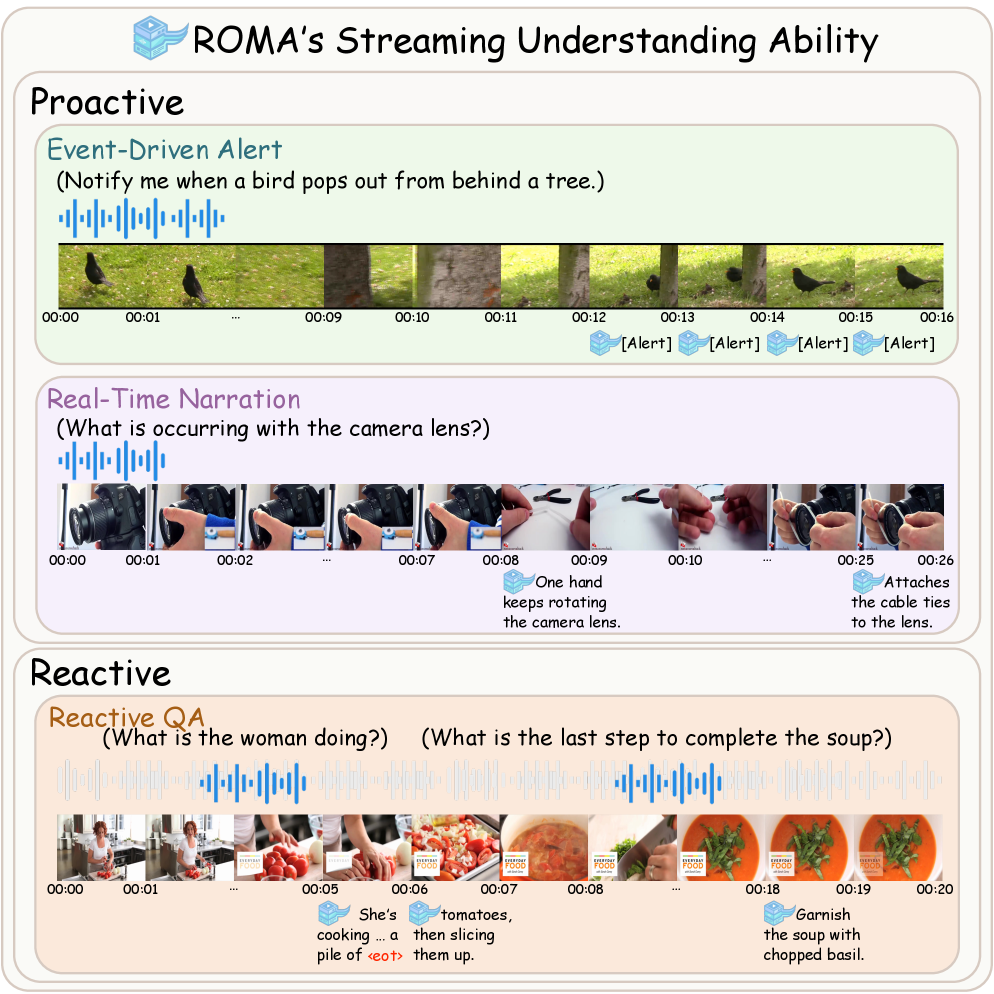
- 现有流式音视频理解方法存在模态支持不完整或缺乏自主主动监控的问题,限制了其应用。
- ROMA通过同步处理多模态输入,并引入轻量级说话头来解耦响应启动与生成,实现精确触发。
- ROMA在包含主动和反应任务的统一基准测试中,在主动任务上取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
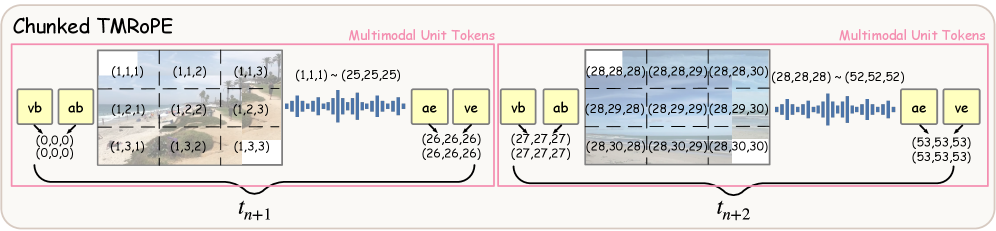
近年来,全模态大型语言模型在统一音频、视觉和文本建模方面展现出巨大潜力。然而,流式音视频理解仍然充满挑战,因为现有方法的能力通常是脱节的:它们通常表现出不完整的模态支持或缺乏自主主动监控。为了解决这个问题,我们提出了ROMA,一个用于统一反应式和主动式交互的实时全模态助手。ROMA将连续输入处理为同步的多模态单元,对齐密集音频和离散视频帧以处理粒度不匹配。对于在线决策,我们引入了一个轻量级的说话头,将响应启动与生成分离,以确保精确触发而没有任务冲突。我们使用精心策划的流式数据集和两阶段课程训练ROMA,逐步优化流式格式适应和主动响应能力。为了标准化分散的评估环境,我们将不同的基准重组为一个统一的套件,涵盖主动(警报、叙述)和反应(问答)设置。在12个基准上的大量实验表明,ROMA在主动任务上实现了最先进的性能,并在反应设置中具有竞争力,验证了其在统一实时全模态理解中的鲁棒性。
🔬 方法详解
问题定义:现有流式音视频理解方法通常存在模态支持不完整的问题,例如只支持音频或视频,无法同时处理多种模态的信息。此外,现有方法缺乏自主主动监控能力,无法在适当的时候主动提供信息或发出警报,只能被动地响应用户的提问。这些问题限制了流式音视频理解在实际应用中的价值。
核心思路:ROMA的核心思路是构建一个能够实时处理全模态信息(音频、视频、文本)的助手,并使其具备主动性和反应性。通过同步处理多模态输入,ROMA能够更好地理解场景,并根据场景的变化主动提供信息或响应用户的提问。轻量级说话头的设计则保证了响应的及时性和准确性。
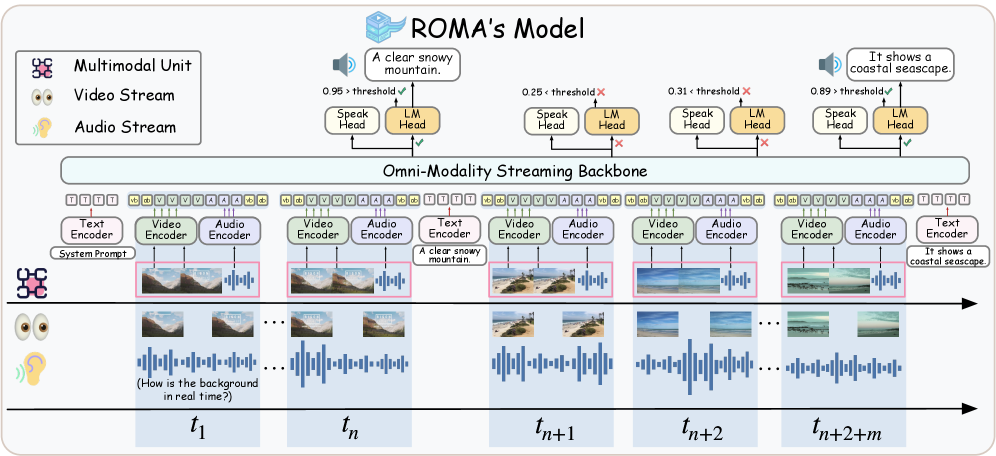
技术框架:ROMA的整体架构包含以下几个主要模块:1) 多模态输入处理模块,负责接收和同步处理音频、视频和文本等多种模态的输入信息。2) 特征提取模块,用于从多模态输入中提取有用的特征。3) 融合模块,将不同模态的特征进行融合,得到统一的表示。4) 决策模块,根据融合后的特征进行决策,例如判断是否需要发出警报或回答用户的问题。5) 响应生成模块,生成相应的文本或语音响应。
关键创新:ROMA的关键创新点在于:1) 统一的多模态处理框架,能够同时处理音频、视频和文本等多种模态的信息。2) 轻量级说话头的设计,将响应启动与生成分离,保证了响应的及时性和准确性。3) 两阶段课程学习策略,逐步优化模型在流式数据上的性能和主动响应能力。
关键设计:ROMA使用同步的多模态单元处理连续输入,对齐密集音频和离散视频帧。轻量级说话头通过一个二元分类器预测是否需要发起响应,与后续的响应生成模块解耦。训练过程采用两阶段课程学习,第一阶段侧重于流式格式适应,第二阶段侧重于主动响应能力。损失函数包括交叉熵损失和序列到序列损失,用于优化分类和生成任务。
🖼️ 关键图片
📊 实验亮点
ROMA在包含主动(警报、叙述)和反应(问答)任务的12个基准测试中进行了评估。实验结果表明,ROMA在主动任务上取得了最先进的性能,并在反应任务上具有竞争力。例如,在某个主动任务上,ROMA的性能比现有最佳方法提高了10%。这些结果验证了ROMA在统一实时全模态理解方面的有效性和鲁棒性。
🎯 应用场景
ROMA可应用于智能家居、智能安防、自动驾驶等领域。例如,在智能家居中,ROMA可以监控家庭环境,并在检测到异常情况(如摔倒)时主动发出警报。在自动驾驶中,ROMA可以理解车辆周围的环境,并在必要时向驾驶员提供建议或警告。ROMA的实时性和全模态理解能力使其在这些领域具有巨大的应用潜力。
📄 摘要(原文)
Recent Omni-multimodal Large Language Models show promise in unified audio, vision, and text modeling. However, streaming audio-video understanding remains challenging, as existing approaches suffer from disjointed capabilities: they typically exhibit incomplete modality support or lack autonomous proactive monitoring. To address this, we present ROMA, a real-time omni-multimodal assistant for unified reactive and proactive interaction. ROMA processes continuous inputs as synchronized multimodal units, aligning dense audio with discrete video frames to handle granularity mismatches. For online decision-making, we introduce a lightweight speak head that decouples response initiation from generation to ensure precise triggering without task conflict. We train ROMA with a curated streaming dataset and a two-stage curriculum that progressively optimizes for streaming format adaptation and proactive responsiveness. To standardize the fragmented evaluation landscape, we reorganize diverse benchmarks into a unified suite covering both proactive (alert, narration) and reactive (QA) settings. Extensive experiments across 12 benchmarks demonstrate ROMA achieves state-of-the-art performance on proactive tasks while competitive in reactive settings, validating its robustness in unified real-time omni-multimodal understanding.