RAG-3DSG: Enhancing 3D Scene Graphs with Re-Shot Guided Retrieval-Augmented Generation
作者: Yue Chang, Rufeng Chen, Zhaofan Zhang, Yi Chen, Sihong Xie
分类: cs.CV, cs.AI, cs.RO
发布日期: 2026-01-15
备注: 9 pages, 6 figures
💡 一句话要点
提出RAG-3DSG,通过重拍引导检索增强生成提升3D场景图质量。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景图生成 检索增强生成 不确定性估计 多视角图像 机器人导航
📋 核心要点
- 现有开放词汇3D场景图生成方法受限于视角、遮挡和冗余表面密度,导致物体识别精度和速度较低。
- RAG-3DSG通过重拍引导的不确定性估计减轻噪声,并利用检索增强生成提升物体识别精度。
- 实验表明,RAG-3DSG显著提高了节点描述精度,同时大幅降低了跨图像物体聚合的映射时间。
📝 摘要(中文)
本文提出RAG-3DSG,旨在提升开放词汇3D场景图(3DSG)生成的质量。3DSG通过多视角图像构建,其中物体表示为节点,关系表示为边。现有方法在物体识别精度和速度上存在不足,主要原因是视角限制、遮挡和冗余表面密度。RAG-3DSG通过重拍引导的不确定性估计来减轻聚合噪声,并利用可靠的低不确定性物体支持物体级别的检索增强生成(RAG)。此外,提出了一种动态下采样映射策略,以自适应粒度加速跨图像物体聚合。在Replica数据集上的实验表明,RAG-3DSG显著提高了3DSG生成中的节点描述精度,同时将映射时间减少了三分之二。
🔬 方法详解
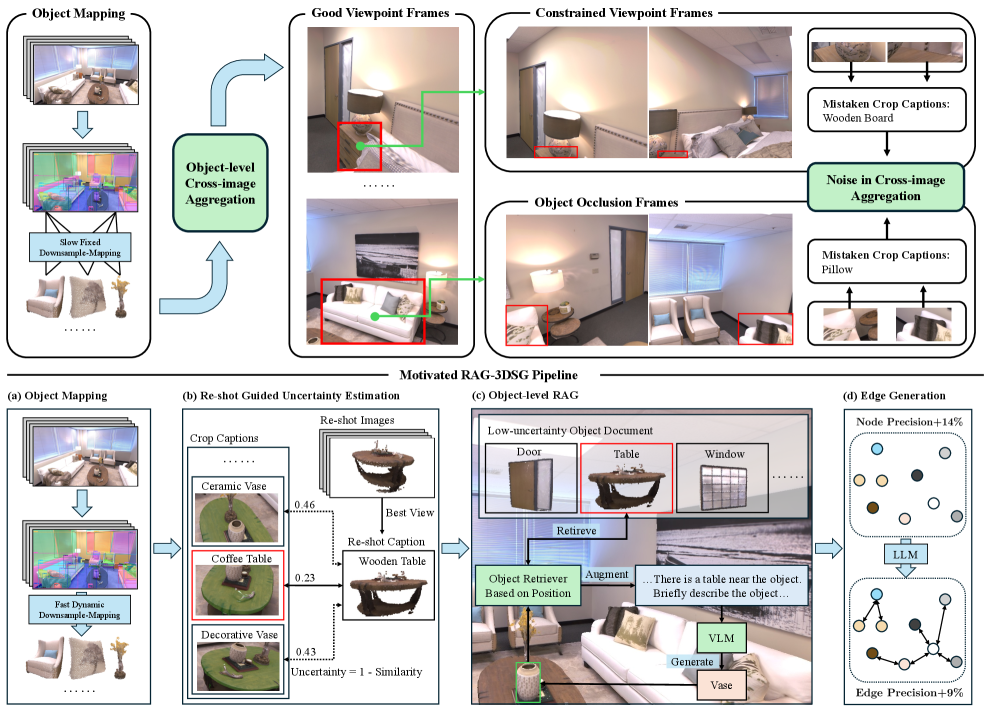
问题定义:现有开放词汇3D场景图生成方法在物体识别精度和速度上存在瓶颈。主要痛点在于:1) 受限于视角和遮挡,单一视角的图像信息不足以准确识别物体;2) 冗余的表面密度导致计算量大,影响生成速度;3) 跨图像的物体聚合过程容易引入噪声,降低场景图的质量。
核心思路:RAG-3DSG的核心思路是利用多视角图像的信息互补性,通过重拍引导的不确定性估计来筛选高质量的物体信息,并结合检索增强生成来提升物体识别的准确性。同时,采用动态下采样映射策略来加速跨图像物体聚合,提高生成效率。
技术框架:RAG-3DSG的整体框架包含以下几个主要模块:1) 多视角图像特征提取:从多个视角的图像中提取物体特征;2) 重拍引导的不确定性估计:基于多视角图像信息,估计每个物体的识别不确定性;3) 检索增强生成:利用低不确定性的物体信息,通过检索增强生成更准确的物体描述;4) 动态下采样映射:自适应地调整下采样粒度,加速跨图像物体聚合。
关键创新:RAG-3DSG的关键创新点在于:1) 提出了一种重拍引导的不确定性估计方法,能够有效筛选高质量的物体信息,降低聚合噪声;2) 引入了物体级别的检索增强生成,利用外部知识来提升物体识别的准确性;3) 设计了一种动态下采样映射策略,能够自适应地调整下采样粒度,加速跨图像物体聚合。与现有方法相比,RAG-3DSG能够更准确、更高效地生成高质量的3D场景图。
关键设计:在重拍引导的不确定性估计中,论文可能使用了例如方差、熵等指标来衡量物体识别的不确定性。检索增强生成模块可能采用了预训练的语言模型,并结合物体特征进行微调。动态下采样映射策略可能根据物体密度和特征相似度来调整下采样比例。具体的损失函数和网络结构等技术细节未知,需要查阅论文原文。
🖼️ 关键图片
📊 实验亮点
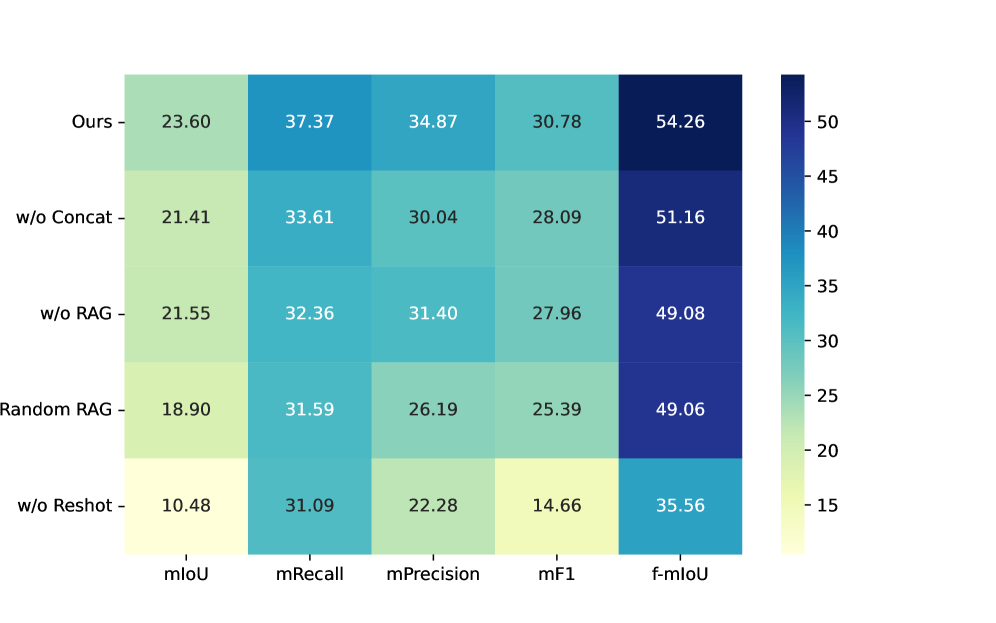
实验结果表明,RAG-3DSG在Replica数据集上显著提高了节点描述精度,具体提升幅度未知。同时,RAG-3DSG将跨图像物体聚合的映射时间减少了三分之二,表明其在效率方面具有显著优势。这些结果验证了RAG-3DSG在3D场景图生成方面的有效性和优越性。
🎯 应用场景
RAG-3DSG生成的3D场景图可应用于机器人操作、导航、场景理解等领域。例如,机器人可以利用场景图进行目标定位、路径规划和环境交互。该研究有助于提升机器人在复杂环境中的自主性和智能化水平,具有广阔的应用前景。
📄 摘要(原文)
Open-vocabulary 3D Scene Graph (3DSG) generation can enhance various downstream tasks in robotics, such as manipulation and navigation, by leveraging structured semantic representations. A 3DSG is constructed from multiple images of a scene, where objects are represented as nodes and relationships as edges. However, existing works for open-vocabulary 3DSG generation suffer from both low object-level recognition accuracy and speed, mainly due to constrained viewpoints, occlusions, and redundant surface density. To address these challenges, we propose RAG-3DSG to mitigate aggregation noise through re-shot guided uncertainty estimation and support object-level Retrieval-Augmented Generation (RAG) via reliable low-uncertainty objects. Furthermore, we propose a dynamic downsample-mapping strategy to accelerate cross-image object aggregation with adaptive granularity. Experiments on Replica dataset demonstrate that RAG-3DSG significantly improves node captioning accuracy in 3DSG generation while reducing the mapping time by two-thirds compared to the vanilla version.