Optimizing Multimodal LLMs for Egocentric Video Understanding: A Solution for the HD-EPIC VQA Challenge
作者: Sicheng Yang, Yukai Huang, Shitong Sun, Weitong Cai, Jiankang Deng, Jifei Song, Zhensong Zhang
分类: cs.CV, cs.MM, eess.IV
发布日期: 2026-01-15
备注: 4 pages, 1 figure, CVPR 2025 EgoVis Workshop, 2nd Place in HD-EPIC Challenge
🔗 代码/项目: GITHUB
💡 一句话要点
优化多模态LLM用于以自我为中心的视频理解,解决HD-EPIC VQA挑战
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 视频问答 以自我为中心视频 时间推理 链式思考
📋 核心要点
- 现有MLLM在处理HD-EPIC VQA等复杂视频问答任务时,面临查询歧义、时间推理不足和输出不规范等挑战。
- 论文提出一个端到端框架,包含查询预处理、领域微调、时间链式思考提示和后处理,以提升视频理解能力。
- 实验结果表明,该框架在HD-EPIC VQA上取得了41.6%的准确率,验证了整体管道优化的有效性。
📝 摘要(中文)
多模态大型语言模型(MLLM)在复杂的视频问答基准测试(如HD-EPIC VQA)中表现不佳,原因在于查询/选项的歧义性、较差的长程时间推理能力以及非标准化的输出。我们提出了一个框架,集成了查询/选项预处理、领域特定的Qwen2.5-VL微调、用于多步骤推理的新型时间链式思考(T-CoT)提示,以及鲁棒的后处理。该系统在HD-EPIC VQA上实现了41.6%的准确率,突出了在要求苛刻的视频理解中进行整体管道优化的必要性。我们的代码和微调模型可在https://github.com/YoungSeng/Egocentric-Co-Pilot获取。
🔬 方法详解
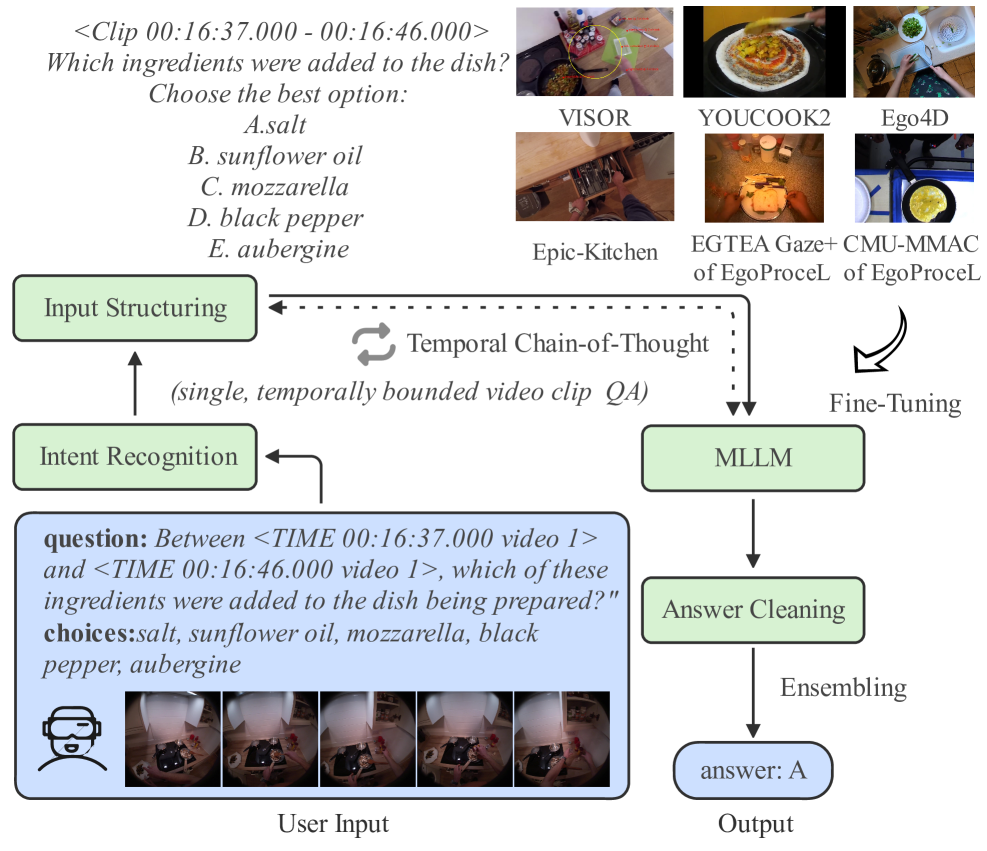
问题定义:HD-EPIC VQA任务要求模型理解以自我为中心的视频内容并回答相关问题。现有MLLM方法在该任务中面临的痛点包括:查询和选项存在歧义,难以进行长程时间推理,以及输出格式不规范,导致难以评估和利用。
核心思路:论文的核心思路是通过一个整体的优化框架,从数据预处理、模型微调、推理策略和后处理四个方面入手,解决现有方法在HD-EPIC VQA任务中的不足。该框架旨在提高模型对视频内容的理解能力,增强时间推理能力,并生成规范化的答案。
技术框架:整体框架包含以下四个主要模块:1) 查询/选项预处理:对输入的查询和选项进行清洗和规范化,减少歧义。2) 领域特定的Qwen2.5-VL微调:使用HD-EPIC数据集对Qwen2.5-VL模型进行微调,使其更适应以自我为中心的视频理解任务。3) 时间链式思考(T-CoT)提示:设计一种新型的提示策略,引导模型进行多步骤的时间推理,逐步推导出答案。4) 鲁棒的后处理:对模型的输出进行规范化和校正,提高答案的准确性。
关键创新:论文的关键创新在于提出了时间链式思考(T-CoT)提示策略。与传统的链式思考(CoT)提示不同,T-CoT提示侧重于引导模型进行时间推理,例如“首先发生了什么,然后发生了什么,最后发生了什么”,从而更好地理解视频中的事件序列和因果关系。此外,整体框架的端到端优化也是一个重要的创新点。
关键设计:在Qwen2.5-VL微调阶段,使用了HD-EPIC数据集进行监督学习,目标是最小化模型预测答案与真实答案之间的差异。T-CoT提示策略的设计需要仔细考虑提示词的选择和顺序,以有效地引导模型进行时间推理。后处理阶段采用了规则和启发式方法,对模型的输出进行规范化和校正。
🖼️ 关键图片
📊 实验亮点
该方法在HD-EPIC VQA数据集上取得了41.6%的准确率,显著优于现有的多模态LLM方法。时间链式思考(T-CoT)提示策略有效地提升了模型的时间推理能力。实验结果表明,整体框架的各个模块都对性能提升做出了贡献,验证了端到端优化的有效性。
🎯 应用场景
该研究成果可应用于智能助手、可穿戴设备和机器人等领域,帮助它们更好地理解人类的活动和意图。例如,智能眼镜可以根据用户的视角视频回答用户提出的问题,机器人可以根据观察到的场景进行决策和行动。该研究还有助于开发更智能的视频监控系统和人机交互界面。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) struggle with complex video QA benchmarks like HD-EPIC VQA due to ambiguous queries/options, poor long-range temporal reasoning, and non-standardized outputs. We propose a framework integrating query/choice pre-processing, domain-specific Qwen2.5-VL fine-tuning, a novel Temporal Chain-of-Thought (T-CoT) prompting for multi-step reasoning, and robust post-processing. This system achieves 41.6% accuracy on HD-EPIC VQA, highlighting the need for holistic pipeline optimization in demanding video understanding. Our code, fine-tuned models are available at https://github.com/YoungSeng/Egocentric-Co-Pilot.