Advancing Adaptive Multi-Stage Video Anomaly Reasoning: A Benchmark Dataset and Method
作者: Chao Huang, Benfeng Wang, Wei Wang, Jie Wen, Li Shen, Wenqi Ren, Yong Xu, Xiaochun Cao
分类: cs.CV
发布日期: 2026-01-15
💡 一句话要点
提出视频异常推理任务与数据集,并设计自适应多阶段推理模型Vad-R1-Plus
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频异常检测 多模态大语言模型 视频推理 链式思考 风险感知
📋 核心要点
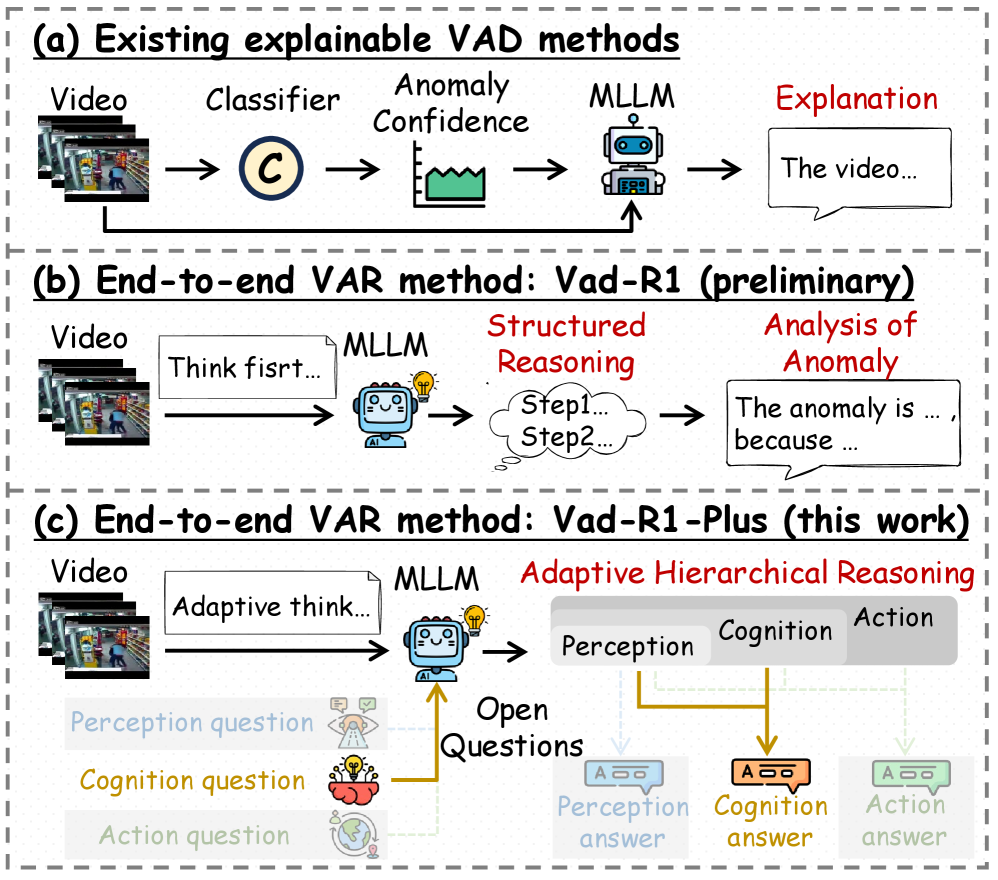
- 现有基于MLLM的视频异常检测方法缺乏明确的推理过程、风险意识和面向决策的解释。
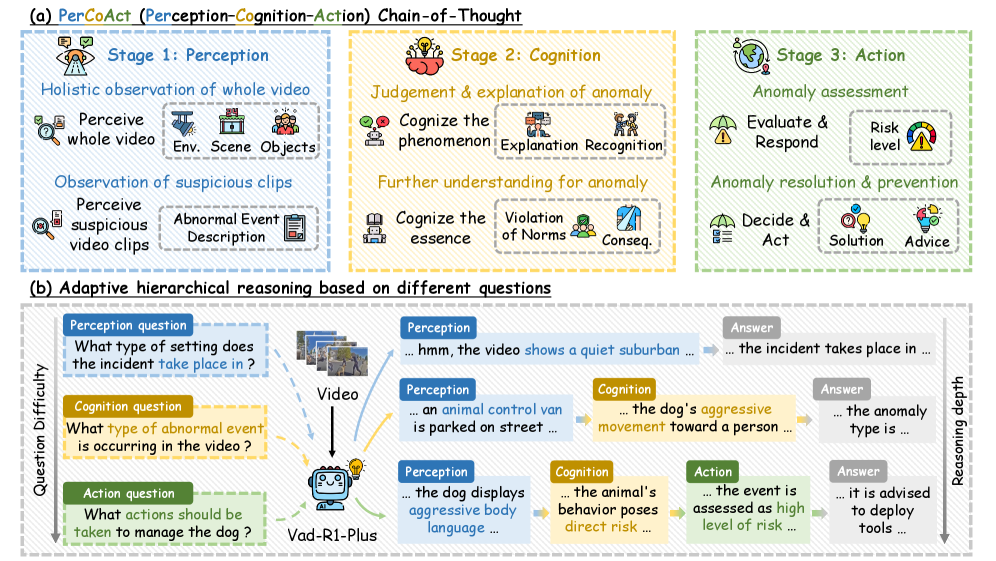
- 论文提出视频异常推理(VAR)任务,并构建大规模数据集,通过感知-认知-行动链式思考(PerCoAct-CoT)进行标注。
- 提出异常感知的群体相对策略优化方法,并构建端到端模型Vad-R1-Plus,实验证明有效提升了推理能力。
📝 摘要(中文)
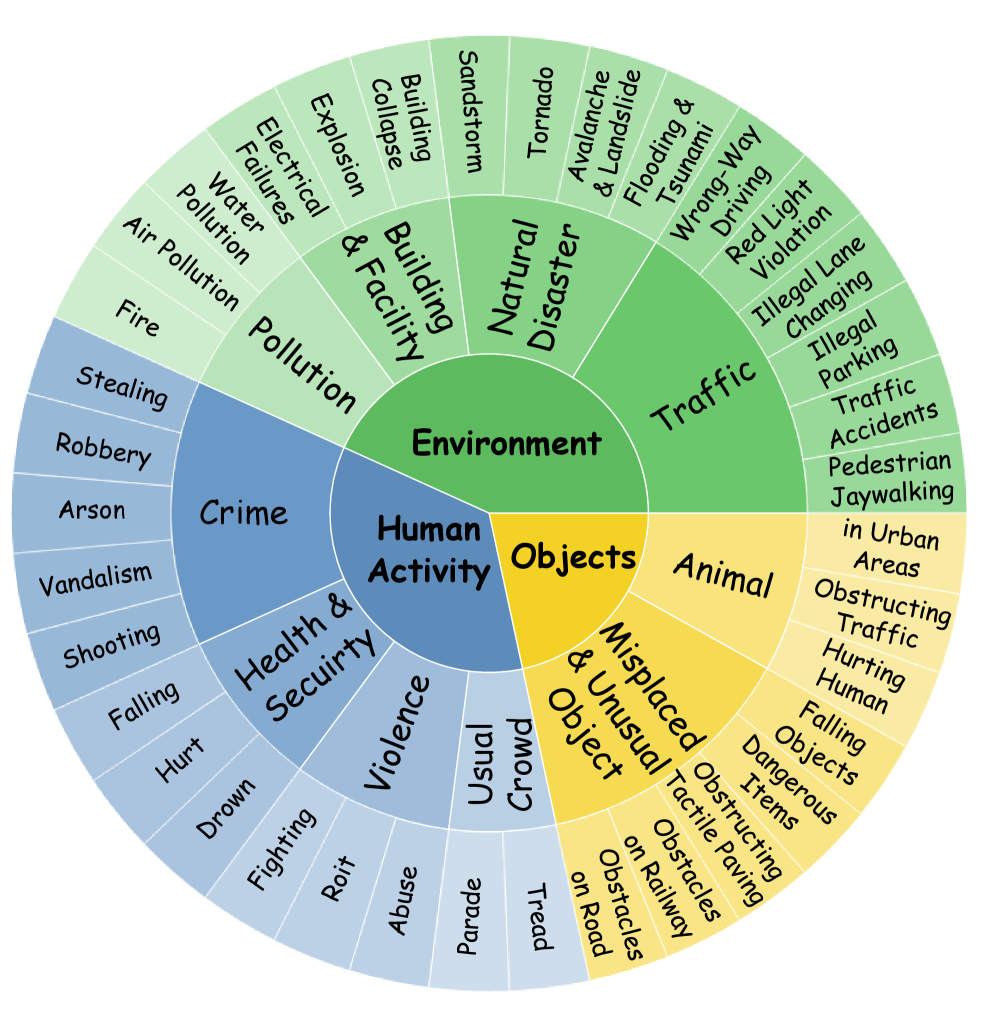
本文定义了一个新的任务:视频异常推理(VAR),旨在提升视频异常检测与理解(VAD&U)领域中,基于多模态大语言模型(MLLM)的方法在推理能力上的不足。现有方法主要局限于异常定位或事后描述,缺乏明确的推理过程、风险意识和面向决策的解释。为了支持VAR任务,作者构建了一个包含8641个视频的数据集,每个视频都标注了对应不同推理深度的多样化问题,总计超过50000个样本。标注基于结构化的感知-认知-行动链式思考(PerCoAct-CoT),形式化了视频异常理解的领域特定推理先验。此外,作者提出了一种异常感知的群体相对策略优化方法,以增强弱监督下的推理可靠性。基于提出的任务和数据集,开发了一个端到端的基于MLLM的VAR模型Vad-R1-Plus,支持自适应分层推理和风险感知决策。实验结果表明,提出的基准和方法有效地提升了MLLM在VAR任务上的推理能力,优于开源和专有基线。
🔬 方法详解
问题定义:现有基于多模态大语言模型(MLLM)的视频异常检测与理解方法,主要集中于异常定位或事后描述,缺乏对异常事件进行结构化、多阶段的推理能力,无法进行因果解释和风险感知决策。这些方法忽略了异常事件的复杂性和推理深度,限制了其在实际应用中的价值。
核心思路:论文的核心思路是将视频异常分析从描述性理解提升到结构化的多阶段推理。通过定义视频异常推理(VAR)任务,显式地要求模型在回答异常相关问题之前,对异常事件进行渐进式推理,包括视觉感知、因果解释和风险感知决策。这种设计旨在模拟人类专家在分析异常事件时的推理过程。
技术框架:整体框架包含数据收集与标注、模型构建和训练三个主要阶段。数据收集阶段构建了包含8641个视频的大规模数据集,并基于PerCoAct-CoT对视频进行标注,形成多阶段推理链。模型构建阶段提出了Vad-R1-Plus模型,该模型基于MLLM,支持自适应分层推理和风险感知决策。训练阶段则采用异常感知的群体相对策略优化方法,以增强弱监督下的推理可靠性。
关键创新:论文的关键创新在于提出了视频异常推理(VAR)任务,并构建了相应的基准数据集。VAR任务要求模型进行多阶段推理,包括视觉感知、因果解释和风险感知决策,这与现有方法仅关注异常定位或描述有本质区别。此外,PerCoAct-CoT标注方式和异常感知的群体相对策略优化方法也为VAR任务的有效解决提供了保障。
关键设计:PerCoAct-CoT标注方式将推理过程分解为感知(Perception)、认知(Cognition)和行动(Action)三个阶段,每个阶段都包含多个推理步骤。异常感知的群体相对策略优化方法则通过引入相对策略,鼓励模型学习更可靠的推理路径。Vad-R1-Plus模型采用自适应分层推理机制,根据问题的复杂程度动态调整推理深度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的Vad-R1-Plus模型在VAR任务上显著优于现有方法,包括开源和专有基线。具体而言,Vad-R1-Plus在多个推理深度的问题上都取得了更高的准确率,证明了其在多阶段推理方面的优势。此外,异常感知的群体相对策略优化方法也有效提升了模型的推理可靠性。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、工业安全等领域。通过提升视频异常事件的推理能力,可以更准确地识别潜在风险,并做出相应的决策,从而减少事故发生,提高安全性。未来,该技术还可扩展到其他需要复杂推理的视频理解任务中。
📄 摘要(原文)
Recent progress in reasoning capabilities of Multimodal Large Language Models(MLLMs) has highlighted their potential for performing complex video understanding tasks. However, in the domain of Video Anomaly Detection and Understanding (VAD&U), existing MLLM-based methods are largely limited to anomaly localization or post-hoc description, lacking explicit reasoning processes, risk awareness, and decision-oriented interpretation. To address this gap, we define a new task termed Video Anomaly Reasoning (VAR), which elevates video anomaly analysis from descriptive understanding to structured, multi-stage reasoning. VAR explicitly requires models to perform progressive reasoning over anomalous events before answering anomaly-related questions, encompassing visual perception, causal interpretation, and risk-aware decision making. To support this task, we present a new dataset with 8,641 videos, where each video is annotated with diverse question types corresponding to different reasoning depths, totaling more than 50,000 samples, making it one of the largest datasets for video anomaly. The annotations are based on a structured Perception-Cognition-Action Chain-of-Thought (PerCoAct-CoT), which formalizes domain-specific reasoning priors for video anomaly understanding. This design enables systematic evaluation of multi-stage and adaptive anomaly reasoning. In addition, we propose Anomaly-Aware Group Relative Policy Optimization to further enhance reasoning reliability under weak supervision. Building upon the proposed task and dataset, we develop an end-to-end MLLM-based VAR model termed Vad-R1-Plus, which supports adaptive hierarchical reasoning and risk-aware decision making. Extensive experiments demonstrate that the proposed benchmark and method effectively advance the reasoning capabilities of MLLMs on VAR tasks, outperforming both open-source and proprietary baselines.