Hierarchical Refinement of Universal Multimodal Attacks on Vision-Language Models
作者: Peng-Fei Zhang, Zi Huang
分类: cs.CV, cs.MM
发布日期: 2026-01-15
备注: 15 pages, 7 figures
💡 一句话要点
提出层级细化的通用多模态攻击框架HRA,提升视觉-语言模型的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 对抗攻击 通用对抗扰动 层级细化 鲁棒性 多模态学习 ScMix增强
📋 核心要点
- 现有VLP模型对抗攻击计算开销大,难以扩展到大型数据集和新场景。
- HRA框架通过层级细化通用对抗扰动,在样本和优化层面提升攻击效果。
- 实验表明,HRA在各种下游任务、VLP模型和数据集上表现出优越的攻击性能。
📝 摘要(中文)
现有的视觉-语言预训练模型(VLP)对抗攻击大多是样本特定的,当扩展到大型数据集或新场景时,会导致大量的计算开销。为了克服这一限制,我们提出了层级细化攻击(HRA),这是一个用于VLP模型的通用多模态攻击框架。HRA在样本层面和优化层面细化通用对抗扰动(UAP)。对于图像模态,我们将对抗样本分解为干净图像和扰动,允许独立处理每个组件,以更有效地破坏跨模态对齐。我们进一步引入了ScMix增强策略,该策略使视觉上下文多样化,并增强UAP的全局和局部效用,从而减少对虚假特征的依赖。此外,我们利用历史和估计的未来梯度的时序层级来细化优化路径,以避免局部最小值并稳定通用扰动学习。对于文本模态,HRA通过结合句子内和句子间重要性度量来识别全局有影响力的词,并随后使用这些词作为通用文本扰动。在各种下游任务、VLP模型和数据集上的大量实验证明了所提出的通用多模态攻击的优越性。
🔬 方法详解
问题定义:现有的VLP模型对抗攻击方法大多是针对特定样本设计的,这意味着需要为每个样本单独计算对抗扰动。当需要攻击大规模数据集或在新的场景中使用时,这种方法的计算成本非常高昂,效率低下。因此,如何设计一种通用的、高效的对抗攻击方法,使其能够一次性生成适用于多个样本的对抗扰动,是本文要解决的核心问题。
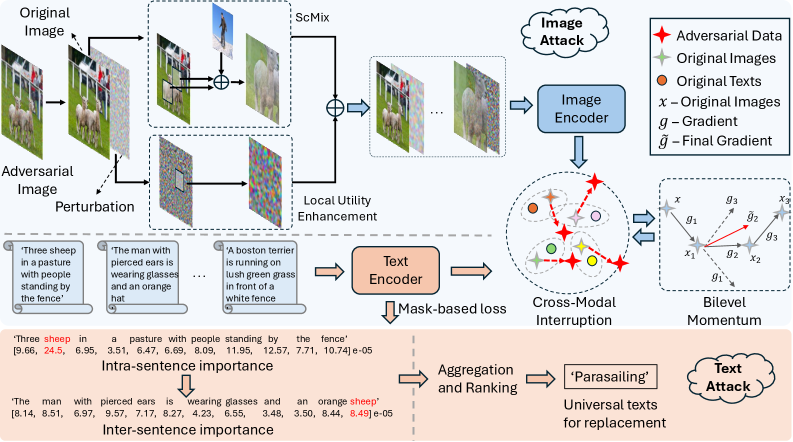
核心思路:本文的核心思路是提出一种层级细化的通用对抗攻击框架(HRA)。该框架通过在样本层面和优化层面进行细化,从而生成更有效的通用对抗扰动。具体来说,对于图像模态,HRA将对抗样本分解为干净图像和扰动,并独立处理它们,以更好地破坏跨模态对齐。对于文本模态,HRA识别全局有影响力的词,并将其作为通用文本扰动。
技术框架:HRA框架主要包含图像模态攻击和文本模态攻击两个部分。图像模态攻击部分首先将对抗样本分解为干净图像和扰动,然后使用ScMix增强策略来增强UAP的全局和局部效用。同时,利用历史和估计的未来梯度的时序层级来细化优化路径,以避免局部最小值。文本模态攻击部分首先通过结合句子内和句子间重要性度量来识别全局有影响力的词,然后将这些词作为通用文本扰动。
关键创新:本文的关键创新在于提出了层级细化的通用对抗攻击框架(HRA)。与现有的样本特定攻击方法相比,HRA能够一次性生成适用于多个样本的对抗扰动,从而大大降低了计算成本。此外,HRA还提出了ScMix增强策略和基于时序层级的优化方法,进一步提升了攻击效果。
关键设计:在图像模态攻击中,ScMix增强策略通过混合不同的视觉上下文来增强UAP的泛化能力。在优化过程中,使用历史和估计的未来梯度来稳定通用扰动的学习,避免陷入局部最小值。在文本模态攻击中,通过结合句子内和句子间重要性度量来更准确地识别全局有影响力的词。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HRA在各种下游任务、VLP模型和数据集上都取得了显著的性能提升。例如,在视觉问答任务中,HRA相对于基线方法取得了超过10%的攻击成功率提升。此外,HRA还能够有效地攻击多种不同的VLP模型,表明其具有良好的通用性。
🎯 应用场景
该研究成果可应用于评估和提升视觉-语言模型的鲁棒性,例如在图像描述、视觉问答等任务中,通过对抗攻击来发现模型的脆弱点,并有针对性地进行防御。此外,该研究还可以用于生成对抗样本,以训练更鲁棒的视觉-语言模型,提高其在真实世界场景中的泛化能力。该研究对于保障AI系统的安全性和可靠性具有重要意义。
📄 摘要(原文)
Existing adversarial attacks for VLP models are mostly sample-specific, resulting in substantial computational overhead when scaled to large datasets or new scenarios. To overcome this limitation, we propose Hierarchical Refinement Attack (HRA), a multimodal universal attack framework for VLP models. HRA refines universal adversarial perturbations (UAPs) at both the sample level and the optimization level. For the image modality, we disentangle adversarial examples into clean images and perturbations, allowing each component to be handled independently for more effective disruption of cross-modal alignment. We further introduce a ScMix augmentation strategy that diversifies visual contexts and strengthens both global and local utility of UAPs, thereby reducing reliance on spurious features. In addition, we refine the optimization path by leveraging a temporal hierarchy of historical and estimated future gradients to avoid local minima and stabilize universal perturbation learning. For the text modality, HRA identifies globally influential words by combining intra-sentence and inter-sentence importance measures, and subsequently utilizes these words as universal text perturbations. Extensive experiments across various downstream tasks, VLP models, and datasets demonstrate the superiority of the proposed universal multimodal attacks.