V-Zero: Self-Improving Multimodal Reasoning with Zero Annotation
作者: Han Wang, Yi Yang, Jingyuan Hu, Minfeng Zhu, Wei Chen
分类: cs.CV, cs.AI, cs.LG
发布日期: 2026-01-15
🔗 代码/项目: GITHUB
💡 一句话要点
V-Zero:一种基于无标注数据的多模态自提升推理框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 自监督学习 视觉语言模型 协同进化 无标注数据
📋 核心要点
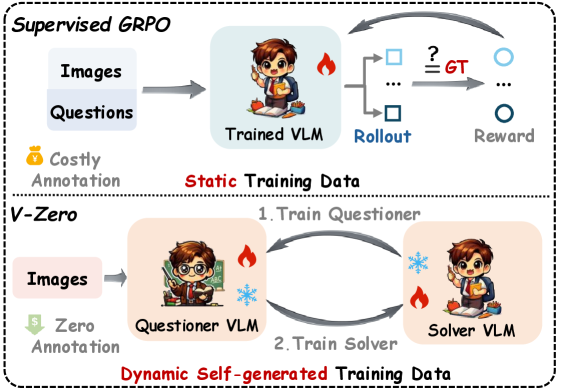
- 现有视觉语言模型依赖大量人工标注数据,成本高昂且耗时,限制了其应用。
- V-Zero框架通过提问者和解答者的协同进化,利用无标注数据实现模型自提升。
- 实验表明,V-Zero在无人工标注情况下,显著提升了视觉数学推理和通用视觉任务的性能。
📝 摘要(中文)
本文提出V-Zero,一个通用的后训练框架,它仅使用未标注的图像来实现自我提升,从而克服了现有方法对大规模人工标注数据集的依赖。V-Zero通过实例化两个不同的角色:提问者和解答者,建立了一个协同进化的循环。提问者通过利用双轨推理奖励来学习合成高质量、具有挑战性的问题,该奖励对比了直觉猜测和推理结果。解答者通过对其自身采样响应进行多数投票获得的伪标签进行优化。这两个角色通过群体相对策略优化(GRPO)进行迭代训练,从而驱动相互增强的循环。值得注意的是,在没有任何人工标注的情况下,V-Zero在Qwen2.5-VL-7B-Instruct上实现了持续的性能提升,在视觉数学推理方面提高了+1.7,在以视觉为中心的通用任务方面提高了+2.6,证明了多模态系统中自我提升的潜力。
🔬 方法详解
问题定义:现有最先进的多模态学习方法严重依赖于大规模的人工标注数据集,获取这些数据集既昂贵又耗时。这限制了这些方法的可扩展性和在数据稀缺场景中的应用。因此,需要一种能够在没有人工标注的情况下提升视觉语言模型推理能力的方法。
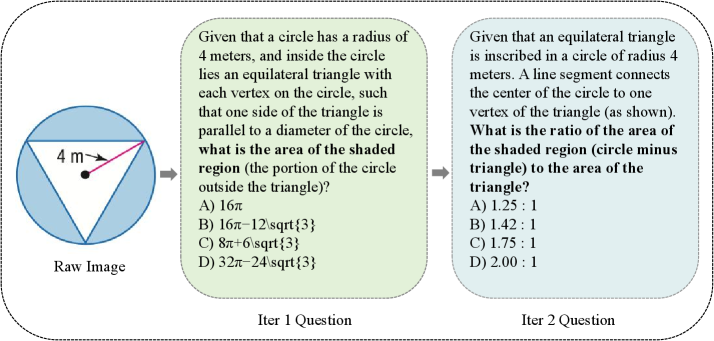
核心思路:V-Zero的核心思路是构建一个提问者-解答者的协同进化循环。提问者负责生成高质量、有挑战性的问题,而解答者负责回答这些问题。通过迭代训练,提问者不断提高问题质量,解答者不断提升解答能力,从而实现模型的自我提升。这种设计的灵感来源于人类的学习过程,即通过不断提问和解答来加深理解。
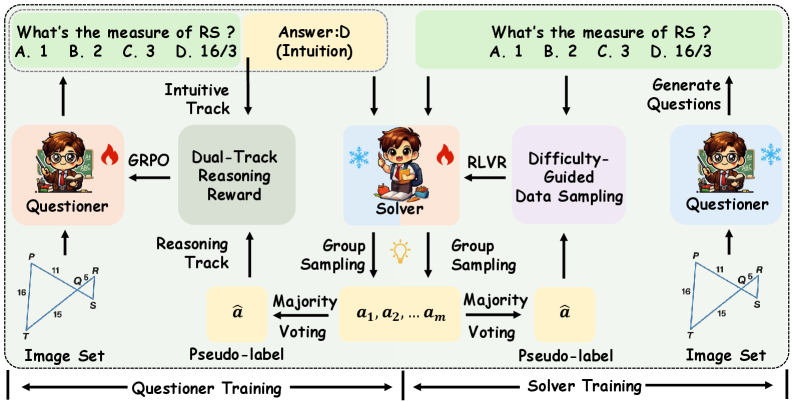
技术框架:V-Zero框架包含两个主要模块:提问者和解答者。提问者负责根据输入的图像生成问题,解答者负责根据图像和问题生成答案。这两个模块通过群体相对策略优化(GRPO)进行迭代训练。具体流程如下:1) 提问者生成问题;2) 解答者根据问题和图像生成多个答案;3) 对解答者的答案进行多数投票,生成伪标签;4) 使用伪标签训练解答者;5) 使用双轨推理奖励训练提问者,该奖励对比了直觉猜测和推理结果。
关键创新:V-Zero的关键创新在于其无监督的自提升学习方法。与传统的监督学习方法不同,V-Zero不需要任何人工标注数据。此外,V-Zero提出的双轨推理奖励能够有效地引导提问者生成高质量、有挑战性的问题。这种方法能够充分利用未标注数据,从而提升模型的推理能力。
关键设计:V-Zero使用群体相对策略优化(GRPO)来训练提问者和解答者。GRPO是一种强化学习算法,它能够有效地处理多智能体环境。在训练提问者时,V-Zero使用双轨推理奖励,该奖励由两部分组成:直觉猜测奖励和推理奖励。直觉猜测奖励鼓励提问者生成能够快速给出直觉答案的问题,而推理奖励鼓励提问者生成需要进行深入推理才能回答的问题。通过平衡这两个奖励,V-Zero能够生成高质量、有挑战性的问题。
🖼️ 关键图片
📊 实验亮点
V-Zero在Qwen2.5-VL-7B-Instruct上进行了实验,结果表明,在没有任何人工标注的情况下,V-Zero在视觉数学推理方面提高了+1.7,在以视觉为中心的通用任务方面提高了+2.6。这些结果表明,V-Zero能够有效地提升视觉语言模型的推理能力,并且具有很强的泛化能力。
🎯 应用场景
V-Zero具有广泛的应用前景,例如可以应用于智能问答系统、视觉导航、机器人控制等领域。该研究成果能够降低多模态学习对人工标注数据的依赖,从而加速相关技术的发展和应用。未来,V-Zero有望应用于更多领域,例如医疗诊断、自动驾驶等。
📄 摘要(原文)
Recent advances in multimodal learning have significantly enhanced the reasoning capabilities of vision-language models (VLMs). However, state-of-the-art approaches rely heavily on large-scale human-annotated datasets, which are costly and time-consuming to acquire. To overcome this limitation, we introduce V-Zero, a general post-training framework that facilitates self-improvement using exclusively unlabeled images. V-Zero establishes a co-evolutionary loop by instantiating two distinct roles: a Questioner and a Solver. The Questioner learns to synthesize high-quality, challenging questions by leveraging a dual-track reasoning reward that contrasts intuitive guesses with reasoned results. The Solver is optimized using pseudo-labels derived from majority voting over its own sampled responses. Both roles are trained iteratively via Group Relative Policy Optimization (GRPO), driving a cycle of mutual enhancement. Remarkably, without a single human annotation, V-Zero achieves consistent performance gains on Qwen2.5-VL-7B-Instruct, improving visual mathematical reasoning by +1.7 and general vision-centric by +2.6, demonstrating the potential of self-improvement in multimodal systems. Code is available at https://github.com/SatonoDia/V-Zero