FlowAct-R1: Towards Interactive Humanoid Video Generation
作者: Lizhen Wang, Yongming Zhu, Zhipeng Ge, Youwei Zheng, Longhao Zhang, Tianshu Hu, Shiyang Qin, Mingshuang Luo, Jiaxu Zhang, Xin Chen, Yulong Wang, Zerong Zheng, Jianwen Jiang, Chao Liang, Weifeng Chen, Xing Wang, Yuan Zhang, Mingyuan Gao
分类: cs.CV, cs.AI
发布日期: 2026-01-15
💡 一句话要点
FlowAct-R1:面向实时交互的人形视频生成框架,实现高保真和低延迟的平衡。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形视频生成 实时交互 扩散模型 MMDiT 分块扩散 自强制 知识蒸馏 时间一致性
📋 核心要点
- 现有视频合成方法难以兼顾高保真合成和实时交互需求,尤其是在人形视频生成领域。
- FlowAct-R1采用MMDiT架构,结合分块扩散强制和自强制策略,实现低延迟和长期时间一致性。
- 通过蒸馏和系统优化,FlowAct-R1在480p分辨率下达到25fps,首帧时间仅1.5秒,并具备良好的泛化性。
📝 摘要(中文)
本文提出FlowAct-R1,一个专为实时交互人形视频生成设计的框架。该框架基于MMDiT架构,能够以任意时长流式合成视频,同时保持低延迟响应。为了缓解误差累积并确保连续交互过程中的长期时间一致性,我们引入了一种分块扩散强制策略,并辅以一种新颖的自强制变体。通过高效的蒸馏和系统级优化,我们的框架在480p分辨率下实现了稳定的25fps,首帧时间(TTFF)仅为1.5秒左右。所提出的方法提供了全面而精细的全身控制,使代理能够在交互场景中自然地在不同的行为状态之间转换。实验结果表明,FlowAct-R1实现了卓越的行为生动性和感知真实感,同时保持了对不同角色风格的强大泛化能力。
🔬 方法详解
问题定义:现有的人形视频生成方法难以同时满足高保真度和实时交互的需求。具体来说,它们要么生成质量不高,要么延迟过高,无法实现流畅的实时交互体验。此外,长时间视频生成容易出现时间一致性问题,导致视频内容不稳定。
核心思路:FlowAct-R1的核心思路是利用扩散模型强大的生成能力,并通过一系列优化策略来降低延迟、提高帧率和保证时间一致性。通过分块处理和强制策略,模型能够在保证生成质量的同时,快速响应用户的交互指令。
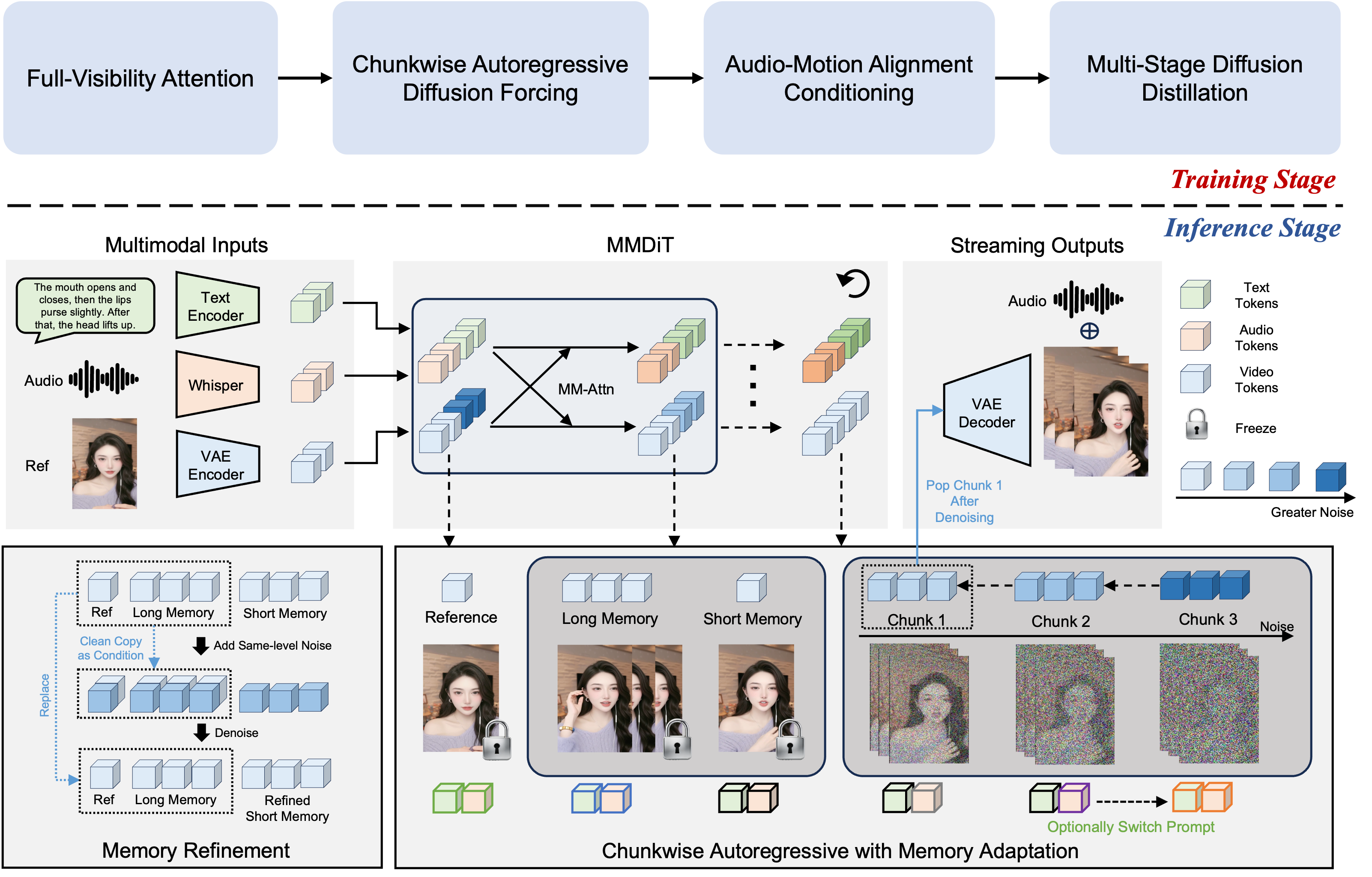
技术框架:FlowAct-R1基于MMDiT架构,采用流式生成方式,可以处理任意时长的视频。主要包含以下模块:1) MMDiT生成器:负责生成视频帧;2) 分块扩散强制模块:将视频分成小块进行处理,并强制模型生成与历史帧一致的内容;3) 自强制模块:进一步增强时间一致性;4) 蒸馏模块:用于加速推理过程。
关键创新:FlowAct-R1的关键创新在于分块扩散强制和自强制策略。分块扩散强制通过将视频分成小块处理,降低了计算复杂度,并允许模型在每个块内进行优化。自强制策略则通过约束当前帧与历史帧的一致性,有效地缓解了误差累积问题,保证了长时间视频的时间一致性。
关键设计:FlowAct-R1使用MMDiT作为生成器,并针对实时性进行了优化。分块大小的选择需要在计算复杂度和时间一致性之间进行权衡。扩散强制的强度也需要仔细调整,以避免过度约束导致生成质量下降。蒸馏过程采用知识蒸馏,将大型模型的知识迁移到小型模型,从而加速推理。
🖼️ 关键图片

📊 实验亮点
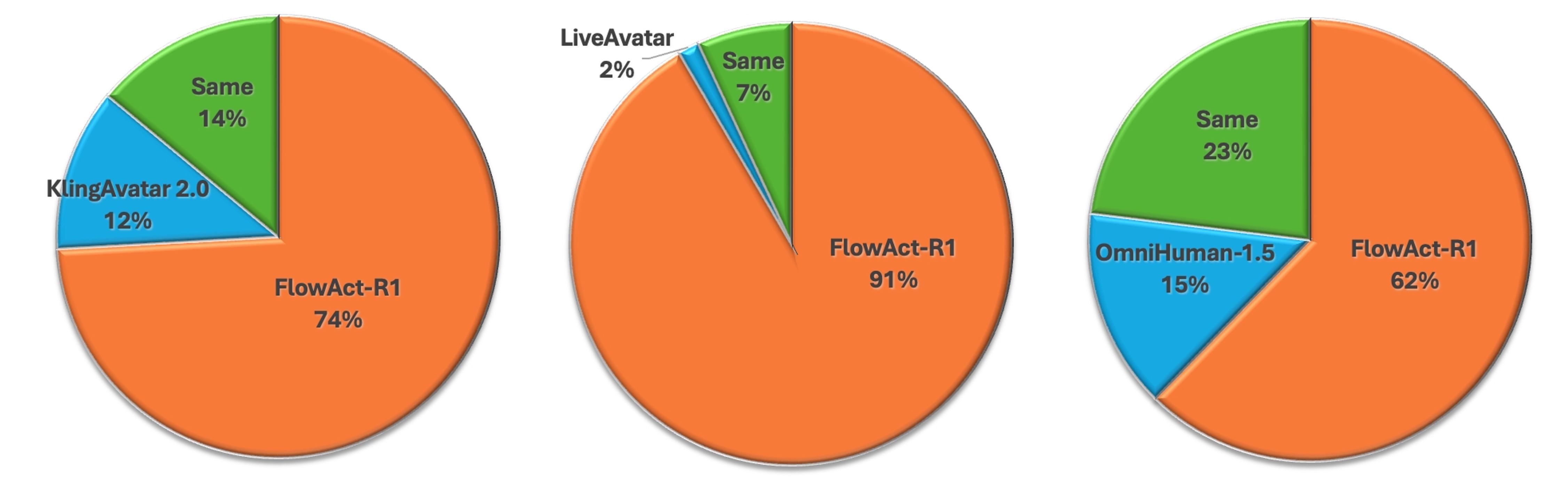
FlowAct-R1在480p分辨率下实现了稳定的25fps,首帧时间仅为1.5秒左右,显著优于现有的实时视频生成方法。实验结果表明,FlowAct-R1生成的视频具有卓越的行为生动性和感知真实感,并且能够很好地泛化到不同的角色风格。与基线方法相比,FlowAct-R1在时间一致性方面也有显著提升。
🎯 应用场景
FlowAct-R1在虚拟助手、在线教育、游戏、社交娱乐等领域具有广泛的应用前景。它可以用于创建逼真的虚拟化身,与用户进行实时互动,提供个性化的服务和体验。此外,该技术还可以应用于电影制作、广告创意等领域,生成高质量的数字内容。
📄 摘要(原文)
Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.